- The paper introduces PuzzleMoE, a training-free method that compresses MoE models using sparse expert merging and bit-packed inference while maintaining high accuracy.
- It employs a dual-mask strategy that leverages saliency and similarity measures to merge expert weights efficiently, reducing redundancy.
- Experimental results show up to 16.7% higher accuracy at a 50% compression ratio along with significant memory and inference speed improvements.
PuzzleMoE: Efficient Compression of Large Mixture-of-Experts Models via Sparse Expert Merging and Bit-packed Inference
Introduction
The paper "PuzzleMoE: Efficient Compression of Large Mixture-of-Experts Models via Sparse Expert Merging and Bit-packed inference" (2511.04805) addresses the challenges of deploying Mixture-of-Experts (MoE) models, which offer scalable solutions for LLMs by activating a subset of expert networks per input. While MoEs promise efficiency, their practical application is hindered by the memory burden of storing all expert parameters. Previous exploration into expert dropping and merging has attempted to mitigate this issue, but these methods typically suffer from performance losses, especially at higher compression ratios. The paper introduces PuzzleMoE, a training-free method for compressing MoE models that utilizes sparse expert merging and a novel bit-packed encoding scheme, maintaining accuracy while reducing memory demands and enhancing inference efficiency on GPUs.
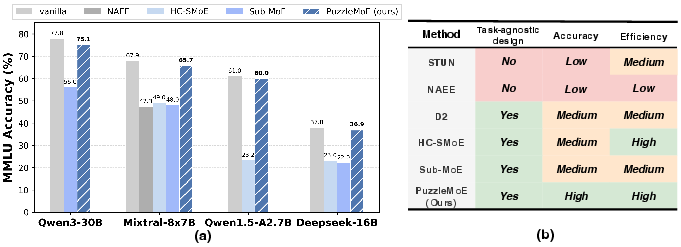
Figure 1: Accuracy of different MoE models on MMLU benchmark under 50% compression ratio with various expert compression methods, among which PuzzleMoE achieves the best accuracy.
Methodology
Sparse Expert Merging
PuzzleMoE employs a pairwise dual-mask strategy for sparse expert merging. This involves creating an element-wise similarity mask to identify shared parameters and a saliency-based mask to retain important, specialist entries of the weights. Pairwise merging is favored for efficiency and operational simplicity, helping maintain specialization without excess redundancy. This solution uniquely merges weights by considering magnitude similarities and saliency derived from input activations.
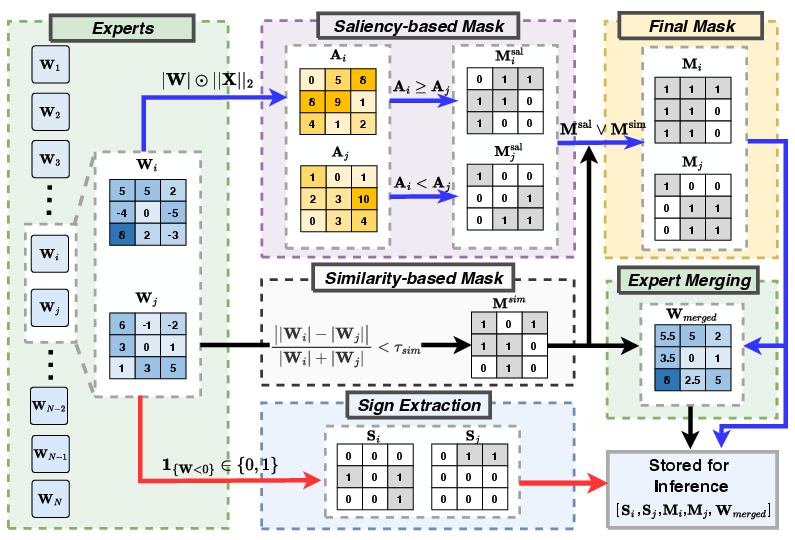
Figure 2: Procedure of sparse expert merging algorithm.
Efficient Inference with Bit-Packing
A key innovation in PuzzleMoE is its bit-packed format which leverages underutilized bits in the Bfloat16 representation to encode masks and signs directly within the weight tensors. This design eliminates the overhead of additional storage for masks, enabling more efficient use of GPU memory and faster inference by optimizing data access and computation pathways.
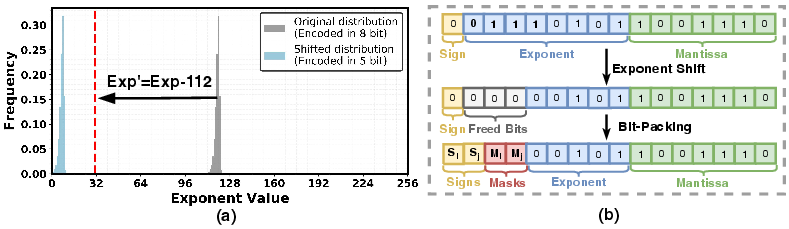
Figure 3: Illustration of the mask packing procedure.
Experimental Results
PuzzleMoE's experimental validation spans four MoE architectures across various benchmarks. It achieves up to 16.7% higher accuracy than previous methods at a 50% compression ratio and demonstrates notable inference speedup and memory savings. The model's robustness is confirmed across general tasks like WikiText and domain-specific tasks such as GSM8K, proving highly effective without compromising performance.
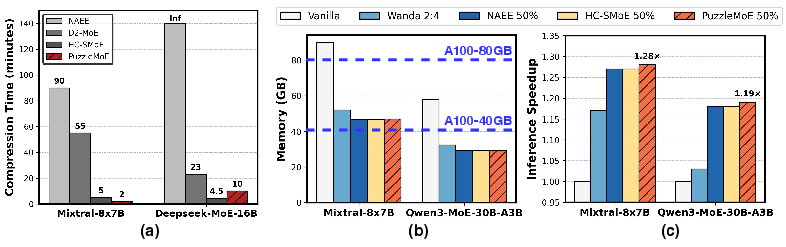
Figure 4: System performance for different MoE models and tasks.
Implications
The practical implications of PuzzleMoE are profound given its ability to significantly reduce the memory footprint of large MoE models while maintaining, and often enhancing, predictive accuracy across several tasks. This method greatly enhances the deployability of large-scale LLMs on memory-constrained hardware. Theoretically, it expands understanding of model compression techniques, merging methods, and efficient computation designs integral to LLM operations.
Conclusion
PuzzleMoE introduces a paradigm shift in compressing MoE models efficiently, merging weights at an entry-level for reduced memory usage without performance penalties. By embedding mask data directly into the model weights, it maximizes both memory efficiency and inference speed. Future research could explore further optimization of expert specialization and alternative architectures leveraging sparse experts. PuzzleMoE stands as a formidable asset for deploying sophisticated models efficiently in real-world scenarios.

