- The paper proposes MLPO, a novel training method where a leader LLM coordinates multiple agents to synthesize improved solutions.
- The methodology iteratively refines candidate answers through leader-agent interactions, enhancing performance on datasets like BBH, MATH, and MMLU.
- Experimental results show that MLPO-trained leaders outperform single-agent baselines in accuracy and efficiency, demonstrating practical impact.
How to Train a Leader: Hierarchical Reasoning in Multi-Agent LLMs
Introduction
The research paper introduces a hierarchical multi-agent framework to enhance the reasoning capabilities of LLMs. This model trains a single leader LLM to coordinate a team of untrained peer agents, addressing computational inefficiencies present in existing multi-agent LLM systems. The proposed Multi-agent guided Leader Policy Optimization (MLPO) method allows the leader to evaluate and synthesize responses from agent models to improve performance on both collaborative and zero-shot settings.
Methodology
Multi-Agent Inference Pipeline
The methodology utilizes a unique hierarchical architecture, involving:
- Leader LLM: A single trained LLM that synthesizes outputs from peer agents.
- Agent Team: Composed of K off-the-shelf LLMs tasked with generating candidate solutions.
The inference process unfolds through iterative communication rounds between the agents and the leader. Initially, each agent generates a solution to a given prompt. The leader takes these initial solutions, synthesizes a new, improved answer, and this process reiterates to refine the final output.
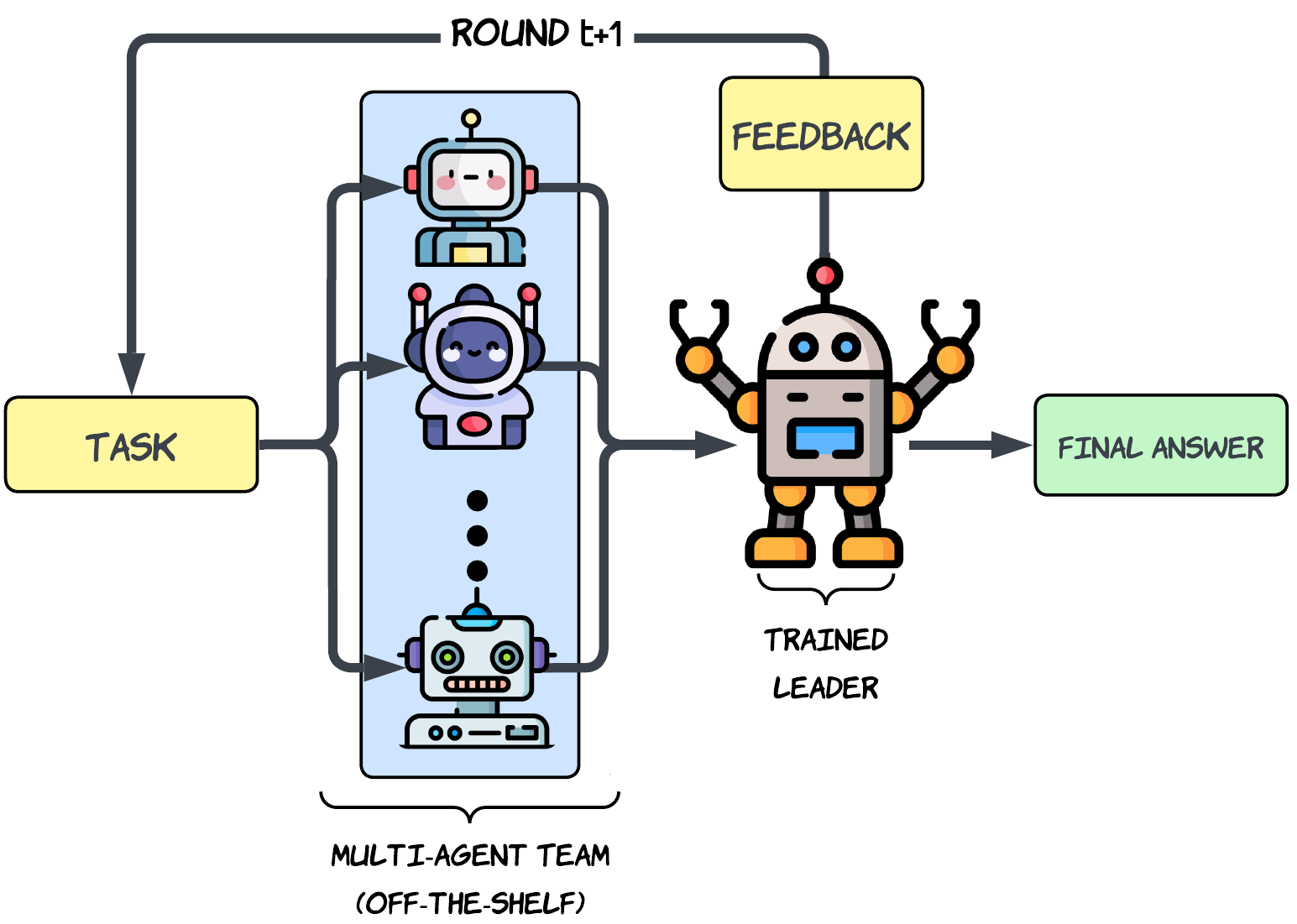
Figure 1: Overview of the proposed hierarchical multi-agent inference architecture. A user prompt is first processed by a team of K off-the-shelf agents whose intermediate generations are forwarded to a leader model trained using our MLPO pipeline.
Training Procedure
Supervised Fine-Tuning (SFT): Develops the leader's natural backtracking and self-correction capabilities through a set of selected leader and agent-generated responses.
GRPO-based MLPO: The novel training phase utilizes Group Relative Policy Optimization to enhance collaboration skills of the leader. The leader is trained using diverse agent solutions during MLPO, which guide it through an exploratory solution space.
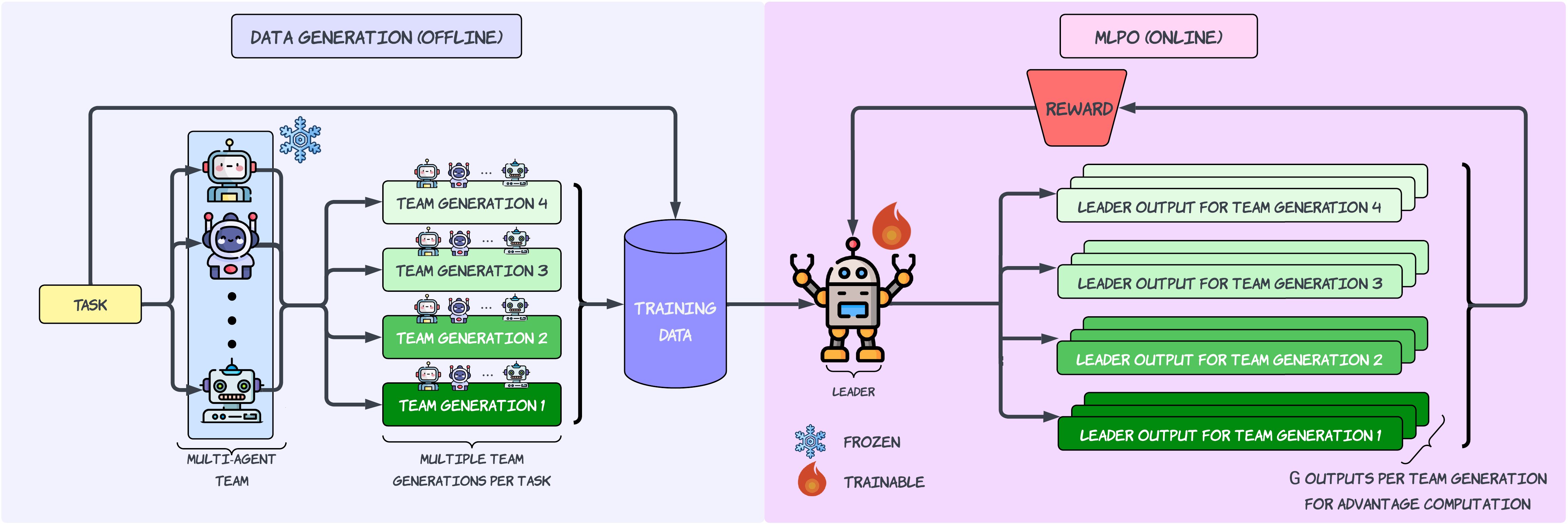
Figure 2: Outline of our Multi-agent guided Leader Policy Optimization (MLPO) pipeline.
Experimental Results
The empirical analysis covers datasets like Big-Bench Hard (BBH), MATH, and MMLU, showcasing substantial performance improvements over existing multi-agent approaches.
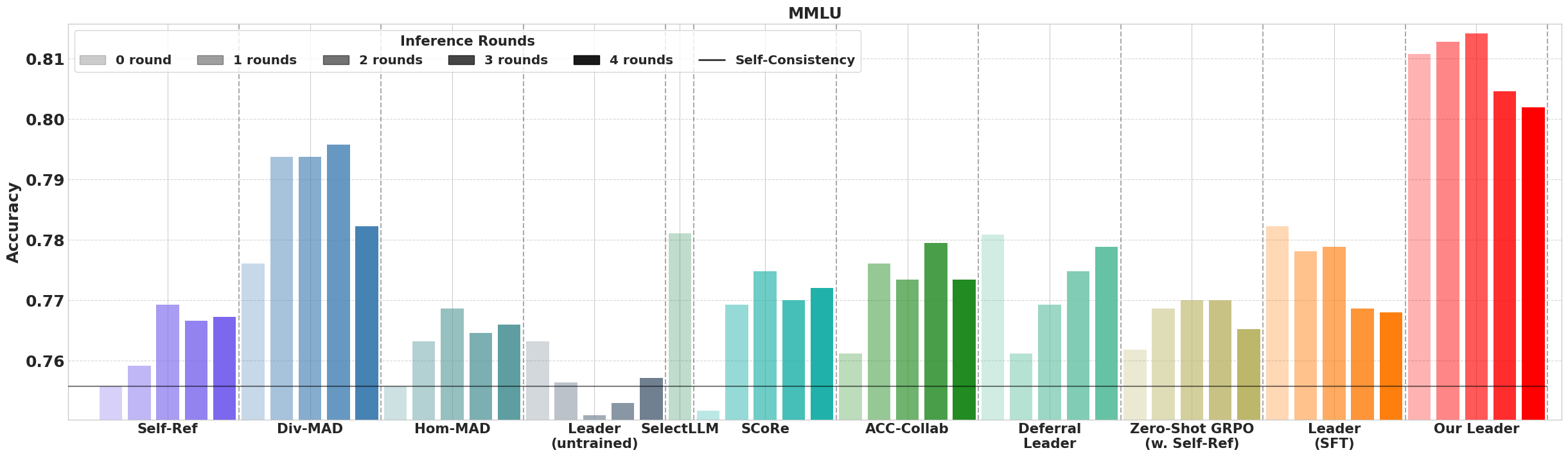
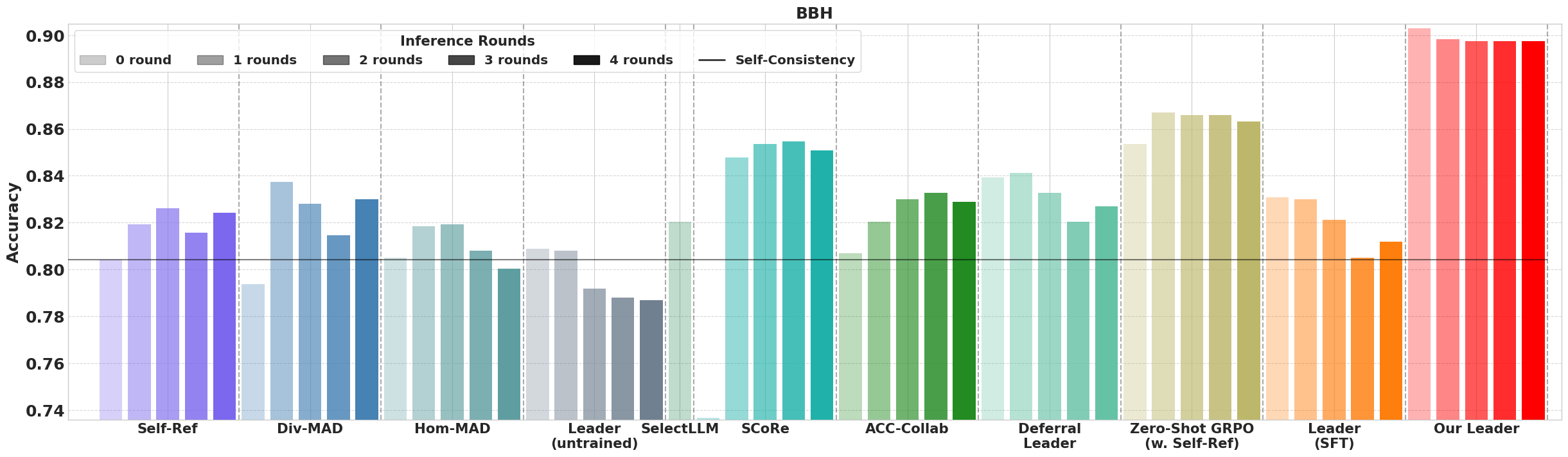
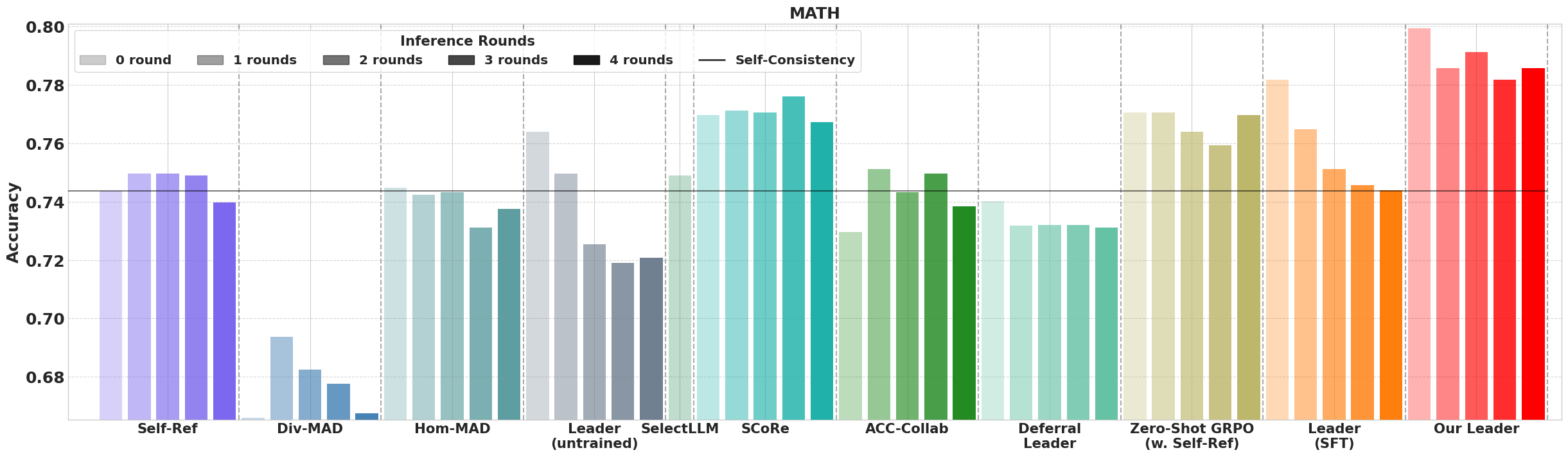
Figure 3: Majority vote performance when each method can use at most 40 total LLM generation samples.
Performance metrics confirmed that MLPO-trained leaders outperform both in zero-shot settings and in multi-agent collaboration scenarios, achieving higher accuracy and efficiency when compared against single-agent baselines.
Enhanced Zero-Shot Capabilities
Remarkably, despite training for collaborative tasks, the leader trained with MLPO demonstrated improved zero-shot inference capabilities, surpassing state-of-the-art zero-shot LLMs without additional inference-time costs.
Team and Leader Interaction Dynamics
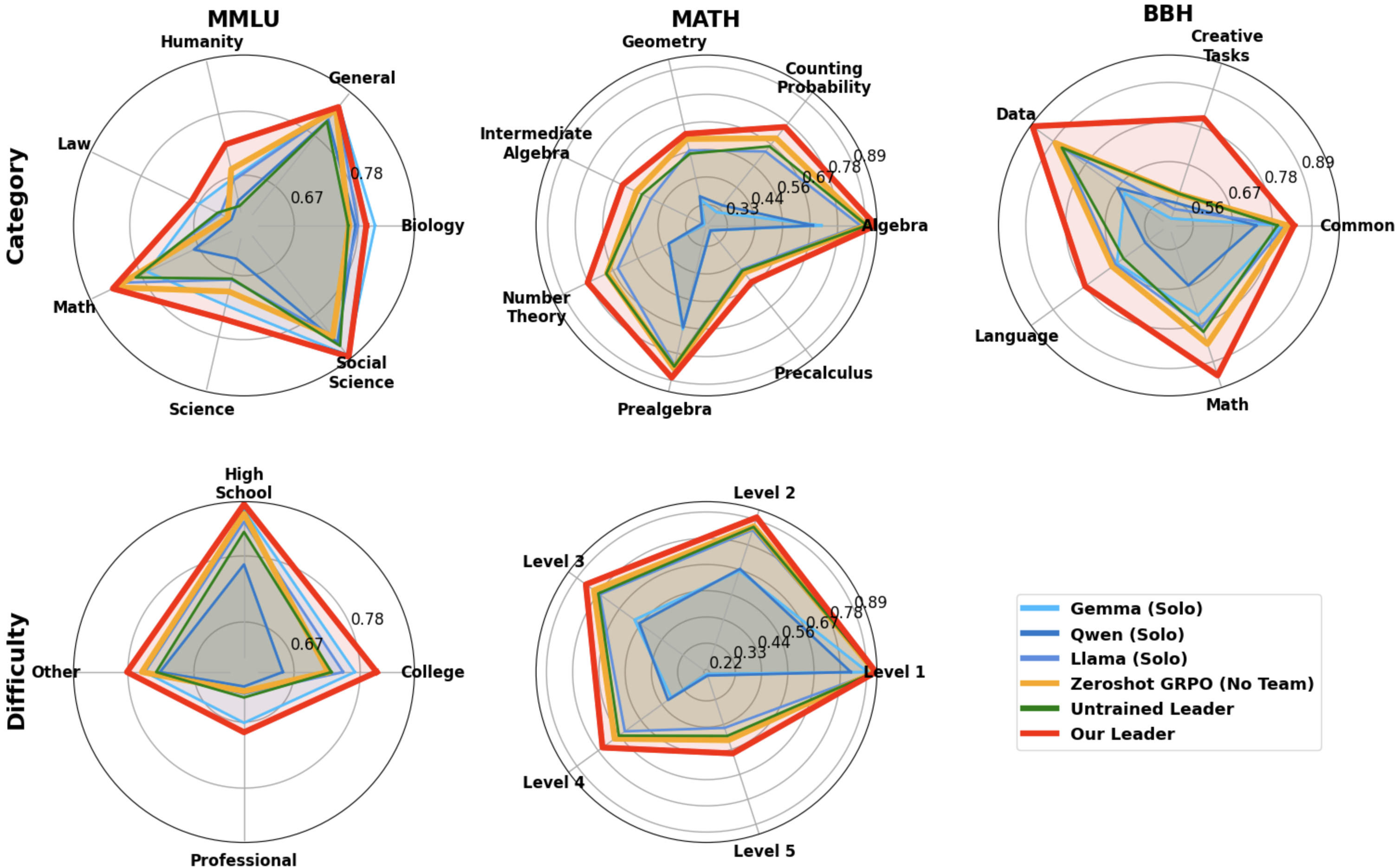
Figure 4: Our leader trained with MLPO, compared with an untrained leader, to zero-shot GRPO, and individual team performance, per category (top) and difficulty level (bottom) on MMLU (left) MATH (center) and BBH (right).
The dynamically trained leader effectively utilizes diverse insights, optimizing performance based on the combined strength of agent solutions.
Conclusion
The hierarchical multi-agent framework, led by a single trained leader LLM utilizing MLPO, offers an effective and computationally efficient method for reasoning tasks. While the model adapts well to complex scenarios by blending individual agent insights, potential advancements could focus on iterative training strategies and refined agent diversity. The leader-agent hierarchy remains a promising avenue for further research in collaborative LLM applications.

