- The paper demonstrates HACK's main contribution is eliminating dequantization overhead by computing directly on quantized KV data during LLM inference.
- It employs an asymmetric 2-bit stochastic quantization with partitioning to reduce communication delays, achieving up to 70.9% reduction in job completion time.
- The method integrates with FlashAttention-2 and open-source frameworks to reduce memory usage by up to 33.6%, enhancing inference efficiency.
"HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference" (2502.03589)
Abstract and Motivation
The paper presents HACK, a method aimed at improving the efficiency of disaggregated LLM inference. Traditionally, disaggregated inference separates the computation-heavy prefill stage and the memory-heavy decode stage, potentially causing bottlenecks in KV transmission due to the increased communication overhead associated with long prompts. Existing quantization methods help alleviate these bottlenecks but introduce significant dequantization overhead.
As observed, communication can consume up to 42.2% of the total job completion time (JCT), making it imperative to optimize this process. The key motivation behind HACK is to eliminate the dequantization overhead by operating directly on quantized KV data, thus enabling faster and more efficient matrix multiplication during inference.
Homomorphic Quantization Method
HACK leverages homomorphic quantization principles to facilitate computation directly on quantized KV data. This involves using an asymmetric 2-bit stochastic quantization to reduce quantization error, partitioning matrix elements into segments called partitions to apply a complex quantization system without needing intensive dequantization later.
Practical Application
The homomorphic scheme incorporates a specialized method to approximate true matrix multiplication results (Equation [3]), allowing computations using low-precision data without dequantization. This reduces KV data transmission latency, computation time during inference, and memory demand, effectively mitigating the primary bottleneck—network overhead in disaggregated LLM inference.
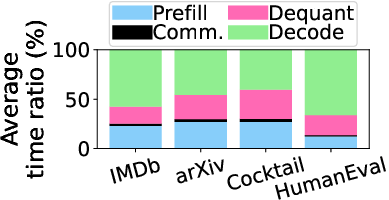
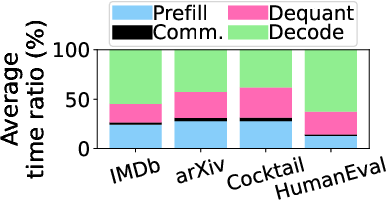
Figure 1: Employing KV quantization across datasets.
Implementation Details
HACK integrates with FlashAttention-2, a memory-efficient attention kernel, modified to employ OpenAI's Triton for executing fused kernels optimized for attention computation during inference. These kernels enable computation using INT8 format to achieve considerable speed-ups.
Kernel Fusion and Data Management
Kernel fusion employed in HACK ensures efficient computation by combining quantization, matrix multiplication, and other operations into singular, streamlined processes, also accommodating the management of quantized KV data structures within the existing vLLM framework.
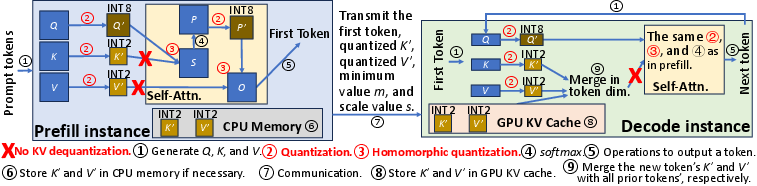
Figure 2: Overview of HACK in disaggregated LLM inference.
End-to-End Time and Scaling
Experiments reveal that HACK can reduce the average JCT by up to 70.9% compared to both baseline disaggregated methods and state-of-the-art KV quantization strategies, demonstrating substantial improvements across different models and datasets.
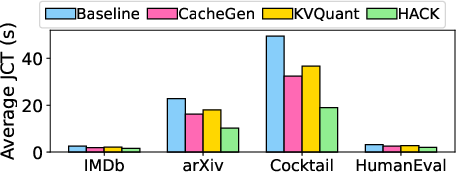
Figure 3: Average JCT across requests for Llama-3.1 70B with varying datasets.
Memory Efficiency
Peak memory usage is reduced by up to 33.6% in long-sequence datasets, showing that HACK effectively manages memory more efficiently than existing quantization techniques, largely due to eliminating unnecessary recomputation and increasing computational accuracy.
Comparison to Existing Methods
HACK is distinguished from other solutions like CacheGen and KVQuant primarily due to its unique handling of quantized data without incurring heavy dequantization costs. While FP4/6/8 methods provide hardware-based acceleration, they fall short in compressing KV size to comparably efficient levels.
Limitations and Future Work
HACK's focus on severe quantization for transmission efficiency reduces accuracy marginally, providing potential for further exploration into lower-bit quantization schemes that might balance accuracy with latency improvements. Additionally, TurboAttention's symmetric quantization presents an interesting comparison in terms of error rates and overhead.
Scalability
Future work could explore integrating CUDA implementations directly to leverage INT4 computations for further performance gains beyond Triton's current INT8 support.
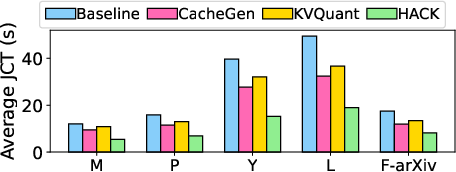
Figure 4: Average JCT across requests for different models with Cocktail or arXiv.
Conclusion
Overall, HACK presents a compelling approach to handling disaggregated LLM inference, offering significant reductions in latency and computational overhead through innovative uses of homomorphic quantization. It highlights potential directions for future enhancements in performance and implementation strategies for large-scale models.
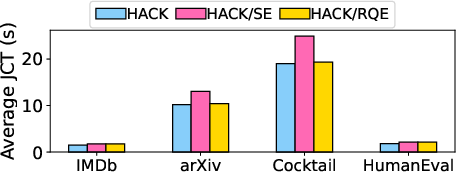
Figure 5: Average JCT across requests for individual methods with Llama-3.1 70B.
As LLMs continue to grow in size and complexity, methods like HACK will be instrumental in enabling cost-effective inference at scale with the robust computational capabilities provided by direct quantized data manipulation.