- The paper introduces a capability-based taxonomy that shifts evaluation from task-specific benchmarks to a more holistic assessment of LLM skills.
- It details automated methods for dataset curation and LLM-as-a-judge evaluation, highlighting challenges such as data contamination and evaluator biases.
- The survey identifies the evaluation generalization problem and proposes forward-looking metrics like the Model Utilization Index (MUI) for enhanced performance insights.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Introduction: The Evaluation Paradigm Shift
The paper "Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks" systematically analyzes the evolving landscape of evaluation for LLMs, identifying two pivotal transitions: (1) from task-specific to capability-based evaluation, and (2) from manual to automated evaluation. The authors argue that these transitions are necessary but insufficient, as the core challenge remains the evaluation generalization issue—how to assess models with unbounded capabilities using inherently bounded test sets.
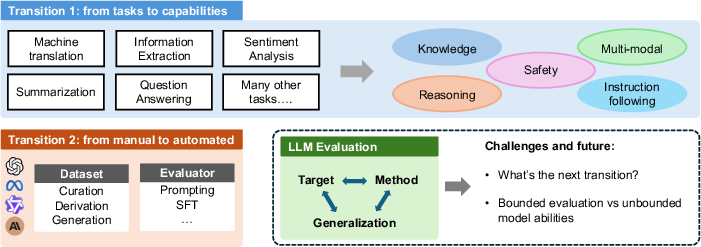
Figure 1: Two major transitions in LLM evaluation: from task-specific to capability-based, and from manual to automated evaluation.
From Task-Specific to Capability-Based Evaluation
Traditional NLP evaluation focused on discrete tasks (e.g., classification, extraction), but LLMs have blurred task boundaries by unifying tasks as natural language generation. The paper proposes a capability-based taxonomy, organizing evaluation around five core competencies: knowledge, reasoning, instruction following, multimodal understanding, and safety.
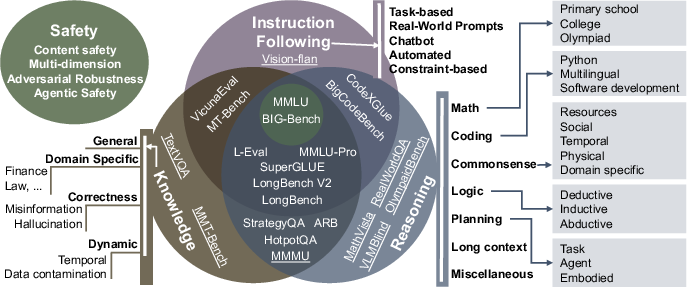
Figure 2: Capability-based benchmark taxonomy, highlighting the interplay and overlap among knowledge, reasoning, instruction following, multimodal, and safety evaluation.
Knowledge Evaluation
Knowledge evaluation has evolved from breadth (general world knowledge) to depth (domain-specific expertise), with increasing attention to challenges such as hallucination and the dynamic nature of knowledge. The survey details the limitations of static datasets and the need for dynamic, contamination-free benchmarks.
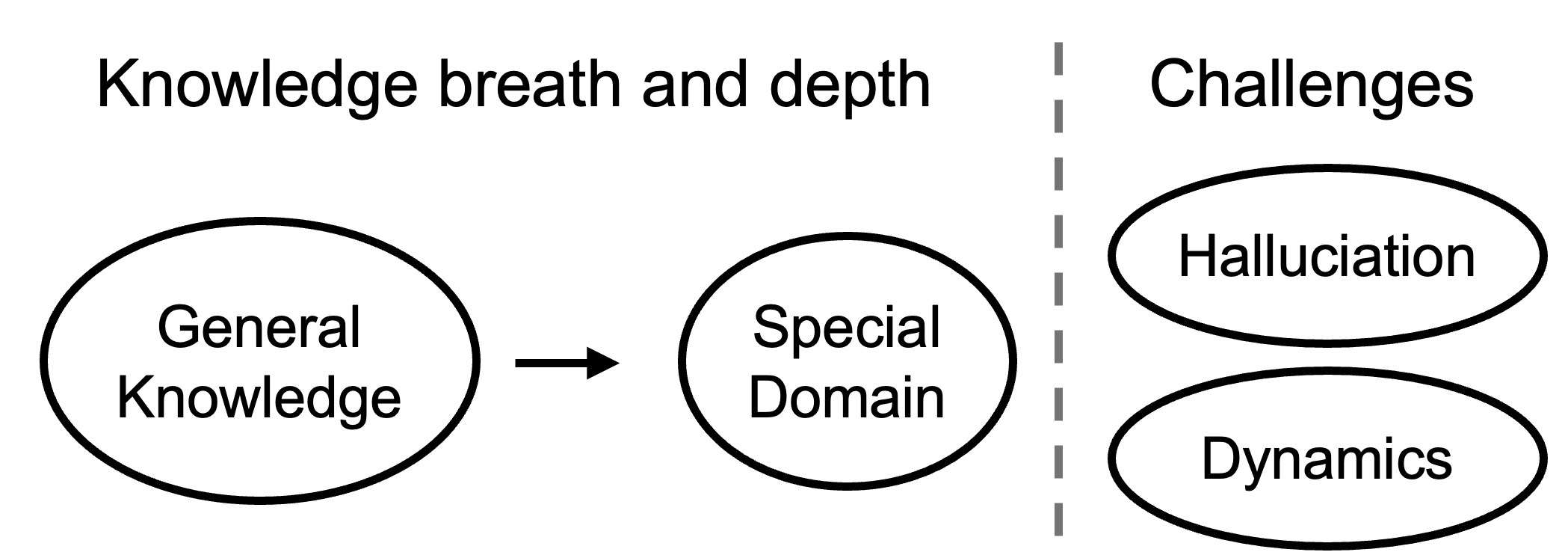
Figure 3: Schematic of the logic underlying knowledge evaluation, emphasizing the need for both breadth and depth.
Reasoning Evaluation
Reasoning is decomposed into mathematics, coding, logic, commonsense, long-context, planning, and miscellaneous reasoning. The paper highlights the rapid escalation in benchmark difficulty, especially in mathematics, where datasets now span from primary school to Olympiad and research-level problems.
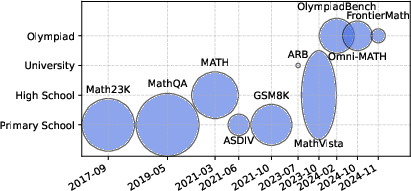
Figure 4: Chronological progression of mathematics benchmarks, showing increasing difficulty and dataset size.
Coding benchmarks are similarly categorized by language and task, with a strong emphasis on Python and code generation, but also including multilingual and software lifecycle tasks.
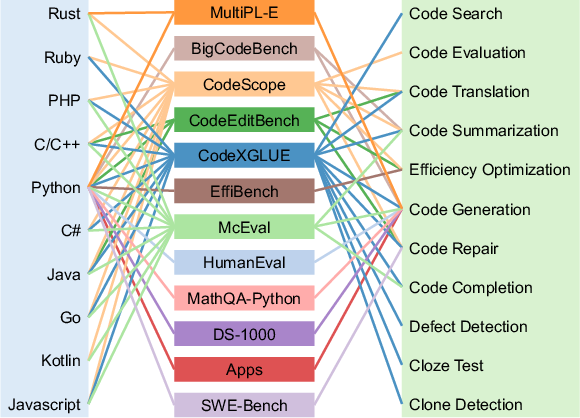
Figure 5: Coding benchmarks categorized by programming language and task type, illustrating the diversity and focus areas.
Instruction Following
Instruction following has shifted from multi-task generalization (task descriptions as instructions) to user-driven, open-ended prompts, necessitating new evaluation paradigms that can handle fine-grained, real-world instructions.
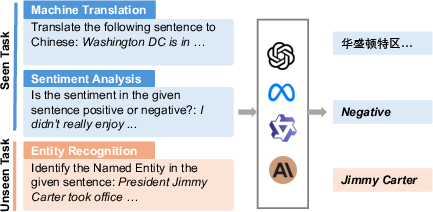
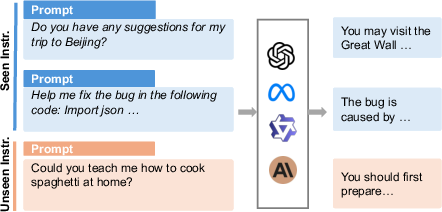
Figure 6: Paradigm shift in instruction following, from task-based to user-need-driven evaluation.
Multimodal and Safety Evaluation
The survey covers the expansion of evaluation to multimodal tasks (e.g., VQA, document understanding, multi-image reasoning) and the increasing complexity of safety evaluation, which now includes content safety, trustworthiness, adversarial robustness, and agentic safety.
From Manual to Automated Evaluation
The second major transition is the move from manual dataset curation and human judgment to automated, LLM-driven pipelines. The paper details the limitations of static, human-annotated datasets—chiefly, their inability to keep pace with model progress and their vulnerability to data contamination. Dynamic benchmarks and live leaderboards (e.g., LiveBench, Chatbot Arena) are presented as partial solutions, but the authors emphasize the need for robust, automated dataset curation and evaluation.
Automated Dataset Curation
The survey categorizes automated dataset construction into compilation, derivation, and generation, with a strong focus on LLM-based generation for both data and evaluation labels. The authors note that while LLMs can efficiently generate and annotate data, the quality ceiling is bounded by the generator's own capabilities, and verification of synthetic data remains a challenge.
Automated Evaluation and LLM-as-a-Judge
The paper provides a formal definition of LLM-as-a-Judge, encompassing pointwise, pairwise, and listwise evaluation, and surveys prompt engineering, multi-evaluator collaboration, human-LLM collaboration, and fine-tuning strategies for robust evaluators. The authors highlight persistent biases (position, knowledge, style, format) and propose ensemble and cascade architectures to mitigate these issues.
The Evaluation Generalization Problem
A central thesis is the "evaluation generalization issue": as LLMs scale, their capabilities outpace the coverage of any fixed test set. The paper identifies three core directions for addressing this:
- Predictive Evaluation: Leveraging scaling laws and performance extrapolation to forecast future model capabilities and design forward-looking benchmarks.
- Adaptive and Diverse Datasets: Moving toward adaptive, model-specific evaluation that iteratively probes model weaknesses, inspired by adaptive testing in education and adversarial red-teaming in safety.
- Generalizable Metrics and Interpretability: Introducing metrics such as the Model Utilization Index (MUI), which combines performance with interpretability signals (e.g., internal effort), to infer latent capabilities beyond observed outcomes.
Integrated and Holistic Evaluation
The survey emphasizes the need for integrated benchmarks that assess the interplay among core capabilities, as real-world tasks rarely exercise skills in isolation. The authors discuss the limitations of both fine-grained and holistic evaluation, noting that agent-based and interactive benchmarks offer more realistic assessments but introduce new challenges in scalability and interpretability.
Open Challenges and Future Directions
The paper identifies several open challenges:
- Efficiency vs. Generality: Balancing comprehensive coverage with practical evaluation costs.
- Granularity vs. Integration: Deciding between fine-grained skill assessment and holistic, real-world task evaluation.
- Automation Quality Ceiling: Overcoming the limitations of LLM-generated data and evaluators, especially as models and tasks become more complex.
- Generalizability: Designing evaluation protocols and metrics that can anticipate and extrapolate to future, as-yet-unseen model behaviors.
The authors speculate that future evaluation pipelines will require a hybrid toolbox: dynamic, adaptive datasets; ensembles of specialized evaluators; and explainable, process-oriented metrics that can "see the whole from a part." They also highlight the importance of community-driven, living repositories to keep pace with the rapid evolution of both models and evaluation methodologies.
Conclusion
This survey provides a comprehensive, critical analysis of the current state and future directions of LLM evaluation. By reframing evaluation around core capabilities, advocating for automation, and foregrounding the generalization problem, the paper sets the agenda for the next generation of evaluation research. Addressing these challenges will require advances in dataset construction, evaluator design, interpretability, and adaptive, model-specific assessment. The implications are significant for both the development and deployment of LLMs, as robust, generalizable evaluation is essential for ensuring meaningful, reliable, and fair performance claims in the era of rapidly advancing AI.