OptMerge: Unifying Multimodal LLM Capabilities and Modalities via Model Merging
Abstract: Foundation models update slowly due to resource-intensive training, whereas domain-specific models evolve rapidly between releases. Model merging seeks to combine multiple expert models into a single, more capable model, reducing storage and serving costs while supporting decentralized development. Despite its potential, previous studies have primarily focused on merging visual classification models or LLMs for code and math tasks. Recently, Multimodal LLMs (MLLMs) that extend LLMs through large-scale multimodal training have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, $\textbf{(i)}$ we introduce a model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, studying both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-LLMs), moving toward the Omni-LLM. $\textbf{(ii)}$ We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. $\textbf{(iii)}$ We find that model merging offers a promising way for building improved MLLMs without requiring training data. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a clever way to build powerful AI models without doing lots of expensive training. The idea is called “model merging.” Instead of training one giant model on everything, you take several smaller “expert” models (each good at a specific skill) and combine them into one model that can do many things. The paper focuses on merging Multimodal LLMs (MLLMs) — AI that can understand text plus other inputs like images, audio, and video.
What questions does the paper try to answer?
- Can we reliably merge different expert AI models into a single, more capable model without using training data?
- What’s a fair way to test and compare merging methods for multimodal models?
- How does the amount of fine-tuning (how much the expert models were changed from the original base model) affect the success of merging?
- Can merging help combine different kinds of inputs (like images, sounds, and videos) into one “omni” model?
- Is there a new merging method that works better than existing ones?
How did the researchers approach the problem?
Think of each expert model like a teammate with a special skill: one is great at answering questions about pictures (VQA), another understands charts, another reads text inside images (OCR), and another can point to objects in images (grounding). The goal is to combine their skills without retraining everything from scratch.
Here’s the approach in everyday terms:
- Base model and expert models:
- Start with a base model (the original). Each expert is the base model that was tweaked (fine-tuned) for a specific task.
- A “task vector” is the difference between the expert model and the base model — like a recipe listing the changes that made the expert good at its specialty.
- Benchmark they built:
- They created a clear test setup with five skills: VQA, Geometry (math diagrams), Chart understanding, OCR-based Q&A, and Grounding (finding objects in images).
- They gathered large, public datasets (100,000+ examples per skill) to fine-tune experts and to evaluate merging fairly.
- They also tried merging different modalities (vision-language, audio-language, video-language) into one “omni” model.
- Merging methods they evaluated:
- Linear mixing: Simply add or average the “recipes” (task vectors).
- Sparsification: Drop redundant changes to reduce conflicts.
- SVD (low-rank) techniques: Compress changes to keep only the most important directions (like summarizing a long essay into key points).
- Optimization methods: Treat merging like a puzzle and use algorithms to minimize conflicts between tasks.
- Their new method: OptMerge
- It cleans up noisy parts of the task vectors and focuses on the most important changes using SVD (a mathematical way to find key directions in data).
- It initializes the merged model smartly and uses stable optimization (like careful, steady adjustments) so the model doesn’t “explode” or lose its language skills.
- It adapts differently depending on how the experts were fine-tuned:
- Full fine-tuning: Many parameters changed — OptMerge denoises these changes.
- LoRA fine-tuning: Only small, low-rank add-ons were used — OptMerge keeps updates balanced and stable.
- A key insight (simple theory):
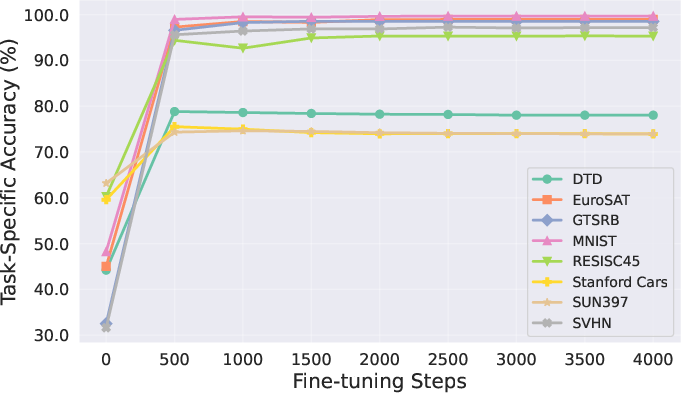
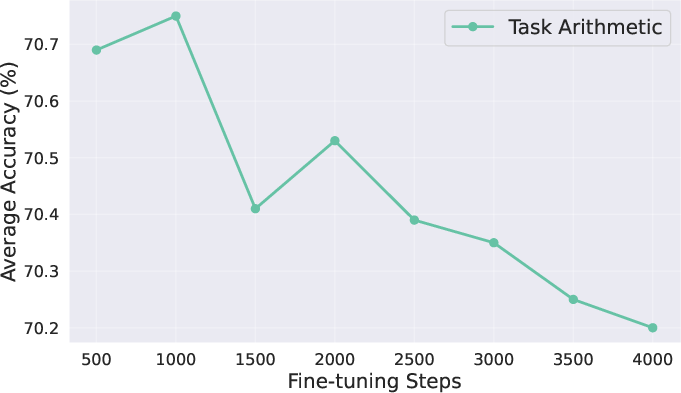
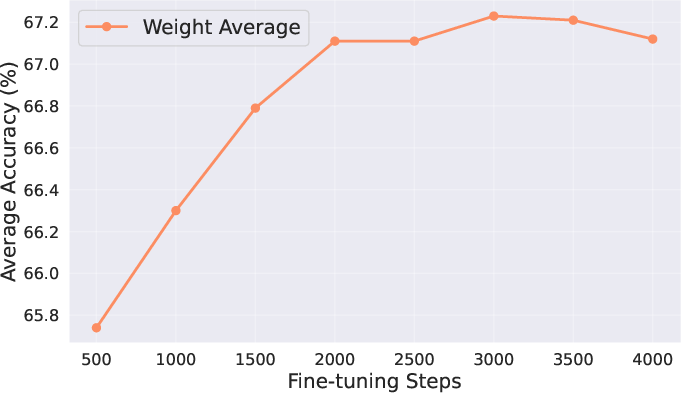
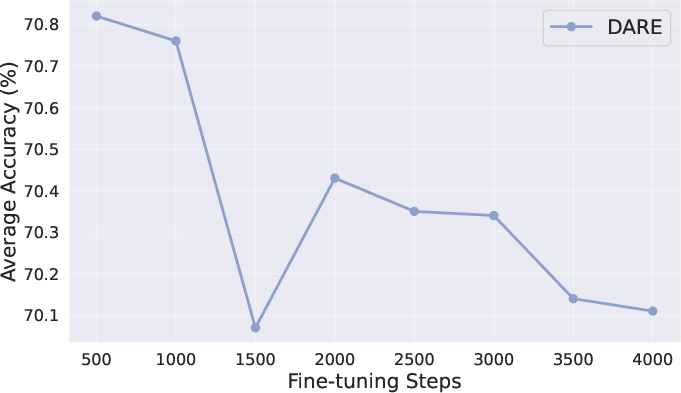
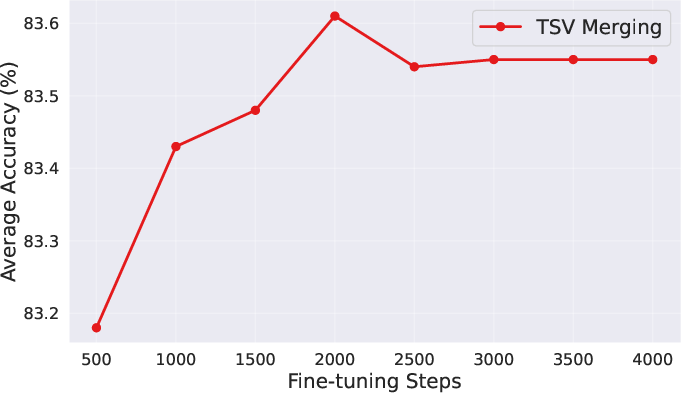
- The success of merging depends on how much the expert models drifted from the base. If you use a big learning rate or train for too long, the experts move far away and become harder to merge.
- Small changes are easier to combine (but might slightly lower the expert’s solo performance). It’s about finding the balance.
What did they find and why does it matter?
- Merging works — often better than training on mixed data:
- Across tasks like geometry, charts, OCR, and grounding, the merged models matched or beat models trained on combined datasets.
- Their OptMerge method achieved the best average results, with about a 2.48% improvement over a strong baseline.
- Merging different modalities helps:
- Combining vision, audio, and video models led to better results than using any single modality alone.
- The merged “omni” model even outperformed some methods that combine modalities at inference time.
- It’s fast and cheaper:
- Merging took hours and used much less GPU memory compared to days-long training runs with huge memory demands.
- No training data is needed for merging — you just need the model files.
- Real-world test:
- They merged actual community models from Hugging Face (made by different people for different tasks and languages).
- The merged models were more robust and performed better on average than the individual experts.
- Important tip:
- Don’t over-fine-tune the experts if you plan to merge them later. Models that stayed closer to the base were easier to merge and gave better combined performance.
What’s the impact?
- Practical: Teams can build specialized models separately, then combine them later — saving time, money, and data access hassles.
- Scalable: You can quickly create a strong multitask or multimodal model without retraining on massive datasets.
- Community-friendly: Open-source models from different creators can be merged into better systems.
- Future of “omni” AI: Merging is a promising path to AI that understands text, images, audio, and video together — like a single assistant that can watch a clip, listen to a sound, and read on-screen text.
- Guidance for developers: If you plan to merge, keep fine-tuning mild and clean (limit parameter drift). OptMerge shows how to denoise and stabilize merges for best results.
Quick recap
- Goal: Combine multiple expert MLLMs into one powerful model without retraining.
- Solution: A new benchmark, tests of 10 merging methods, and OptMerge — a stable, denoising, optimization-based merger.
- Results: Merging often beats mixed-data training, works across modalities, saves compute, and handles real community models.
- Impact: Faster, cheaper, and more collaborative AI development — moving toward truly multimodal “omni” models.
Glossary
- Activation averaging: Averaging intermediate neural activations from different models or modalities during inference to compose capabilities. "NaiveMC~\citep{chen2024model} performs simple activation averaging, while DAMC~\citep{chen2024model} decouples parameters during training to reduce modal interference."
- Adam optimizer: A stochastic gradient-based optimizer with adaptive learning rates and momentum used for parameter optimization. "Using the Adam optimizer, we obtain the merged vector , which minimizes interference with task vectors on multiple tasks"
- Audio-LLM: A model that processes audio inputs and generates or understands text, typically with an audio encoder and an LLM. "The audio-LLM adopts BEATs-Iter3+~\citep{chen2023beats} as the audio encoder, with a Q-Former as the connector."
- Audio-VQA: Audio-Visual Question Answering; tasks requiring reasoning over visual and audio signals in videos. "For Omni-LLMs, we assess Audio-VQA, which requires multimodal understanding and spatiotemporal reasoning about visual objects, sounds, and their relationships in videos."
- CLIP-ViT-L-336px: A specific vision encoder architecture from CLIP using a large ViT at 336px resolution. "The vision-LLM uses CLIP-ViT-L-336px~\citep{radford2021learning} as the image encoder, paired with an MLP projection as the connector."
- Connector: A projection or module that maps encoder outputs into the LLM’s input space for multimodal integration. "The vision-LLM uses CLIP-ViT-L-336px~\citep{radford2021learning} as the image encoder, paired with an MLP projection as the connector."
- Data-free methods: Merging approaches that do not require access to training or evaluation data to combine models. "Data-free methods merge fine-tuned models without requiring additional data."
- DARE: A merging technique that drops and rescales task vectors to reduce interference and redundancy. "DARE~\citep{yu2024language} randomly drops redundant task vectors and rescales the remaining ones to mitigate parameter interference."
- Decorrelation: Reducing correlations between task-specific parameter changes to mitigate interference during merging. "It then reduces task interference through decorrelation."
- Dynamic merging (aka MoE-like methods): Composition approaches that route inputs to specialized modules at inference, typically requiring routers and larger storage. "Dynamic merging (aka MoE-like methods)~\citep{tang2024merging,huang2024emr,lu2024twin} requires the dynamic loading of task-specific modules based on test inputs, involving training routers or prior knowledge."
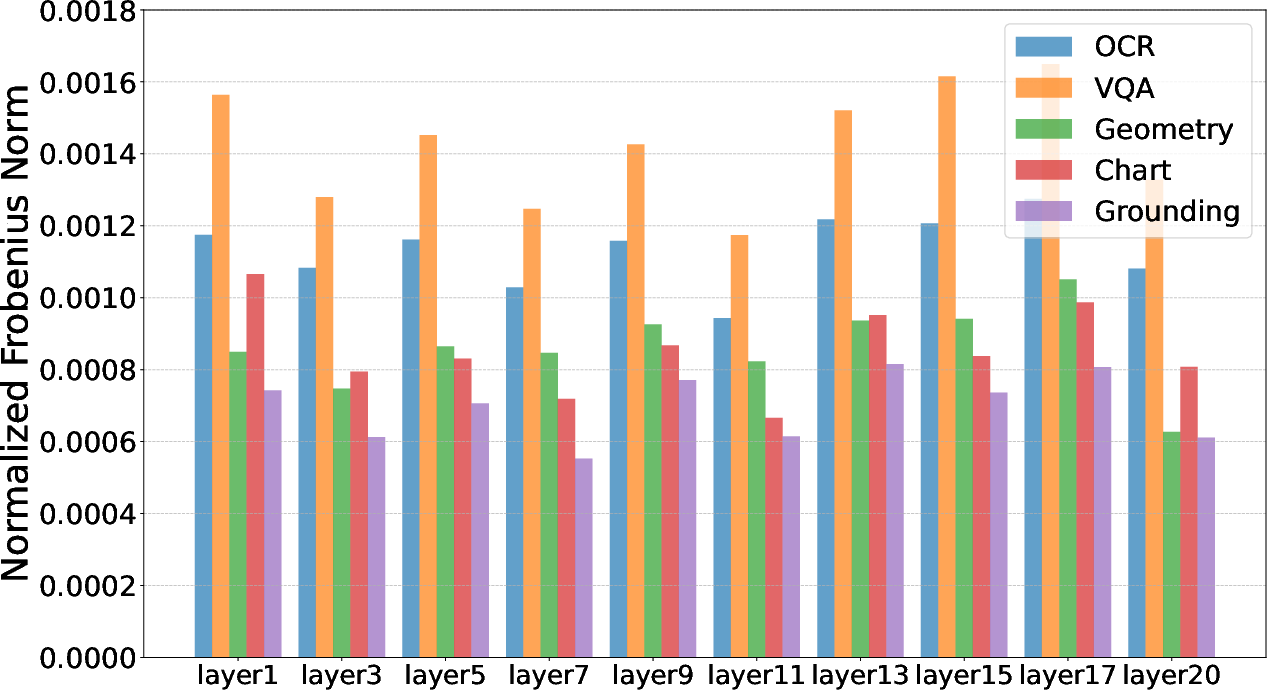
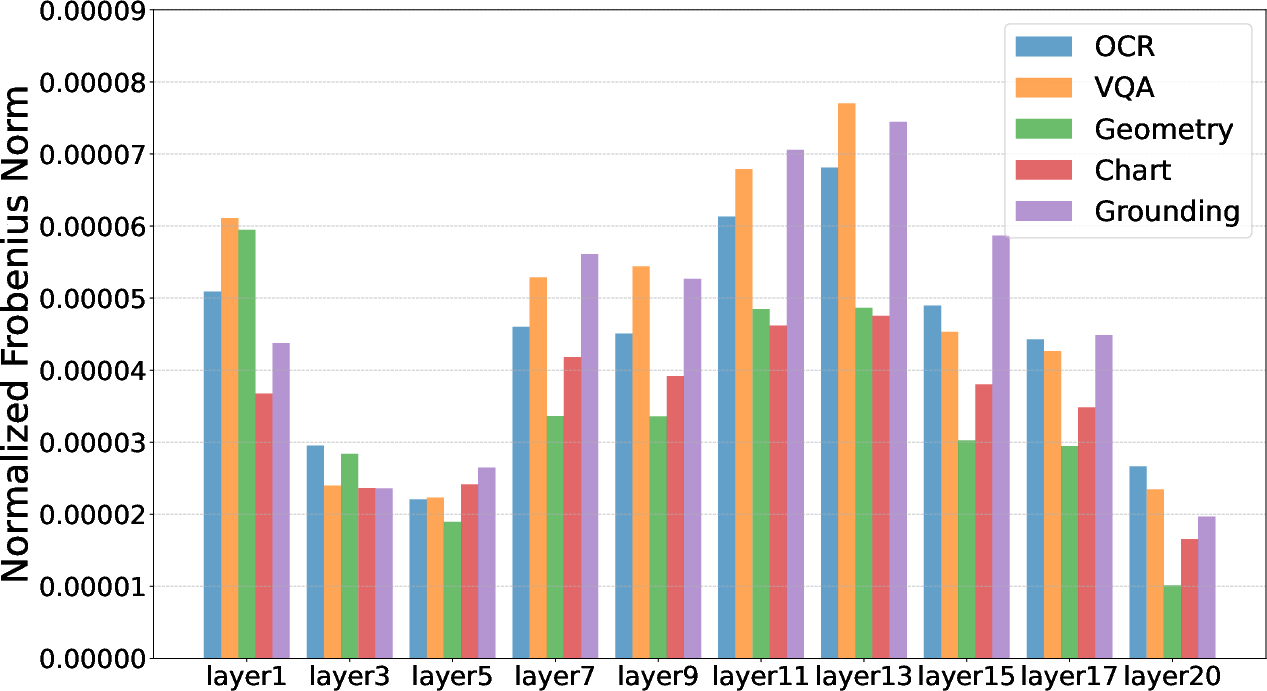
- Frobenius norm: A matrix norm defined as the square root of the sum of the squares of all entries; here used for task vector magnitudes. "The Frobenius norm equals the sum of squared singular values ."
- Implicit regularization: The tendency of certain optimization procedures (like SGD) to favor solutions with particular generalization properties without explicit penalties. "Notably, SGD provides implicit regularization~\citep{smith2021on,wang2022does}, constraining task vector optimization and navigating flat regions induced by null spaces."
- Iso-C: An isotropic merging method that flattens singular spectra to improve alignment of components across tasks. "Iso-C~\citep{marczak2025no} proposes an isotropic merging framework that flattens the singular value spectrum of task matrices, and enhances alignment between singular components of task-specific and merged matrices."
- LanguageBind: A video encoder framework for mapping video inputs into the LLM space. "The video-LLM employs LanguageBind~\citep{zhu2023languagebind} as the video encoder."
- Layer-wise interference: Conflict between task vectors at a given layer that can degrade multi-task performance after merging. "They define layer-wise interference between the merged vector and task vector as for task at layer ."
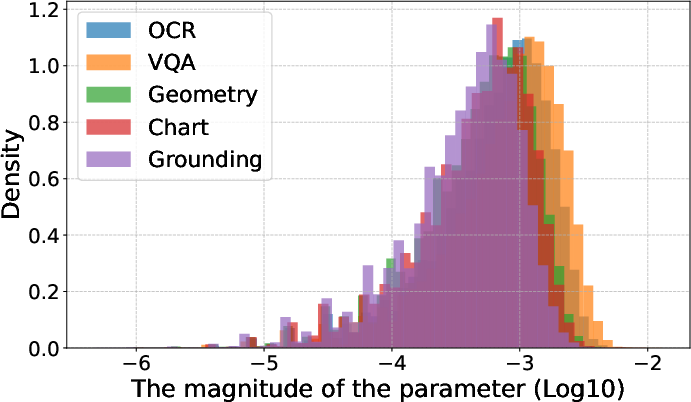
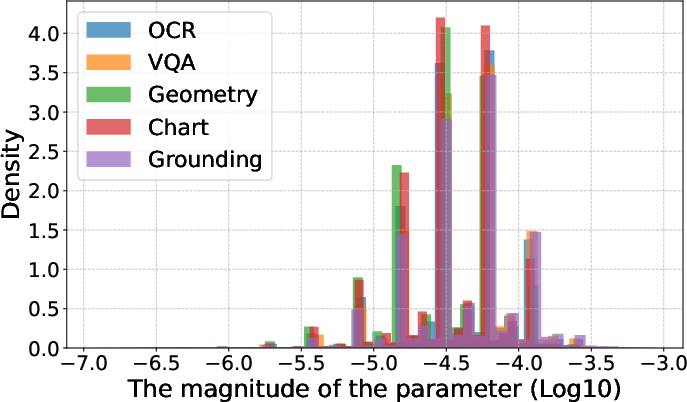
- Linear connectivity: A property where two models can be connected by a path of low loss in parameter space, implying mergeability. "The small task vector magnitudes suggest that fine-tuned models and base models exist in adjacent regions of the loss landscape with linear connectivity~\citep{wu2023pi}, facilitating effective model merging~\citep{ortiz-jimenez2023task}."
- Linear interpolation methods: Techniques that combine models or task vectors by arithmetic operations like averaging and summation. "Linear interpolation methods: Weight Averaging~\citep{wortsman2022model} simply averages the weights of models fine-tuned on different tasks."
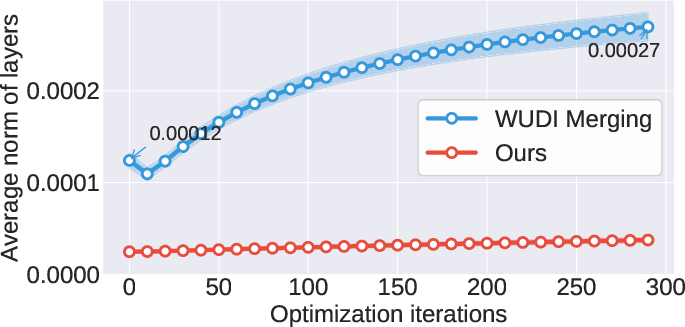
- Linear subspace: A vector space structure indicating task vectors lie in a low-dimensional linear manifold related to training data. "WUDI Merging~\cite{cheng2025whoever} proves that task vectors form an approximate linear subspace of the fine-tuning data ."
- Lipschitz continuous: A function whose differences are bounded by a constant times the input difference; used in loss bounds. "The loss on task is denoted by , which is -Lipschitz continuous."
- LoRA: Low-Rank Adaptation; fine-tuning method that inserts low-rank updates into pretrained weights. "We choose two types of vision-LLMs: InternVL2.5 and Qwen2-VL, providing both LoRA and full fine-tuning checkpoints."
- Loss landscape: The surface of the optimization objective over the parameter space, influencing mergeability and training behavior. "The small task vector magnitudes suggest that fine-tuned models and base models exist in adjacent regions of the loss landscape with linear connectivity~\citep{wu2023pi}, facilitating effective model merging~\citep{ortiz-jimenez2023task}."
- Low-rank approximation: Representing a matrix with few singular components to reduce noise and redundancy. "To address this issue, we propose reducing inter-task interference through low-rank approximation."
- Mixture training: Joint training on multiple datasets/tasks simultaneously, often used as a baseline for merged performance. "Our empirical results suggest that model merging can outperform mixture training"
- Modality encoder: A specialized encoder for a particular input modality (vision, audio, video) that feeds into an LLM. "Moreover, most existing MLLMs specialize in dual modalities, and incorporating new modality encoders requires re-training on new modality-text data."
- Multimodal LLMs (MLLMs): LLMs extended with non-text encoders and training to process multiple modalities. "Recently, Multimodal LLMs (MLLMs) that extend LLMs with broader capabilities through large-scale multimodal training have gained traction."
- Null space: The subspace in which a linear operator maps vectors to zero; gradients vanish along these directions in low-rank settings. "When optimizing , gradients become effective only in directions corresponding to non-zero singular values of , while approaching zero in other directions (null space)."
- Omni model alignment: Aligning a single model across many modalities and capabilities to function as an omni-model. "Our empirical results suggest that model merging can outperform mixture training, offering a viable path to omni-model alignment and a scalable approach to developing MLLMs with reduced computational cost and training time."
- Omni-LLM: A model that unifies multiple modalities (vision, audio, video) via a shared language backbone. "Moreover, we explore how model merging can combine different modalities (, vision-language, audio-language, and video-LLMs), moving toward the Omni-LLM."
- Optimization-based methods: Merging techniques that explicitly optimize a merged task vector via gradient descent on a defined loss. "Optimization-based methods: WUDI Merging~\cite{cheng2025whoever} proves that task vectors form an approximate linear subspace of the fine-tuning data ."
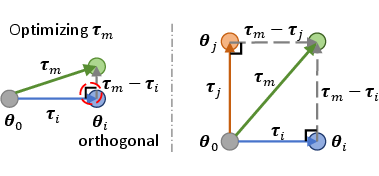
- Orthogonal matrices: Matrices whose columns (and rows) are orthonormal, often used to decorrelate or rotate parameter spaces. "The method seeks orthogonal matrices and to reconstruct the parameters of the merged model."
- Orthogonalization: Making vectors or components orthogonal to reduce interference, typically via rotations or projections. "TSV merging excels in modality merging because its orthogonalization mitigates modal conflicts"
- PCA (Principal Components Analysis): A dimensionality reduction technique selecting components with maximal variance. "By truncating singular values, we preserve critical features , which is similar to selecting principal components in Principal Components Analysis (PCA)~\citep{abdi2010principal}."
- Parameter drift: The degree to which fine-tuning moves parameters away from the base model, affecting mergeability. "proving that merging performance is influenced by the learning rate and iterations, which control the extent of parameter drift."
- Q-Former: A transformer-based module that learns queries to extract features from encoders for LLMs. "The audio-LLM adopts BEATs-Iter3+~\citep{chen2023beats} as the audio encoder, with a Q-Former as the connector."
- Router: A learned or heuristic component that selects expert modules in dynamic/MoE merging. "Dynamic merging (aka MoE-like methods)~\citep{tang2024merging,huang2024emr,lu2024twin} requires the dynamic loading of task-specific modules based on test inputs, involving training routers or prior knowledge."
- Singular value spectrum: The distribution of singular values across components, reflecting rank and energy of a matrix. "Iso-C~\citep{marczak2025no} proposes an isotropic merging framework that flattens the singular value spectrum of task matrices"
- Singular values: Non-negative values from SVD indicating component magnitudes along principal directions. "The Frobenius norm equals the sum of squared singular values ."
- Sparsification-based methods: Approaches that prune or sparsify task vectors to reduce redundancy and interference before merging. "Sparsification-based methods: Ties-Merging~\citep{yadav2023ties} combines steps like trimming, parameter sign determination, and disjoint merging to produce the ."
- Spectral structure: The pattern of singular values and vectors (the spectrum) that affects how SVD-based methods behave. "SVD-based methods are sensitive to the spectral structure of task vectors."
- SVD (Singular Value Decomposition): A matrix factorization into orthogonal matrices and singular values used for low-rank modeling. "Next, we perform SVD to isolate core task-specific knowledge from noise present in the top and lower singular vectors"
- Supervised fine-tuning (SFT): Training a pretrained model on labeled data to specialize its behavior. "For effective supervised fine-tuning, we gather at least 100k public dataset samples for each task"
- Task Arithmetic: A linear interpolation method that sums task vectors to build a multi-task model. "Task Arithmetic~\citep{ilharcoediting} computes task vectors for individual tasks"
- Task vector: The parameter difference between a fine-tuned model and its base, representing task-specific updates. "Task vectors contain significant redundancy and noise, leading to mutual interference during merging."
- Test-time adaptation: Adjusting model parameters using unlabeled test data to improve performance under distribution shifts. "Test-time adaptation~\citep{yang2024adamerging,yang2024representation,daheim2024model} assumes access to unlabeled test datasets"
- TIES Merging: A sparsification-based method that trims and merges task vectors with sign handling to reduce conflicts. "Ties-Merging~\citep{yadav2023ties} combines steps like trimming, parameter sign determination, and disjoint merging to produce the ."
- Truncated SVD: Approximating a matrix by keeping only the top-k singular components to reduce rank and noise. "We apply a direct low-rank approximation to using truncated without centering."
- TSV Merging: An SVD-based method that quantifies and reduces singular task interference via orthogonalization/decoupling. "TSV Merging~\citep{gargiulo2024task} quantifies task-specific feature overlap in weight space by measuring the singular task interference of ."
- Video-LLM: A model that encodes video inputs and interfaces with an LLM for text understanding and generation. "The video-LLM employs LanguageBind~\citep{zhu2023languagebind} as the video encoder."
- Vision-LLM: A model that combines a vision encoder with an LLM to process images and text jointly. "We choose two types of vision-LLMs: InternVL2.5 and Qwen2-VL, providing both LoRA and full fine-tuning checkpoints."
- Weight Averaging: Averaging parameters of multiple fine-tuned models to obtain a single merged model. "Weight Averaging~\citep{wortsman2022model} simply averages the weights of models fine-tuned on different tasks."
- WUDI Merging: An optimization-based method that minimizes layer-wise interference using task vectors to implicitly leverage training data. "WUDI Merging~\cite{cheng2025whoever} proves that task vectors form an approximate linear subspace of the fine-tuning data ."
Collections
Sign up for free to add this paper to one or more collections.

