- The paper introduces novel merging techniques that reduce parameter interference by replacing traditional unweighted averaging with Dare and Ties methods.
- It employs sequence-level routing heuristics based on perplexity to effectively select experts and minimize fine-tuning needs.
- Empirical evaluations on benchmarks like GSM8K and MATH demonstrate significant performance improvements for both homogeneous and heterogeneous model merging.
MergeME: Model Merging Techniques for Homogeneous and Heterogeneous MoEs
The paper introduces innovative model merging techniques designed for enhancing the performance of Mixture-of-Experts (MoE) models by effectively merging homogeneous and heterogeneous LLMs. This is done by addressing parameter interference and exploring new methods for integrating experts with differing architectures.
Introduction to Merging MoE Models
The task of merging specialized LLMs into a unified MoE model aims at leveraging domain-specific expertise while maintaining general performance. Traditional methods of merging rely on unweighted averaging, which often faces parameter interference issues, requiring extensive fine-tuning post-merging. This paper presents methodologies that mitigate these issues and offer new techniques for heterogeneous expert integration.
Homogeneous Model Merging
The paper proposes advanced methods to replace averaging in the merging process to reduce parameter interference, specifically focusing on the use of Dare and Ties approaches. These methods trim task vectors to resolve conflict between parameters during merging. Furthermore, the authors introduce novel routing heuristics based on perplexity, which enable enhanced performance without extensive fine-tuning.
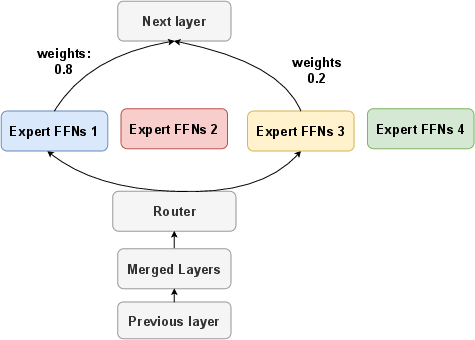
Figure 1: Overview of the proposed MoE framework for homogeneous model merging. We replace averaging with Dare or Ties merging to reduce parameter interference. Additionally, we introduce novel routing heuristics to enhance performance without fine-tuning.

Figure 2: Different types of parameter interference and merged outputs produced by simple averaging.
Methodologies and Routing Heuristics
The proposed methodologies for homogeneous model merging include sequence-level routing heuristics based on perplexity (PPL) of expert models. This heuristic selects the most confident experts for token sequences, reducing the need for fine-tuning. Additionally, the paper emphasizes separating non-Feedforward Network (FFN) layers to address inconsistencies in the merging process.
Heterogeneous Model Merging
For models with differing architectures, the paper proposes merging techniques that employ projectors and a novel routing network for sequence-level decision making. These innovations allow for the integration of diverse expert models into a cohesive MoE framework.
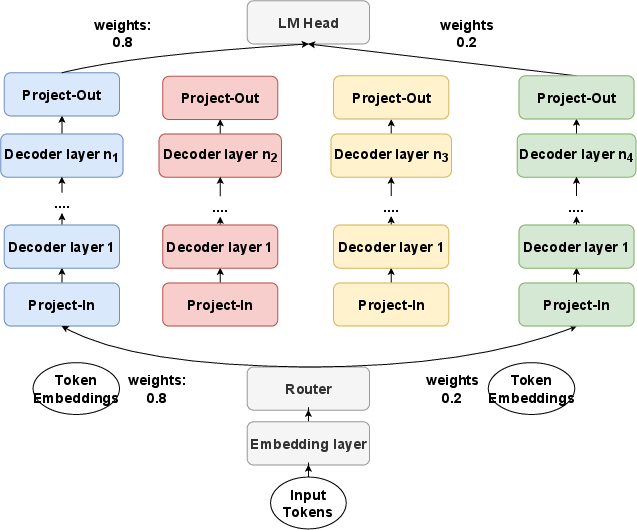
Figure 3: Overview of the proposed MoE framework for heterogeneous experts. Each color represents one heterogeneous expert. n1,⋯,n4 refers to the number of layers in each expert.
Empirical Evaluation
Experiments across benchmarks like GSM8K, MBPP, and MATH demonstrate the efficacy of the proposed methods. The merged models show improved performance over traditional merging techniques, evidenced by consistent enhancement in task routing and quick adaptation during fine-tuning stages. The results confirm the effectiveness of the proposed innovations in both homogeneous and heterogeneous merging scenarios.
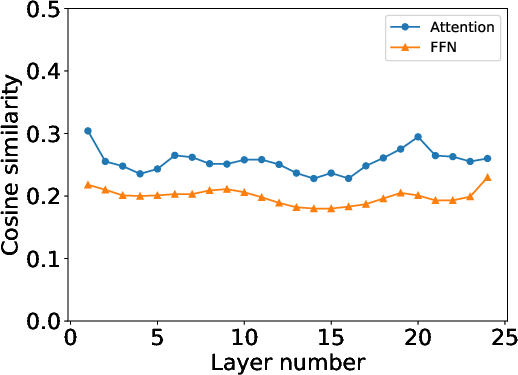
Figure 4: Similarity of task vector for attention and FFNs layers for Math and Code Expert experts. We average the similarity of attentions or FFNs in one decoder layers as the overall similarity for each layer.
Conclusions and Future Directions
The techniques introduced for MoE merging significantly reduce parameter interference and optimize routing decisions, enhancing overall performance across various datasets. Future work could explore the inclusion of load-balancing techniques and extend these approaches to multimodal domains involving vision and audio, fostering more robust and comprehensive MoE model architectures.

