- The paper introduces LogiPlan, a benchmark assessing LLMs in plan generation, consistency detection, and relational reasoning over structured graphs.
- It employs dynamic task complexity by varying object counts, relation depth, and structural constraints to measure model performance.
- Experimental results reveal significant performance gaps between reasoning and instruction-based models, guiding future research directions.
LogiPlan: Benchmarking Logical Planning and Relational Reasoning in LLMs
The paper "LogiPlan: A Structured Benchmark for Logical Planning and Relational Reasoning in LLMs" (2506.10527) introduces LogiPlan, a new benchmark designed to evaluate the performance of LLMs in logical planning and reasoning over complex relational structures. The benchmark focuses on assessing the generation, consistency detection, and querying of structured graphs, which are crucial for applications involving network infrastructure, knowledge bases, and business process schemas. LogiPlan enables dynamic variation of task complexity by controlling the number of objects, relations, and the minimum depth of relational chains, thus providing a granular assessment of model performance across different difficulty levels.
LogiPlan Benchmark Design and Tasks
The LogiPlan benchmark comprises three distinct yet complementary tasks, each designed to probe different aspects of logical and relational reasoning: Plan Generation, Consistency Detection, and Comparison Question.
The benchmark also evaluates the models' self-correction capabilities by prompting them to verify and refine their initial solutions. This is done by asking "Are you sure?" after the Consistency Detection and Comparison Question tasks to assess the impact of revisions on overall accuracy.
Experimental Evaluation and Results
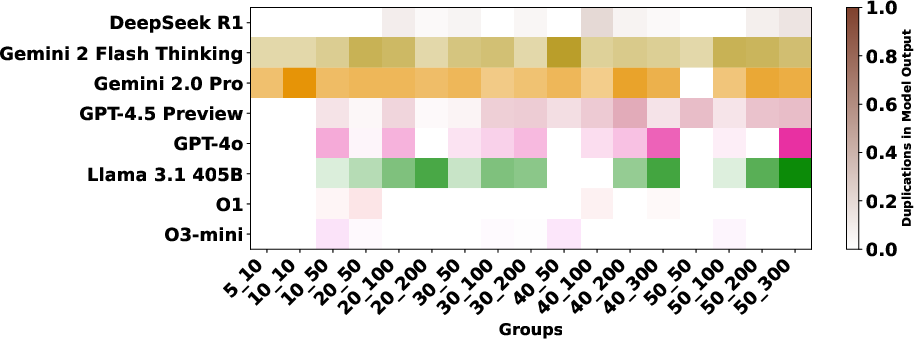
The LogiPlan benchmark was used to evaluate nine state-of-the-art models, including instruction-tuned and reasoning-capable LLMs: Llama 3.1 405B, Gemini 2.0 Pro, GPT-4o, GPT-4.5, O1, O3-mini, DeepSeek R1, Gemini 2 Flash Thinking, and Claude 3.7 Sonnet.
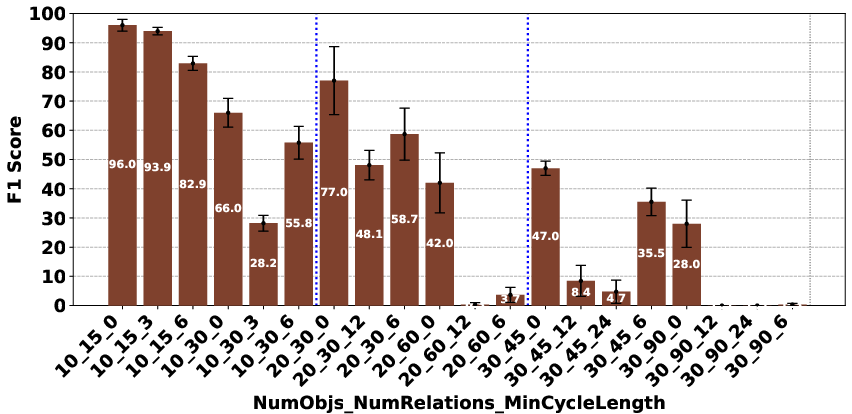
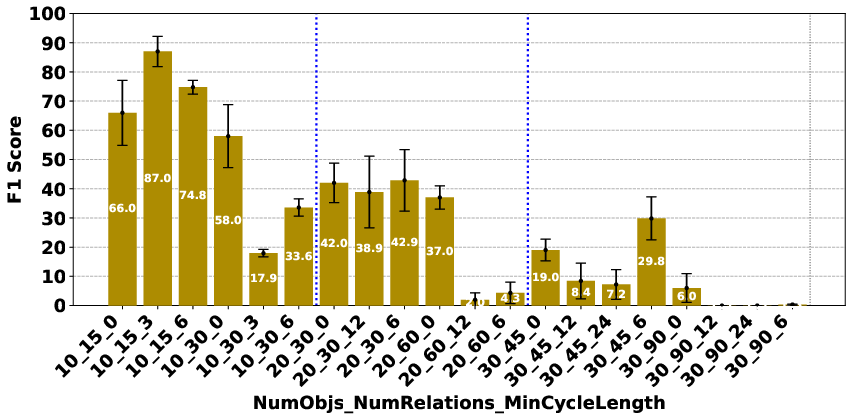
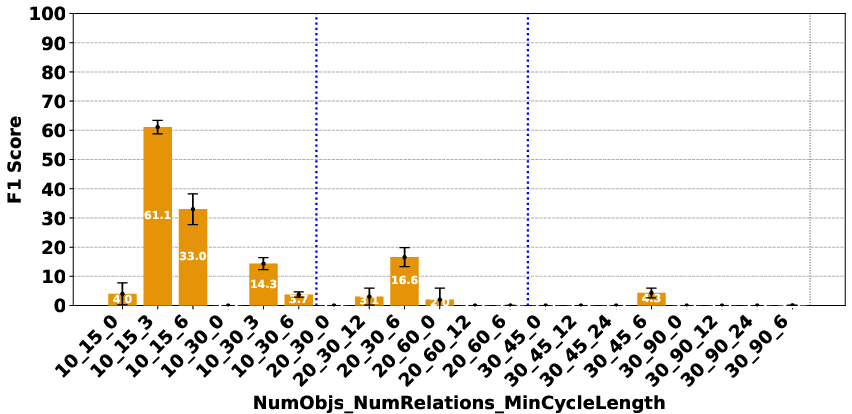
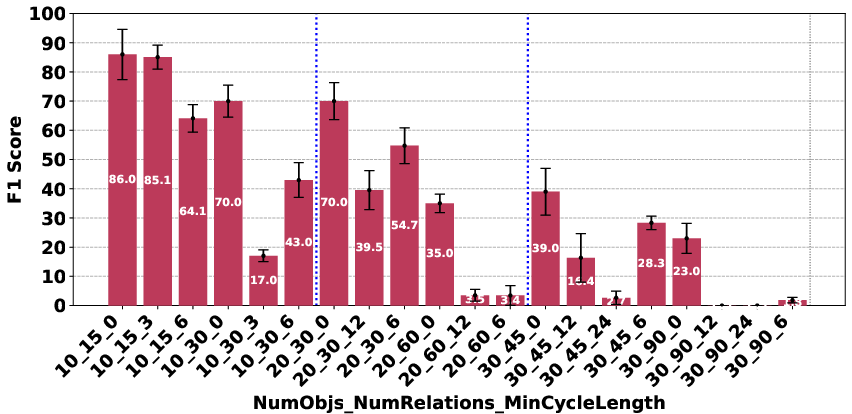
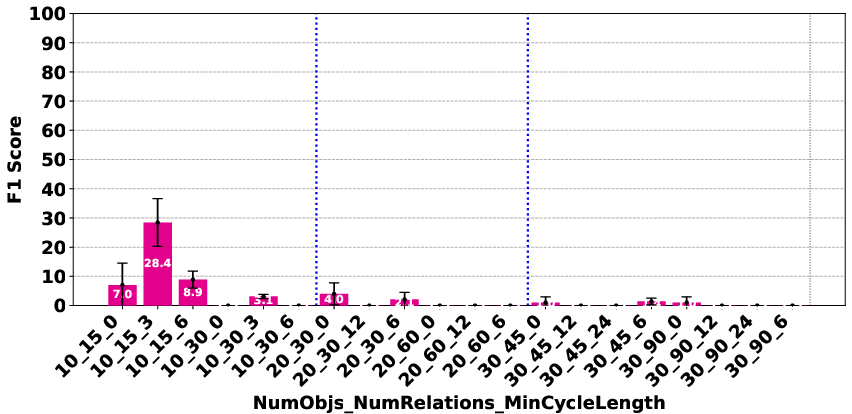
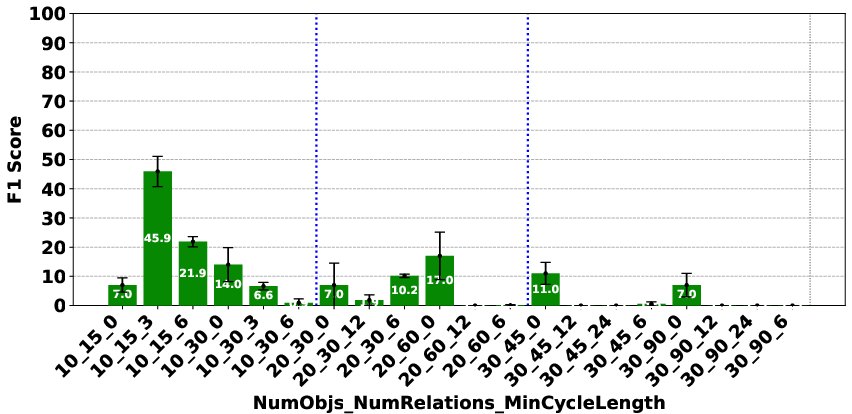
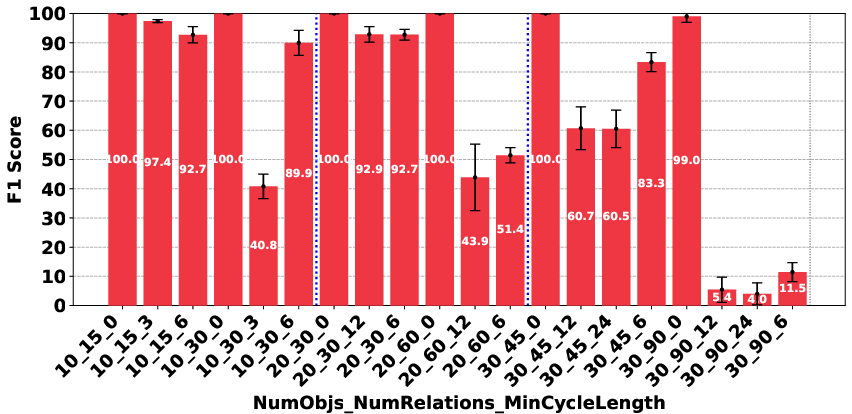
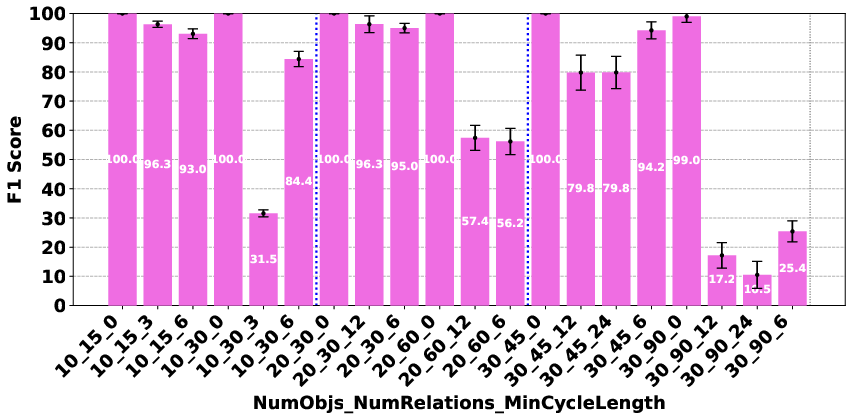
Figure 3: Deepseek R1.
The evaluation revealed significant performance disparities that correlate with model scale and architecture. In the Plan Generation task, reasoning-based models demonstrated a superior ability to identify straightforward generation techniques, such as ordering objects logically (e.g., A>B>⋯>Z). For the Consistency Detection and Comparison Question tasks, the performance gap persisted, particularly between O1 and O3-mini and the other models. The Consistency Detection task proved to be the most challenging, with even state-of-the-art reasoning models struggling as the size of the problem increased.
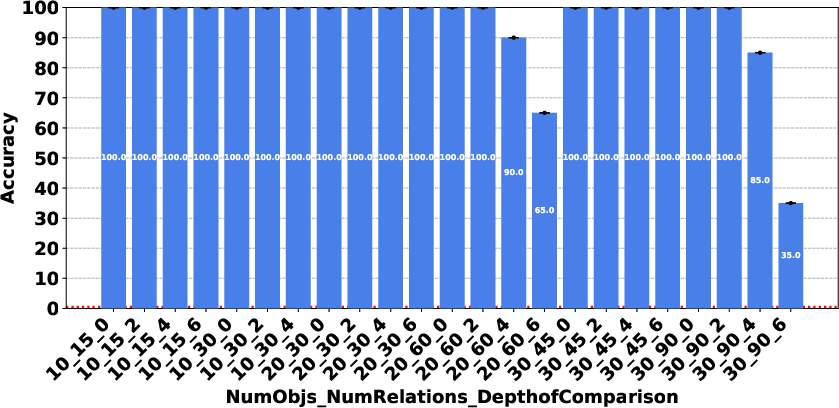
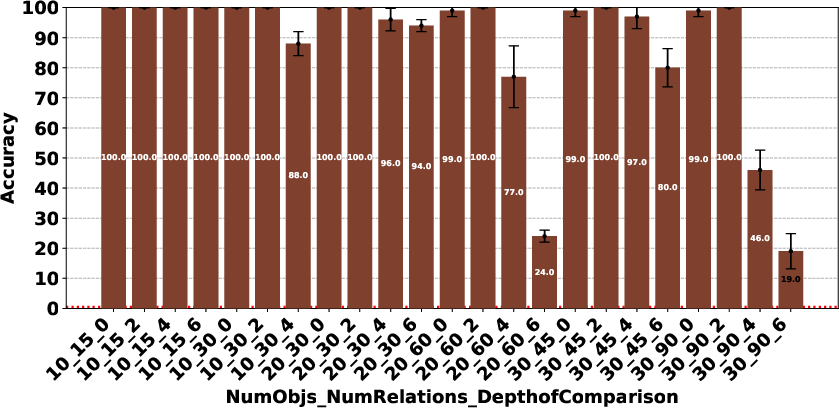
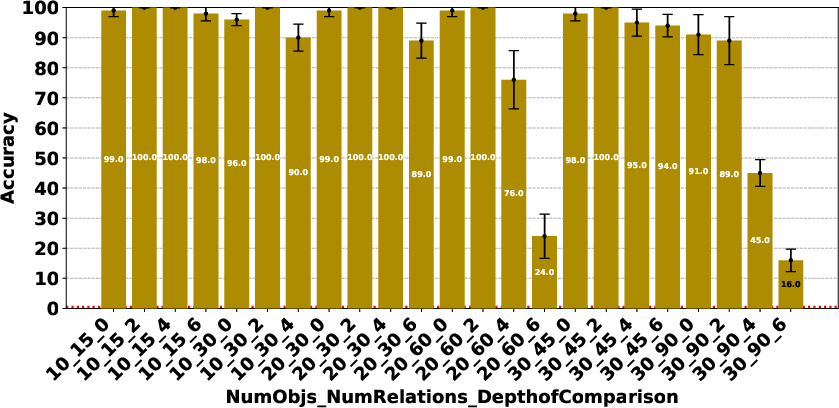
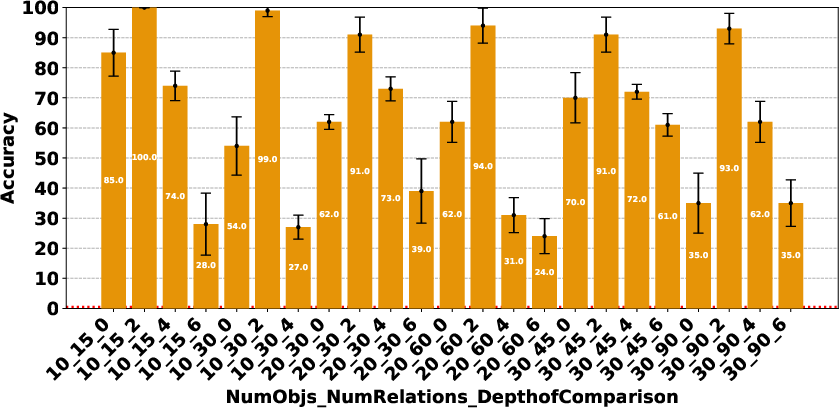
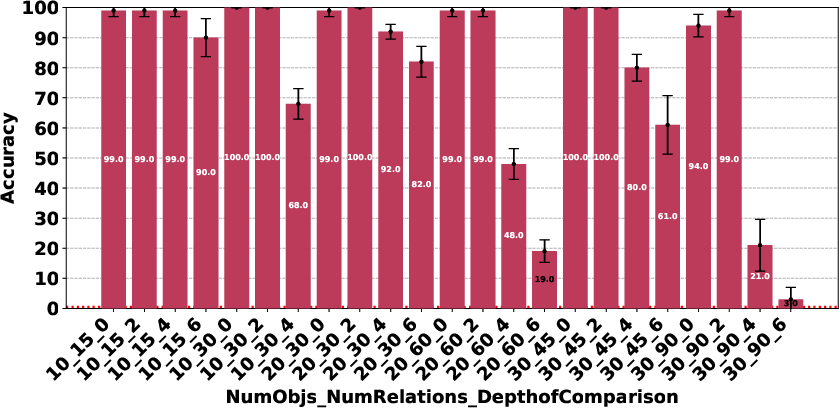
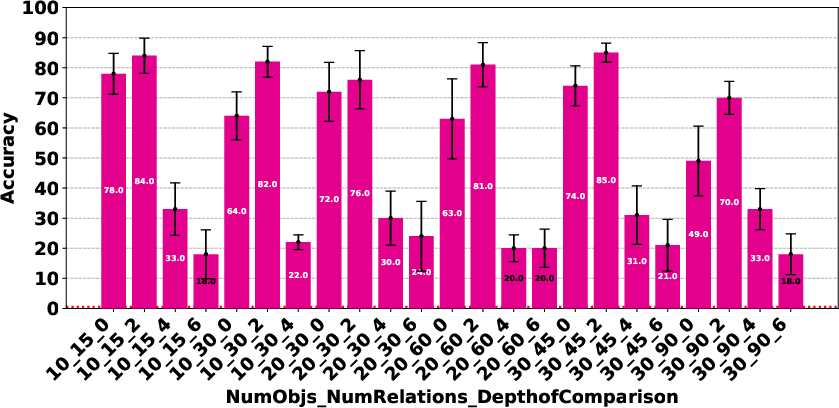
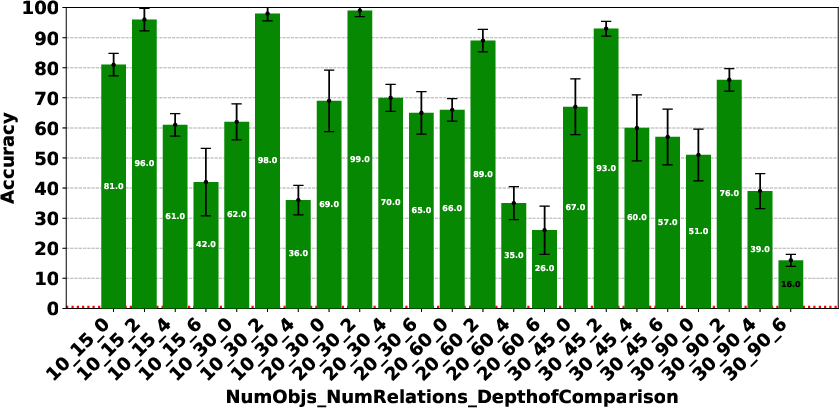
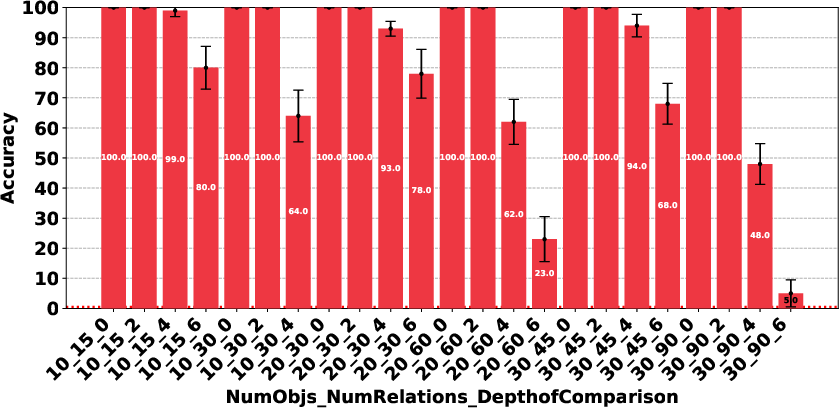
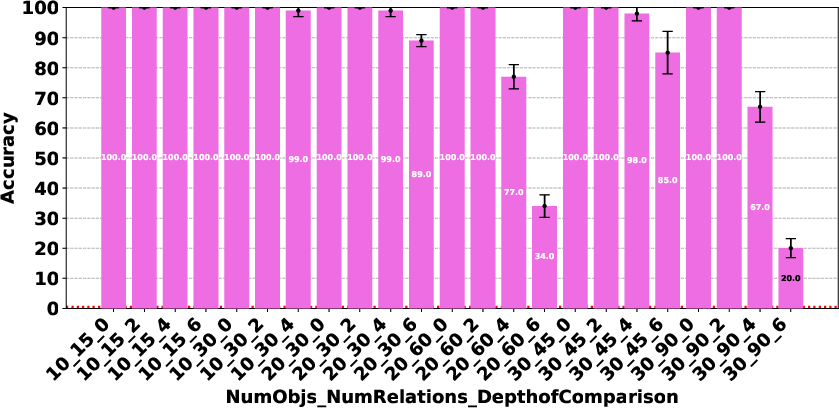
Figure 4: Claude 3.7 Sonnet Thinking.
The paper highlights that models like DeepSeek R1 and Gemini 2 Flash Thinking experienced a performance drop in the Consistency Detection task much earlier than other models as problem size increased. Self-correction capabilities also varied, with some models improving their performance upon re-evaluation, while others exhibited minimal change or a performance drop.
Implications and Future Directions
LogiPlan serves as a diagnostic tool and a catalyst for future research, pushing the boundaries of what is achievable in logical relational reasoning with LLMs. The benchmark and the code for data generation and evaluation are open-sourced to enable future research on LLM evaluation and reasoning. The findings suggest that while LLMs have made notable progress in handling structured relational reasoning, significant performance gaps remain, particularly as task complexity increases.
The research underscores the limitations of instruction-based models in generating logically consistent plans and highlights the robust, albeit varied, performance of dedicated reasoning models. Future research directions include developing more sophisticated architectures and self-correction strategies that can better tackle real-world, complex logical planning problems. Additionally, exploring methods to enhance the ability of LLMs to handle larger problem sizes and more intricate relational structures remains a key area for investigation.
Conclusion
The LogiPlan benchmark offers valuable insights into the logical planning and relational reasoning capabilities of LLMs. By providing a structured framework for evaluating these skills, LogiPlan enables researchers to identify the strengths and weaknesses of different models and guide the development of more advanced AI systems capable of tackling complex real-world problems. The benchmark's dynamic nature and open-source availability ensure its continued relevance and contribution to the field of LLM research.