- The paper introduces ArchRAG, a novel framework that integrates attributed communities into a hierarchical graph, achieving up to 250-fold token savings and a 10% accuracy increase.
- It employs a two-phase methodology with offline indexing to construct a knowledge graph using iterative clustering and a C-HNSW index for fast, layered search.
- The system's adaptive filtering and hierarchical search demonstrate significant potential for scalable, real-time retrieval in complex multi-hop question answering tasks.
ArchRAG introduces a novel method to enhance Retrieval-Augmented Generation (RAG) for LLMs by leveraging graph-based structures to integrate external domain-specific knowledge. The approach builds on traditional graph RAG by utilizing attributed communities for more efficient and accurate information retrieval from a hierarchical index structure. This multifaceted system has shown to outperform existing models in both accuracy and token efficiency, marking significant advancements in the application of RAG methodologies.
Introduction to ArchRAG
Retrieval-Augmented Generation (RAG) enhances LLMs by incorporating external knowledge bases, offering improvements in domains demanding high reasoning capabilities and detailed factual data. The proposed ArchRAG model targets limitations in existing graph-based RAG systems by presenting a hierarchical structure capable of efficiently indexing and retrieving attributed communities and entities in response to specific and abstract queries.
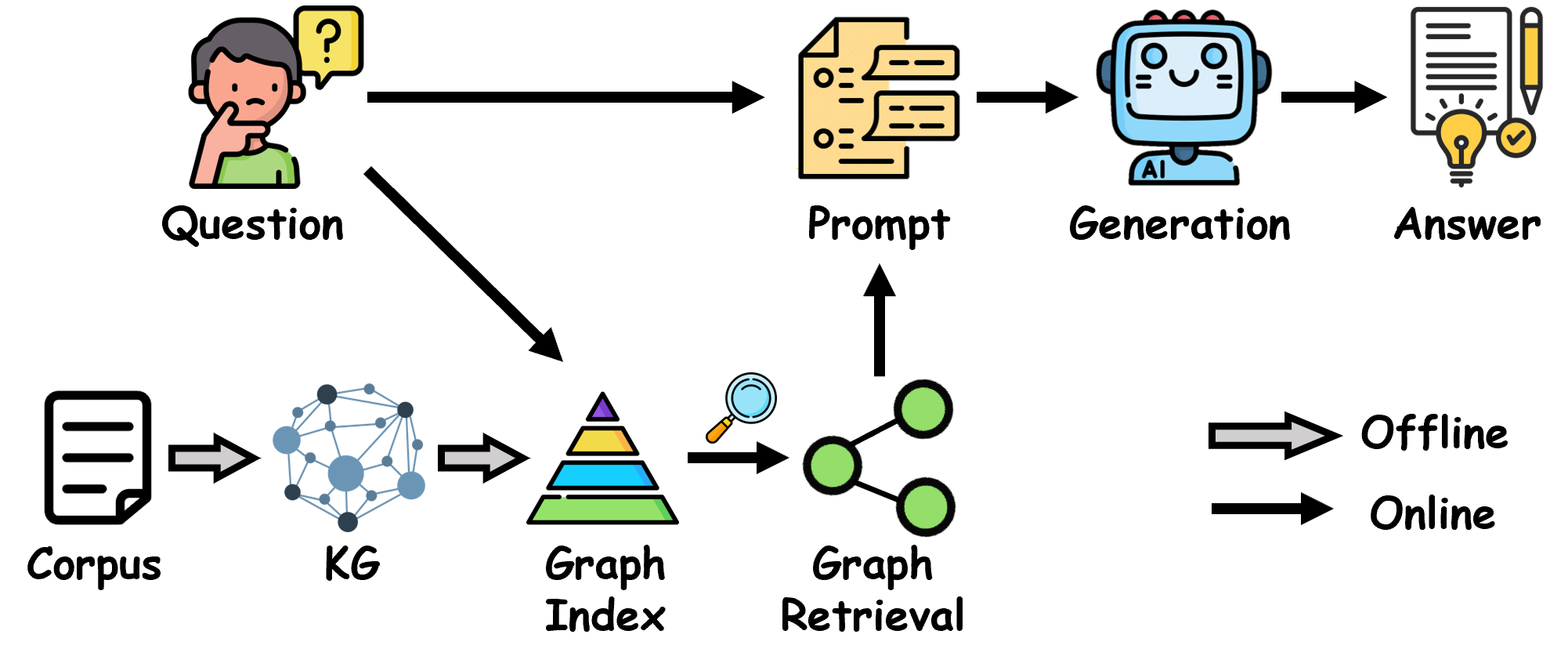
Figure 1: The general workflow of graph-based RAG, which retrieves relevant information (e.g., nodes, subgraphs, or textual information) to facilitate the LLM generation.
System Design and Implementation
ArchRAG consists of two primary phases: offline indexing and online retrieval. During offline indexing, attributed communities are detected using both structural links and node attributes, which are then organized into a hierarchical tree structure. On top of this structure, the Community-based Hierarchical Navigable Small World (C-HNSW) index is built to facilitate fast retrieval.
Offline Indexing
Knowledge Graph Construction
ArchRAG commences with building a Knowledge Graph (KG) from a corpus using an LLM to extract entities and relations, generating a comprehensive graph representation of the underlying data.
Hierarchical Clustering
To detect high-quality attributed communities (ACs), ArchRAG employs an iterative LLM-based hierarchical clustering framework, incorporating graph augmentation techniques and clustering algorithms to ensure dense connectivity and thematic similarity among communities.
C-HNSW Index Construction
The C-HNSW index maps entities and ACs into high-dimensional nodes, establishing efficient intra-layer and inter-layer links for seamless multi-layer searching, thus supporting the hierarchical retrieval of relevant data for the posed queries using a LLM.
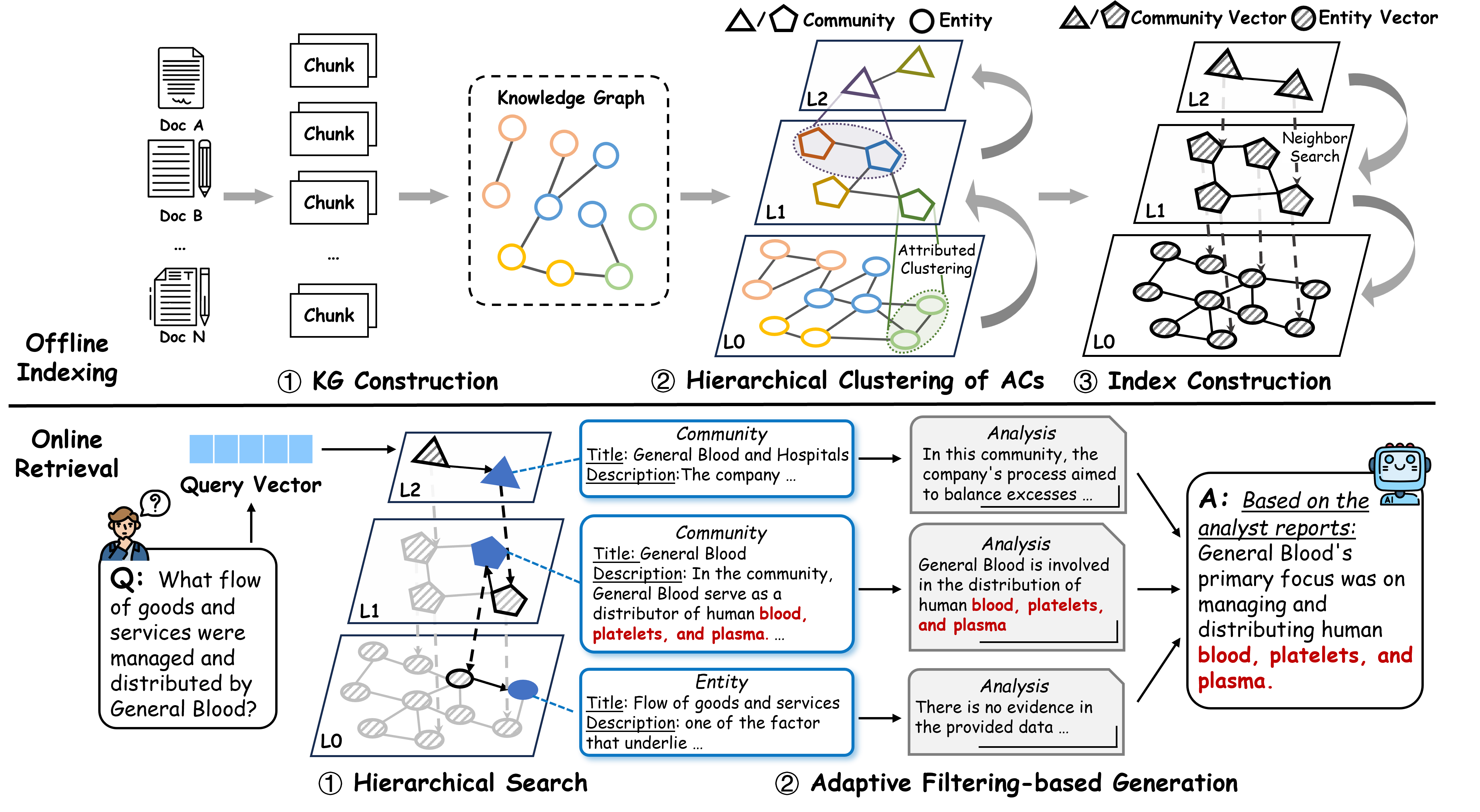
Figure 2: ArchRAG consists of two phases: offline indexing and online retrieval. For the online retrieval phase, we show an example of using ArchRAG to answer a question in the HotpotQA dataset.
Online Retrieval
Hierarchical Search
ArchRAG uses a hierarchical search algorithm to query the C-HNSW index efficiently. This method reuses intermediate retrieval results from upper layers as starting points for lower layers, drastically reducing the time complexity and computational cost associated with multi-layer graph traversals.
Adaptive Filtering-based Generation
To address issues of lost information within long inputs, ArchRAG implements an adaptive filtering method where the LLM assigns relevance scores to retrieved information, sorting and presenting the most pertinent data in response to user queries.
Experimental Evaluation
Experiments on datasets such as Multihop-RAG, HotpotQA, and NarrativeQA demonstrate ArchRAG's superior performance in both abstract and specific QA tasks. Notably, ArchRAG achieves up to 250-fold savings in token usage while delivering a 10% higher accuracy compared to state-of-the-art graph RAG systems. These results underscore the system's efficiency in response generation, even within complex multi-hop question answering frameworks.
Implications and Future Work
The development of ArchRAG marks a substantive advancement in retrieval-augmented generation systems, introducing a scalable approach with real-time indexing and retrieval efficacy. Future research may explore extending ArchRAG's adaptable framework to parallel processing environments, enabling deeper integration with large-scale data repositories and enhancing its applicability across diverse AI-driven domains.
Conclusion
ArchRAG represents a significant enhancement over traditional graph-based RAG approaches by integrating hierarchical community attributions into the retrieval and augmentation process. Leveraging community structure for better thematic insight and retrieval efficiency, ArchRAG paves the way for more resourceful application designs, demonstrating exceptional performance gains in experimental evaluations across varied QA tasks. This advancement positions ArchRAG as a formidable tool in the pursuit of optimized LLM augmentation techniques.

