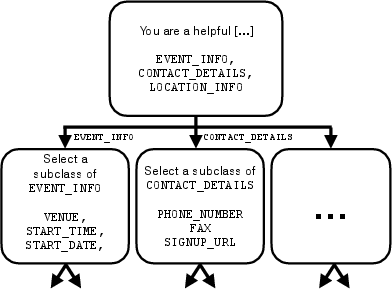
- The paper demonstrates a significant performance gap between LLMs trained on public data and their effectiveness in real-world enterprise integration tasks.
- It introduces the Goby benchmark derived from proprietary enterprise events and utilizes iterative class learning and ontology synthesis to improve annotation accuracy.
- Hierarchical methods, notably tree serialization, achieve full coverage of ground-truth classes, highlighting a viable path to adapt LLMs for complex data integration.
Introduction
"Mind the Data Gap: Bridging LLMs to Enterprise Data Integration" addresses a severe gap between published experimental results for LLMs in data integration and their actual enterprise applicability. The prevalence of benchmarking on public data has systematically overestimated LLMs' effectiveness at practical data management tasks in real, heterogeneous, and proprietary enterprise environments. This paper establishes the Goby benchmark, derived from a large-scale industrial event aggregation pipeline, and analyzes the specific failure modes of LLMs on enterprise datasets. The authors develop and validate hierarchical annotation, iterative class learning, and ontology synthesis techniques to align LLM performance on enterprise data with performance previously achievable only on public data.
The Data Gap in LLM-based Data Integration
The recent literature in data discovery, table understanding, and integration has largely relied on benchmarks such as VizNet and T2Dv2, built from open data consisting of government or wiki tables. These resources feature high label redundancy, single-domain semantics, and emphasize idiosyncratic but publicly recognized entities and structures. Enterprise datasets, in contrast, are characterized by long-tailed, business-specific entity types, heterogeneous schemas, and proprietary label taxonomies. As a direct consequence of their public origin, state-of-the-art LLMs such as GPT-3.5 and Llama2, trained almost exclusively on public domain web data, are unsuitable—without further adaptation—for many mission-critical data integration tasks within the enterprise.
Empirical evaluation on the Goby dataset demonstrates a substantial performance gap for semantic column type annotation compared to state-of-the-art public benchmarks, with LLM macro-averaged F1 reduced by $0.18$, precision by $14.1$ points, and recall by $18.8$ points.
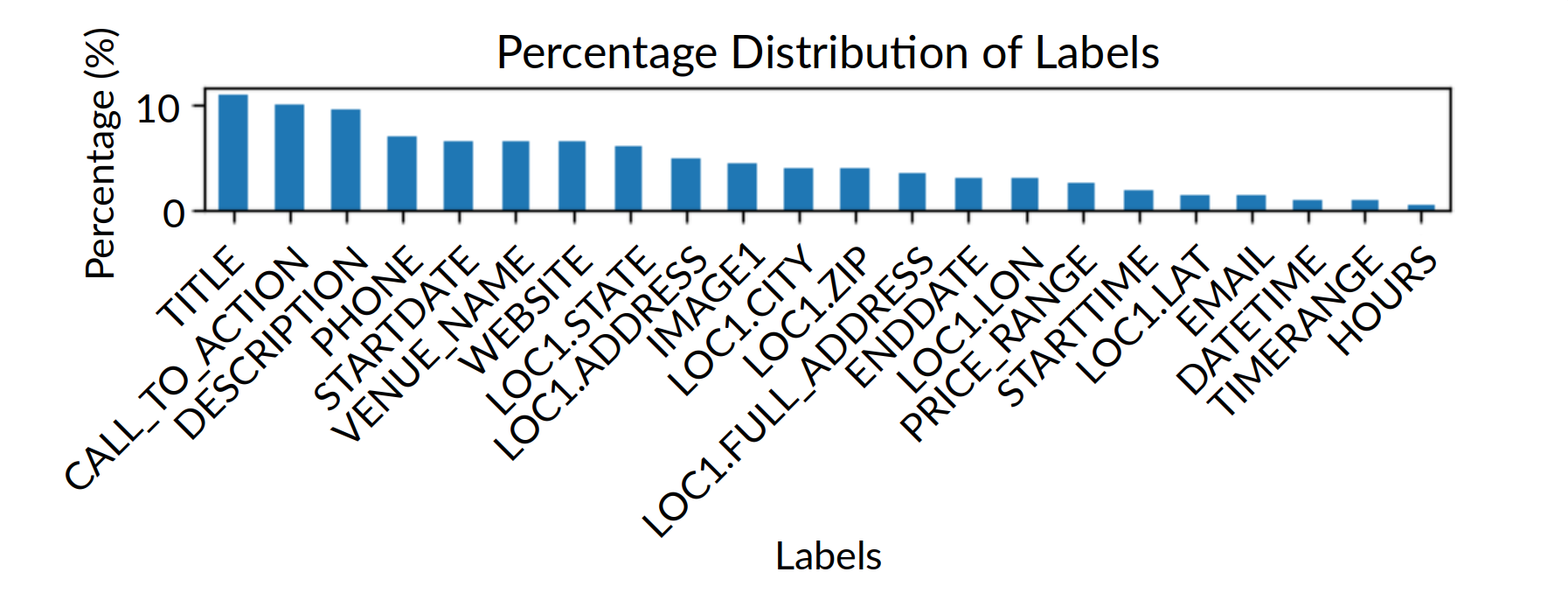
Figure 1: Semantic column label distribution in the Goby dataset, exhibiting rich, enterprise-specific semantic types absent from public benchmarks.
The Goby Benchmark: Design and Motivation
The Goby benchmark is constructed from an operational pipeline aggregating over 4 million events from ~1200 source tables generated by custom wrappers for diverse APIs. Unlike public benchmarks, Goby exhibits realistic table cardinalities, business-centric schemas, and a rich ontology of event-specific semantic labels. Around 40% of columns are labeled with semantic types drawn from a multi-level hierarchy built by subject matter experts. Labels are both more granular and more semantically meaningful than the majority-vote classes (e.g., id, name, type) that dominate public corpora.
The label frequency distribution (see Figure 1) is highly skewed toward complex business concepts (e.g., venue, organizer, activity type) and reflects realistic business needs and integration requirements.
Core Failures and Hierarchical Solutions
Iterative Dictionary and Ontology Construction
A key failure mode of LLMs on enterprise data is the inability to consistently generalize to proprietary or organization-specific types. Direct prompting to map columns to types achieves only 70–72% recovery of ground-truth classes, with a significant share of label failures due to granularity mismatches or semantic ambiguity. The authors introduce an iterative process of class label synthesis—LLMs are prompted with samples of column values and must decide (1) if a suitable class exists, (2) whether to create a new label, and (3) when the current set is quiescent. Coverage improves, but single-level dictionaries are insufficient.
To resolve failures at finer and coarser semantic resolutions, the paper implements a hierarchy-building procedure: classes discovered by the LLM are further clustered into superclasses, yielding a tree-structured ontology and an explicit label mapping.
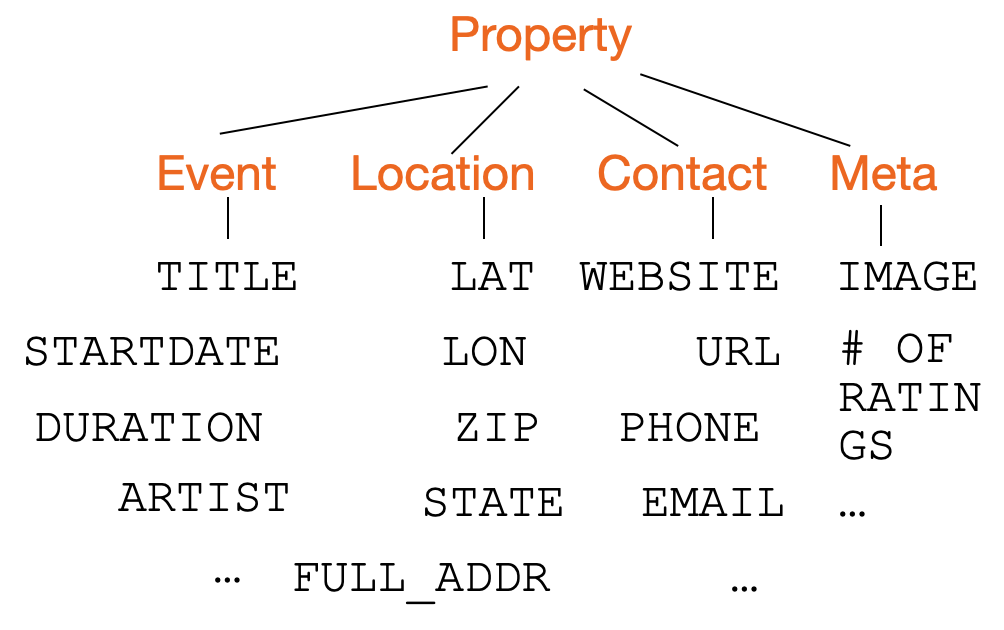
Figure 2: Example of the synthesized ontology, showing iteratively learned base classes (black) linked to super-classes (orange) and their relations—fully capturing ground-truth label diversity.
Hierarchical label induction reaches 100% coverage of the human-labeled ground-truth classes, resolving label multiplicity and synonymy.
Architectural Variants for Ontology Integration
The deployment of hierarchical semantic information in LLM inference is non-trivial. The authors benchmark three integration strategies:
Tree serialization yields the highest F1 at 0.85, outperforming grammar-constrained decoding (F1: 0.66) and stepwise reasoning (F1: 0.76), illustrating that in-context access to full hierarchical structure enables better discriminative predictions, particularly in datasets with dense type overlap and subtle distinctions.
Practical and Theoretical Implications
Dataset Shift and Data Contamination
The observed LLM performance gap is dissected into two mechanisms: data contamination (shared test/train artifacts via public crawl) and distribution shift (enterprise data is simply outside the training support of web-scale LLMs). The analysis is nuanced: while public LLM pretraining may inadvertently absorb public benchmarks, cutting-edge studies reveal that even recently-collected public data, temporally excluded from training, is still markedly easier than proprietary enterprise content. This is compounded by LLMs' memorization of high-frequency sequences but poor accuracy on long-tailed, domain-specific, or private entities.
Cost and Scalability
Deployment of LLM-based data integration at enterprise scale presents both computational and financial challenges. Typical enterprise data lakes have table and row counts several orders of magnitude greater than those of public benchmarks. Context window bottlenecks in LLMs preclude exact solutions for full-table in-context tasks. Therefore, efficient table summarization (for both accuracy and inference cost) becomes a critical bottleneck—one not addressed in contemporary public benchmarks.
Notably, the best-performing (tree-serialization) integration method is also the most expensive in terms of context window usage, demonstrating a persistent scalability/open-set generalization trade-off.
Conclusions
This paper provides a rigorous, data-driven analysis of why LLMs have failed to close the gap between academic and enterprise data integration needs—contradicting the conventional wisdom suggested by public-benchmark leaderboards. The research introduces a new, fully-realistic benchmark; demonstrates robust performance declines for LLMs on this data (even with label supervision); and establishes a hierarchy-based approach, culminating in ontology synthesis and context-rich tree serialization, as a viable path to bridge this gap.
These techniques should now be considered baseline methodology for any deployment of LLMs in production-grade data integration and curation. Furthermore, these results highlight the necessity for continued work on scalable summarization, hierarchical attention, and domain adaptation to enable LLM-based methods as true general-purpose solutions for enterprise data unification. Future work may integrate retrieval-augmented generation or hybrid neuro-symbolic reasoning to further close the distributional and semantic gap discovered herein.