- The paper demonstrates a critical decline in LLM accuracy on logic puzzles as complexity increases, regardless of model size or additional compute.
- It introduces ZebraLogic, a robust evaluation framework using CSP-derived grid puzzles to quantify search space size and Z3 conflict metrics.
- The study reveals that scaling models or using advanced sampling techniques only partially overcomes the inherent limitations in logical reasoning tasks.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning
The paper "ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning" (2502.01100) examines the logical reasoning capabilities of LLMs. It introduces ZebraLogic, an evaluation framework for assessing the scaling limits of LLM reasoning performance on logic grid puzzles derived from constraint satisfaction problems (CSPs). The results indicate a significant decline in accuracy with increasing problem complexity, regardless of model size or inference-time computation.
The ZebraLogic framework constructs puzzles requiring the assignment of attributes to houses based on a set of clues, drawing on CSPs to provide a mathematically robust test environment. Each ZebraLogic puzzle consists of N houses and M attributes, with clues introducing constraints that the model must satisfy.
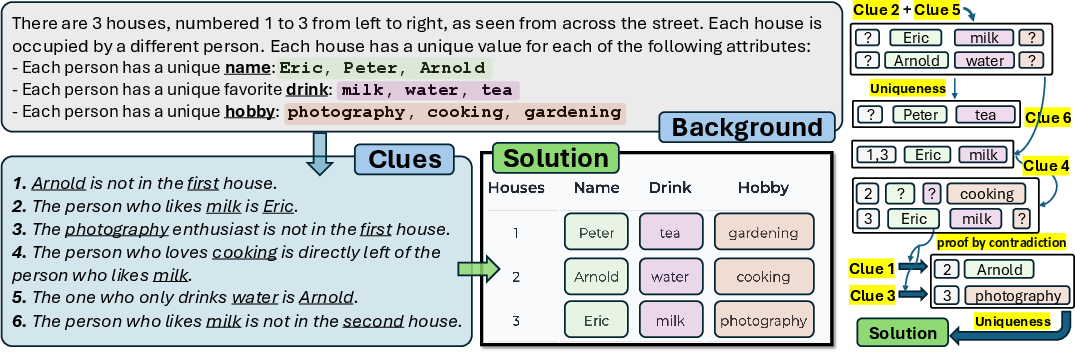
Figure 1: An example of ZebraLogic features with 3 houses and 3 attributes, illustrating the task for assigning attributes based on provided clues.
Complexity Metrics
Two metrics evaluate problem complexity: search space size and Z3 conflicts. Search space size represents the number of possible configurations, while Z3 conflicts measure logical complexity. The puzzles challenge LLMs by scaling these dimensions.
Main Findings
The findings underscore a "curse of complexity" in logical reasoning with LLMs; their accuracy degrades markedly as search space complexity increases. Simple problems remain solvable, but accuracy diminishes drastically for more intricate problems, indicating profound scalability issues.
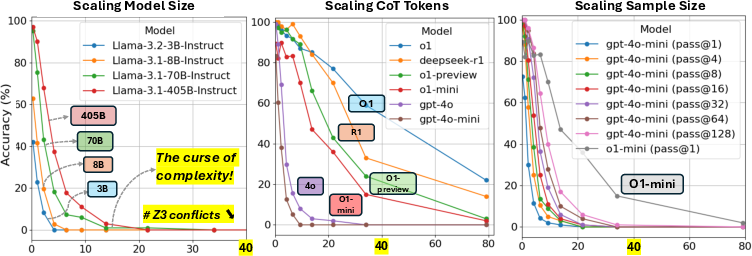
Figure 2: Accuracy vs number of Z3 conflicts for various models, depicting scaling effects on reasoning performance.
The study demonstrates that neither increasing model size nor enhancing inference-time computation sufficiently addresses this scalability issue. For instance, Llama-3.1-405B outperforms smaller models in simpler search spaces, yet fails similarly as complexity rises.
Scaling Model Size and Test-Time Compute
While increasing LLM size shows potential improvements for smaller puzzles, it does not yield comparable gains in more complex domains. This suggests intrinsic limitations in scaling model sizes for significant complexity.
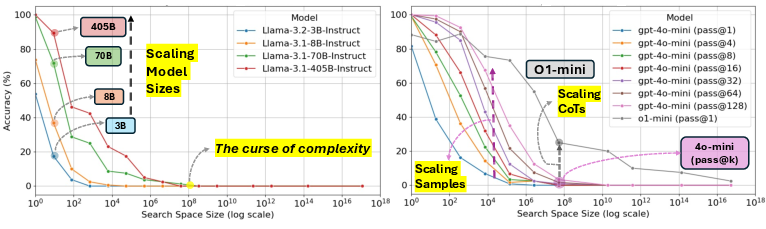
Figure 3: Comparison of model size scaling and test-time compute scaling under varied search space complexities.
Expanding test-time compute through methods like Best-of-N sampling and backtracking can offer partial performance gains. Although repeated sampling improves theoretical performance potential (e.g., GPT-4o with BoN sampling nears o1 performance), practical gains remain constrained, highlighting the inadequacy of current techniques.
Hidden Reasoning Tokens
The o1 models utilize extensive hidden chain-of-thought (CoT) tokens during inference. This approach, not visible to users, appears pivotal in o1's superior problem-solving abilities. However, this method's limits are exposed when complexity crest certain bounds, indicating a saturation point for current strategies.
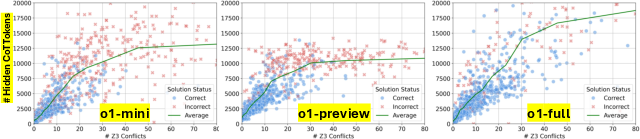
Figure 4: The relationship between hidden CoT tokens and Z3 conflicts, suggesting scale with problem complexity.
Conclusion
The results from ZebraLogic contribute significant insights into the boundaries of LLM reasoning scalability. Current frameworks struggle with high-complexity reasoning tasks, and both traditional scaling and compute-intensive strategies fall short. Future research should explore innovative methodologies to enhance logical reasoning capabilities in LLMs, emphasizing robust, scalable non-monotonic reasoning mechanisms.