- The paper introduces KV cache transform coding, achieving up to 20x compression while preserving LLM reasoning capabilities.
- It employs PCA-based feature decorrelation, adaptive quantization, and DEFLATE entropy coding to efficiently compress hidden activations.
- Experimental results on models like Llama and Mistral demonstrate improved inference efficiency and lower operational costs.
This paper addresses efficient key-value (KV) cache management critical for deploying LLMs at scale. It introduces a transform coding scheme, \Method{}, crafted to compress KV caches, an essential component for maintaining efficient memory and compute usage during inference.
Motivation and Problem Statement
LLMs often utilize KV caches to store hidden activations that allow faster responses in conversational AI by reusing the cached data across multiple conversation turns. However, as these caches grow, they consume substantial GPU memory, creating a bottleneck for scalability. Traditional solutions, such as token eviction or offloading cache to slower storage, incur recomputation costs or latency penalties.
Methodology
\Method{} leverages principles from classical media compression, integrating feature decorrelation, adaptive quantization, and entropy coding:
- Feature Decorrelation: This uses PCA to linearly decorrelate the cache features, capturing the inherent low-rank structure present within KV tensors. The PCA basis is precomputed using a calibration dataset to align features from different heads and layers, as visualized by their cosine similarity before and after alignment (Figure 1).
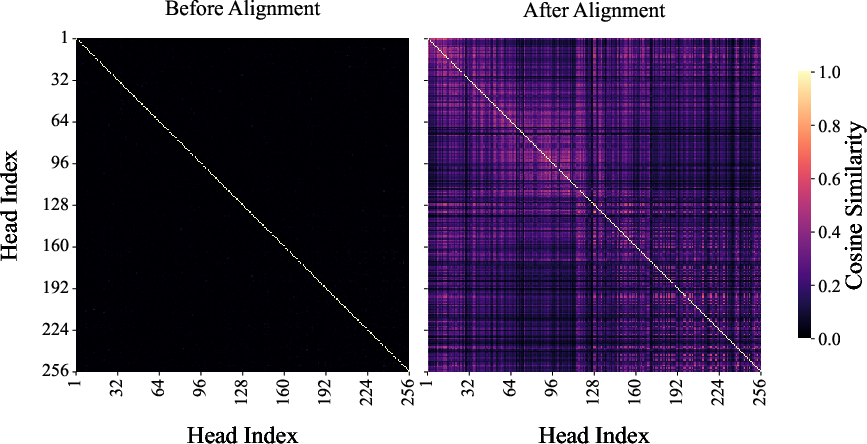
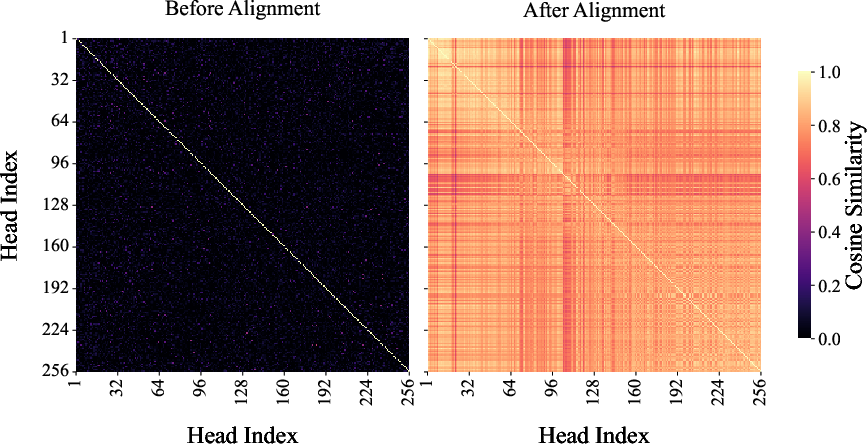
Figure 1: Cosine similarity before and after alignment between key (a) and value (b) heads calculated using Llama 3.1 8B on inputs from Qasper.
- Adaptive Quantization: A dynamic programming algorithm assigns bit widths to principal components, balancing reconstruction error and bit usage, ensuring high-fidelity cache compression.
- Entropy Coding: The entropy of quantized data is minimized using the DEFLATE algorithm, further compressing the caches without loss.
Experimental Evaluation
\Method{} has been evaluated across various LLMs, including Llama 3, Mistral NeMo, and R1-Qwen, demonstrating significant compression efficiency:
- Achieves up to 20x compression with minimal impact on models' reasoning capabilities and context retention.
- Outperforms baseline methods like token eviction and SVD-based approaches in both compression ratio and model accuracy.
Calibration of Llama with \Method{} highlights the quality-economic trade-off in reconstructing compressed data, demonstrating its effectiveness in sustaining model inference performance (Figure 2).
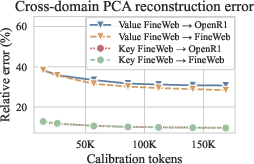
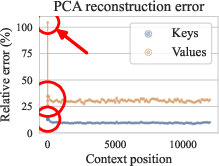
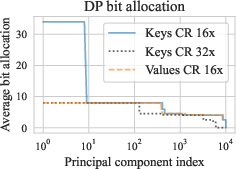
Figure 2: Calibration of Llama 3.1 8B with \Method{}.
Implementation Details
- Scalability: Designed to run efficiently on modern GPU hardware, leveraging parallelism for PCA computation and entropy encoding.
- Deployment: \Method{} can be integrated into existing LLM serving architectures, significantly reducing operational costs by lowering memory demands and mitigating cache retention issues.
Conclusion
\Method{} presents a viable solution to the critical problem of KV cache management in LLM inference. By effectively compressing caches without degrading model performance, it facilitates more scalable and cost-effective deployments of LLMs. Future work may explore integrating \Method{} with other optimization techniques like sparse attention or token pruning to further enhance memory efficiency and model throughput.