- The paper introduces VecInfer, which suppresses key cache outliers using smooth and Hadamard transformations to enable effective low-bit KV cache compression.
- It integrates an offline-trained vector quantization method that achieves up to 2.7× speedup and an 8.3× reduction in latency during large-batch self-attention.
- The optimized fused CUDA kernel minimizes memory overhead by combining computation and dequantization, enhancing performance in long-context LLMs.
VecInfer: Efficient LLM Inference with Low-Bit KV Cache via Outlier-Suppressed Vector Quantization
Introduction
The paper "VecInfer: Efficient LLM Inference with Low-Bit KV Cache via Outlier-Suppressed Vector Quantization" introduces a novel vector quantization (VQ) method known as VecInfer, specifically designed to enhance the efficiency of LLM inference by compressing the key-value (KV) cache without significant performance degradation. The primary challenge addressed by VecInfer is the high memory overhead associated with KV caches during LLM inference, particularly when operating at ultra-low bit-widths. Existing VQ methods suffer from reduced performance due to key cache outliers, which inhibit effective codebook utilization.
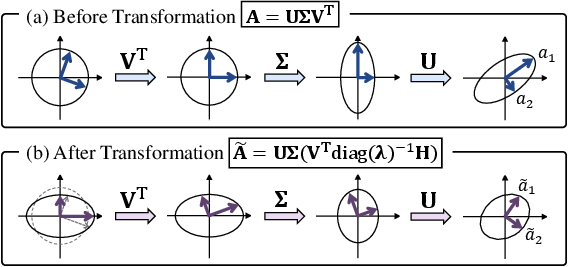
VecInfer addresses these challenges by applying smooth and Hadamard transformations to suppress key cache outliers, thereby facilitating a more comprehensive coverage by the codebook. This paper further optimizes inference by deploying a customized CUDA kernel that fuses computation and dequantization to reduce memory access overhead.
Methodology
VecInfer employs dual transformations to refine the distribution of the key cache, thereby minimizing the impact of outliers:
- Smooth Transformation: This involves channel-wise scaling of the key and an inverse scaling of the query to maintain computational equivalence across queries and keys.
- Hadamard Transformation: An orthogonal transformation using a Hadamard matrix further redistributes the data, effectively normalizing the outlier impact.
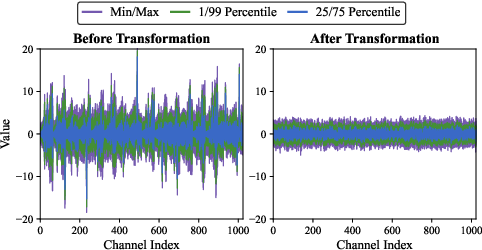
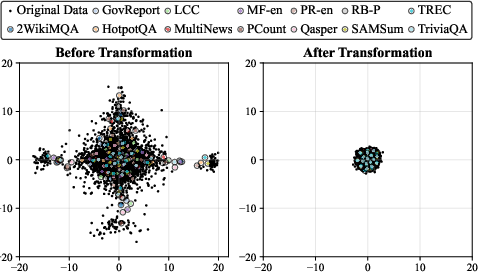
Figure 1: Channel-wise distribution of the key cache.
These transformations collectively facilitate the transformation of the key cache into a format that is more amenable to quantization, reducing the difficulty and increasing the efficiency of this process.
Vector Quantization
Post-transformation, VecInfer employs a VQ technique that maps the transformed key vectors to a predefined codebook, which is trained offline using K-Means clustering. By partitioning high-dimensional vectors into sub-vectors and encoding them using a limited bit-width, VecInfer effectively compresses the KV cache. The two-stage process involves:
- Prefilling: Applying transformations and quantizing keys and values using the pre-trained codebooks.
- Decoding: Online transformation of incoming keys and their concatenation with existing quantized entries.
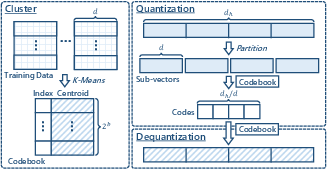
Figure 2: Typical vector quantization pipeline.
This method significantly reduces memory requirements without compromising the integrity of the data, supporting efficient large-batch self-attention computation.
Hardware Optimization
VecInfer implements a fused dequantization-computation CUDA kernel, which enhances computational efficiency through:
These optimizations ensure that VecInfer achieves superior performance metrics compared to existing methodologies.
The evaluations of VecInfer demonstrate its superiority over existing quantization methods, especially in scenarios involving long-context understanding and mathematical reasoning tasks. The study reveals that VecInfer can achieve up to a 2.7× speedup in large-batch self-attention computations and an 8.3× reduction in single-batch latency using a 2-bit KV cache, while maintaining the performance level comparable to full precision.
Additionally, the architecture's ability to maintain high accuracy at reduced bit-widths suggests that it is particularly effective for models with extensive sequence lengths, like Llama-3.1-8B, which leverage 196k sequence lengths.
Conclusion
VecInfer represents a significant advancement in LLM inference by providing a robust framework for KV cache compression at ultra-low bit-widths without sacrificing performance. Its dual transformation approach is effective in suppressing outliers, and its optimized CUDA kernel ensures efficient deployment on GPU hardware. These innovations collectively offer a compelling solution for deploying LLMs in environments constrained by memory and compute resources, broadening the potential applications of such models.
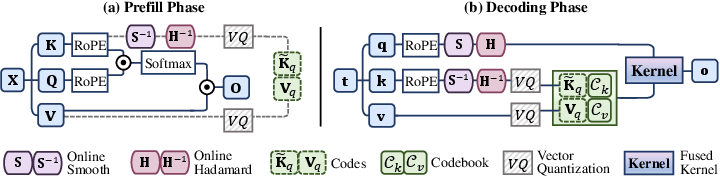
Figure 4: Kernel performance on H100 (80GB). Additional results are provided in Figure 5.
In summary, VecInfer's approach sets a new standard for efficient LLM inference, and its methodologies could potentially be adapted for other types of model compression and optimization tasks within the field of AI.