- The paper demonstrates that OCR-based RAG systems achieve higher retrieval accuracy and semantic quality compared to vision-based pipelines.
- It introduces the DocDeg dataset with realistic document degradation levels and uses metrics like MRR, Recall@5, and NDCG@5 for evaluation.
- The study highlights a trade-off between the computational efficiency of vision-based methods and the precision of OCR approaches in processing degraded documents.
"Lost in OCR Translation? Vision-Based Approaches to Robust Document Retrieval" (2505.05666)
Introduction
The research paper presents a comparative study of two paradigms in Retrieval-Augmented Generation (RAG) systems: Optical Character Recognition (OCR)-based and Vision-LLM (VLM)-based approaches. The primary focus is on assessing the efficacy of these systems in processing real-world documents of varying quality. The RAG framework aims to alleviate the limitations of LLMs by grounding responses in external documents during inference, thus addressing issues such as hallucinations.
Methodology
The study evaluates two RAG system architectures:
- VLM-Based RAG Pipeline: Utilizes ColPali architecture for direct document image embedding, bypassing traditional OCR text processing. It generates embeddings for document image patches, which are later used for retrieval against query embeddings.
- OCR-Based RAG Pipeline: Employs advanced OCR systems like Nougat and Llama 3.2 to convert documents into textual embeddings, which are then used for retrieval.
The experiments employ a novel semantic answer evaluation benchmark alongside traditional retrieval metrics to assess system performance across multiple document degradation levels, reflecting real-world deployment scenarios (Figure 1).
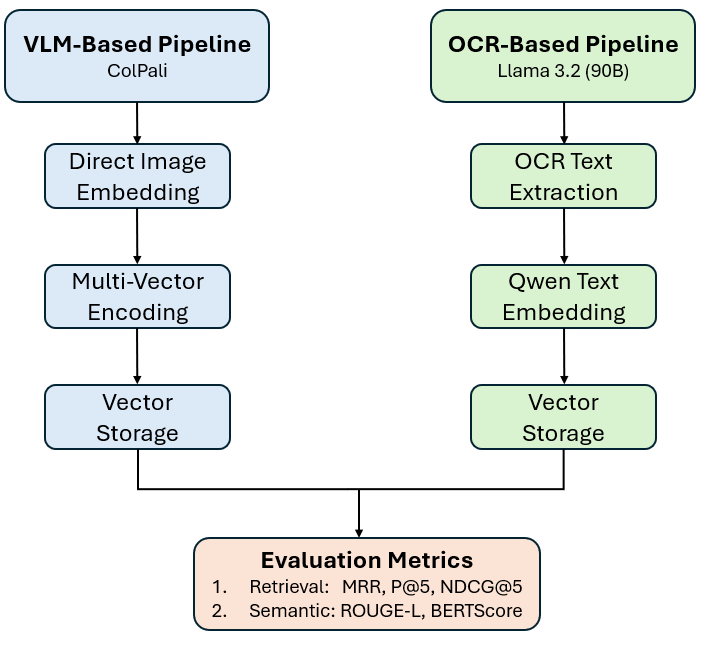
Figure 1: Overview of the experimental pipeline comparing VLM-based and OCR-based RAG systems.
Experimental Setup
DocDeg Dataset
The authors introduce DocDeg, a dataset tailored to evaluate document retrieval systems under realistic conditions. Documents in this dataset are categorized into four levels of degradation, ranging from pristine digital to severely degraded scans. Each document is manually annotated with structural and content features, making it suitable for rigorous evaluation.
Evaluation Metrics
The study employs Mean Reciprocal Rank (MRR), Recall@5, and Normalized Discounted Cumulative Gain (NDCG@5) for retrieval evaluation. It also introduces semantic metrics like Exact Match, BLEU, and ROUGE scores to assess the end-to-end question-answering ability.
Results and Discussion
The OCR-based systems, particularly when using the Llama 3.2 model, demonstrated superior retrieval accuracy across all document quality levels compared to the VLM-based system. The Llama 3.2 OCR significantly outperformed the Nougat OCR and ColPali on degraded documents (Figure 2).
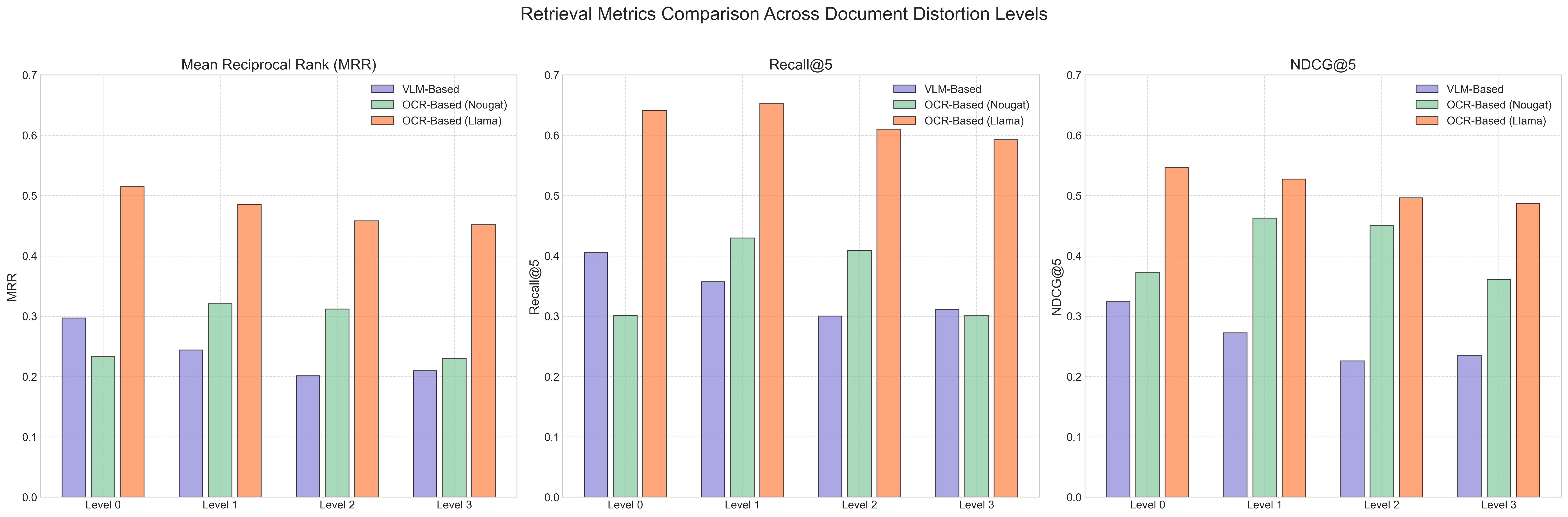
Figure 3: Retrieval performance across document quality levels.
Semantic Answer Accuracy
OCR-based pipelines also yielded better semantic answer quality, as evidenced by higher scores in Exact Match, BLEU, and ROUGE metrics. This suggests that despite VLM models' ability to process visual document nuances, OCR systems maintained an edge in precision and robustness.
Computational Efficiency
The VLM-based pipeline showed efficiencies in computational resources, offering advantages in embedding generation time and memory consumption. However, this came at the expense of reduced retrieval and semantic accuracy.
Conclusion
The study indicates a trade-off between computational efficiency and retrieval accuracy in choosing between VLM-based and OCR-based RAG systems. While OCR-based approaches offer superior performance in terms of precision and semantic quality, they require greater computational overhead. In practical applications involving visually imperfect documents, the decision between these systems would depend on the specific requirements for accuracy versus resource utilization. Future directions include exploring fine-tuning of both paradigms and integrating vision-language QA models for enhanced performance. The comparative analysis underscores the importance of selecting appropriate models based on document conditions and task demands (Figure 4).
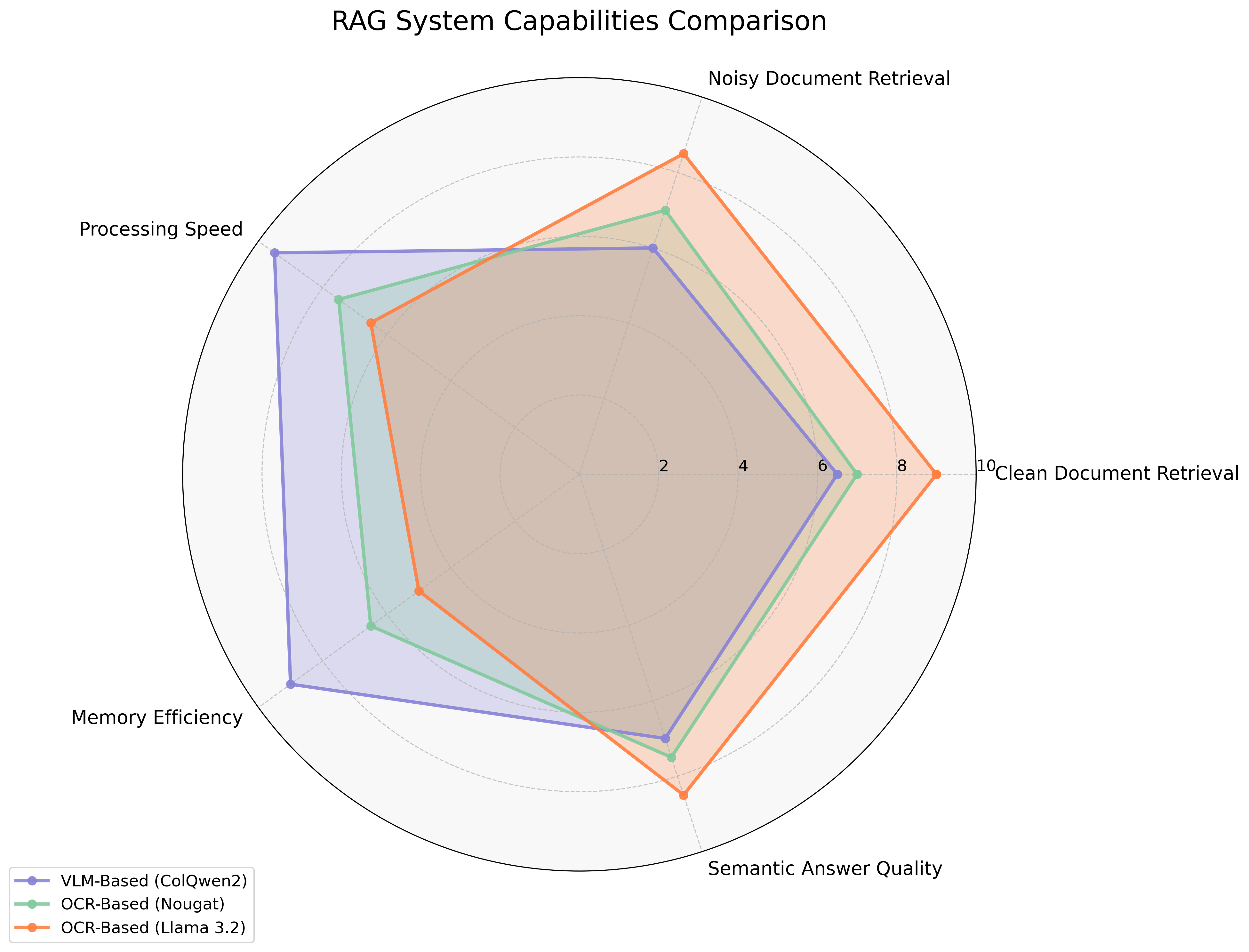
Figure 4: Comparative Analysis of RAG System Capabilities.

