- The paper presents a two-dimensional taxonomy for evaluating LLM agents by distinguishing evaluation objectives from evaluation processes.
- It details various dimensions such as task completion, tool use, planning, and safety to benchmark agent performance across diverse scenarios.
- The survey identifies enterprise challenges and outlines future research directions, emphasizing scalable and realistic evaluation methods.
Evaluation and Benchmarking of LLM Agents: A Comprehensive Survey
Introduction
The proliferation of LLM-based agents has catalyzed a paradigm shift in AI, enabling systems that autonomously reason, plan, act, and interact with complex environments. However, the evaluation of these agents presents unique challenges that are not addressed by traditional LLM or software evaluation methodologies. The paper "Evaluation and Benchmarking of LLM Agents: A Survey" (2507.21504) provides a systematic framework for understanding and organizing the rapidly evolving landscape of LLM agent evaluation. It introduces a two-dimensional taxonomy that distinguishes between evaluation objectives (what to evaluate) and evaluation processes (how to evaluate), and further highlights enterprise-specific challenges and future research directions.
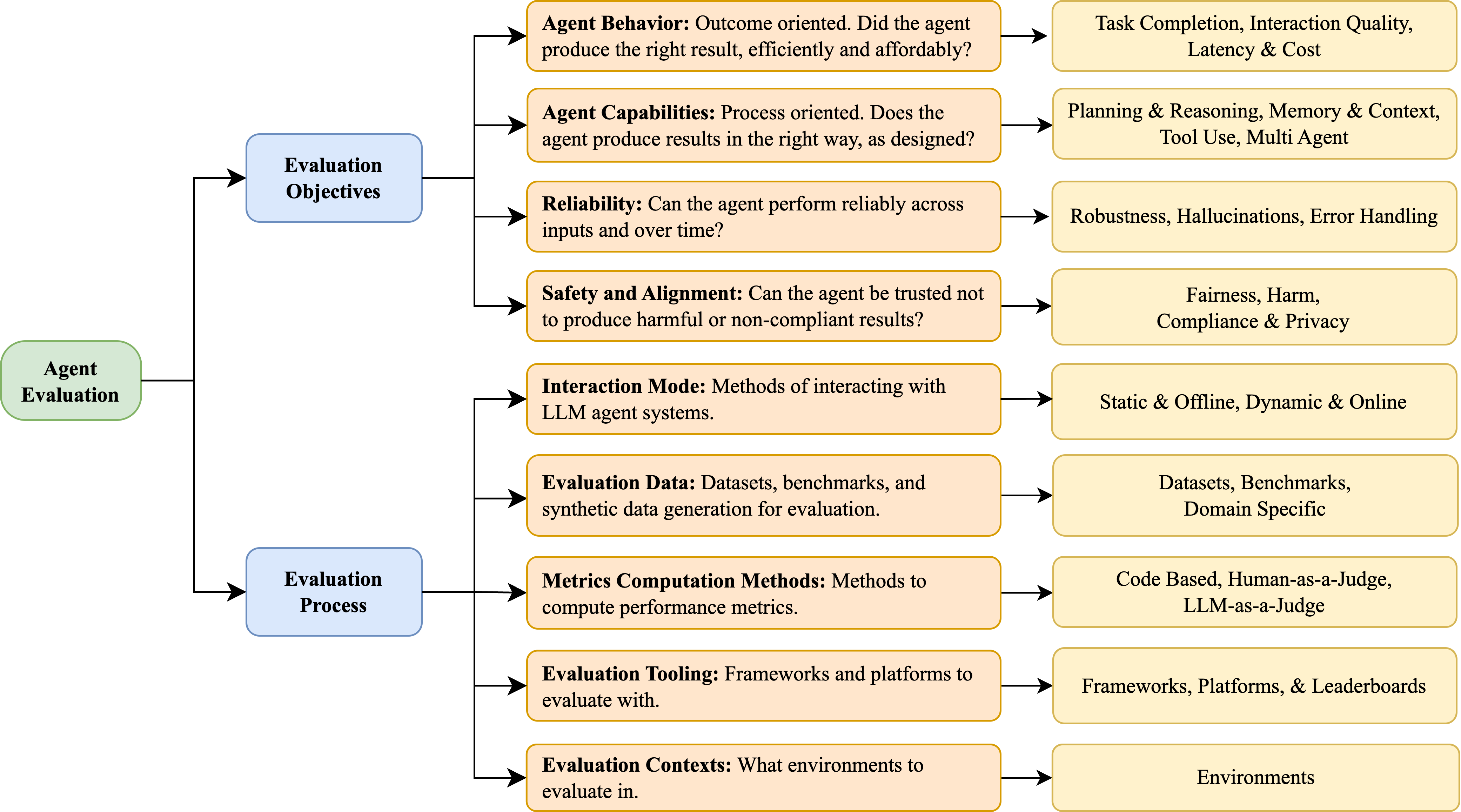
Figure 1: Taxonomy of LLM Agent Evaluation, illustrating the two-dimensional structure of evaluation objectives and processes.
Taxonomy of LLM Agent Evaluation
The core contribution of the survey is a hierarchical taxonomy that structures the evaluation of LLM agents along two axes:
- Evaluation Objectives: What aspects of the agent are being evaluated (behavior, capabilities, reliability, safety/alignment).
- Evaluation Process: How the evaluation is conducted (interaction mode, data, metrics, tooling, context).
This taxonomy enables systematic comparison and analysis of LLM agents across diverse goals, methodologies, and deployment conditions. It is designed to be extensible to new agent capabilities (e.g., multimodal, multilingual, multi-agent) and adaptable to both research and enterprise settings.
Evaluation Objectives
Agent Behavior
Agent behavior is assessed from a black-box perspective, focusing on user-perceived outcomes:
- Task Completion: Measured by metrics such as Success Rate (SR), Task Goal Completion, and Pass@k. These are widely used in benchmarks for coding (SWE-bench), scientific workflows (ScienceAgentBench), and web navigation (WebArena, BrowserGym).
- Output Quality: Encompasses accuracy, relevance, fluency, coherence, and adherence to specifications. Metrics from LLM evaluation (e.g., fluency, logical coherence) and RAG systems (e.g., factual correctness) are applicable.
- Latency and Cost: Latency (e.g., Time To First Token, end-to-end request latency) and token-based cost are critical for real-time and scalable deployments.
Agent Capabilities
Evaluation of internal agent competencies provides granular insight into agent strengths and weaknesses:
- Tool Use: Assessed via invocation accuracy, tool selection accuracy, retrieval accuracy (MRR, NDCG), and parameter name/value correctness. Execution-based evaluation is increasingly favored over static AST checks to capture semantic correctness.
- Planning and Reasoning: Evaluated using plan similarity, node/edge F1, normalized edit distance, and step success rate. Dynamic, interleaved planning and execution (e.g., ReAct paradigm) require metrics that capture real-time decision quality.
- Memory and Context Retention: Benchmarks such as LongEval and SocialBench test long-horizon context retention, with metrics like factual recall accuracy and consistency score.
- Multi-Agent Collaboration: Metrics include collaborative efficiency, information sharing effectiveness, and adaptive role switching, reflecting the agent's ability to coordinate in decentralized, language-mediated settings.
Reliability
Reliability is essential for production and safety-critical applications:
- Consistency: Measured by pass@k and the stricter passk (success in all k trials), as formalized in the τ-benchmark.
- Robustness: Assessed by stress-testing with perturbed inputs, environmental changes, and error injection. Metrics include task success rate under perturbation and error-handling rate.
Safety and Alignment
Safety evaluation addresses ethical, legal, and policy compliance:
- Fairness and Explainability: Metrics include violation rate, transparency, and risk awareness. Domain-specific frameworks (e.g., AutoGuide, FinCon) are used for regulated industries.
- Harm, Toxicity, and Bias: Evaluated using adversarial prompts (e.g., RealToxicityPrompts, CoSafe), with metrics such as toxicity rate and adversarial robustness.
- Compliance and Privacy: Domain-specific test cases and metrics ensure adherence to regulatory and organizational policies.
Evaluation Process
Interaction Mode
- Static/Offline Evaluation: Uses pre-generated datasets and test cases. While cost-effective, it may not capture the full behavioral spectrum of agents.
- Dynamic/Online Evaluation: Involves live simulations, user interactions, or reactive environments. This mode is essential for uncovering issues not observable in static settings and is central to Evaluation-driven Development (EDD).
Evaluation Data
A diverse ecosystem of benchmarks and datasets has emerged:
- Structured Benchmarks: ScienceAgentBench, TaskBench, API-Bank, and others provide expert-labeled, domain-specific tasks.
- Interactive Environments: WebArena, AppWorld, and AssistantBench simulate open-ended, long-horizon agent behaviors.
- Safety and Robustness: AgentHarm, AgentDojo, and similar datasets target adversarial and failure scenarios.
Metrics Computation Methods
- Code-Based Evaluation: Deterministic, rule-based checks for tasks with well-defined outputs.
- LLM-as-a-Judge: Scalable, qualitative assessment using LLMs as evaluators, with extensions such as Agent-as-a-Judge for process-level feedback.
- Human-in-the-Loop: Gold standard for subjective and open-ended tasks, but costly and less scalable.
The emergence of agent evaluation platforms (e.g., OpenAI Evals, DeepEval, LangSmith, Arize AI) supports automated, continuous, and reproducible evaluation. These tools are increasingly integrated into agent development pipelines, enabling real-time monitoring and regression detection.
Evaluation Contexts
Evaluation environments range from controlled sandboxes and mocked APIs to live web and enterprise systems. The choice of context is dictated by the agent's intended deployment and risk profile.
Enterprise-Specific Challenges
The survey identifies several challenges unique to enterprise deployment:
- Role-Based Access Control (RBAC): Evaluation must account for user-specific permissions and data access constraints.
- Reliability Guarantees: Enterprises require deterministic, repeatable, and auditable agent behavior, necessitating multi-trial evaluation and robust benchmarking.
- Dynamic and Long-Horizon Interactions: Real-world agents operate over extended periods and must be evaluated for performance drift, context retention, and cumulative effects.
- Compliance and Policy Adherence: Evaluation frameworks must incorporate domain-specific rules, legal requirements, and organizational policies.
Future Research Directions
The paper outlines several open directions:
- Holistic Evaluation: Development of frameworks that jointly assess multiple, interdependent agent competencies.
- Realistic Evaluation Settings: Creation of benchmarks and environments that reflect enterprise workflows, multi-user dynamics, and domain-specific constraints.
- Automated and Scalable Evaluation: Advances in synthetic data generation, simulation, and LLM-based evaluation to reduce human effort and improve reproducibility.
- Time- and Cost-Bounded Protocols: Efficient evaluation strategies that balance depth, coverage, and resource constraints.
Conclusion
This survey provides a rigorous, structured framework for the evaluation and benchmarking of LLM-based agents, addressing both foundational research and practical deployment needs. The proposed taxonomy clarifies the fragmented landscape, enabling systematic assessment and comparison of agentic systems. The identification of enterprise-specific challenges and future research directions highlights the need for holistic, realistic, and scalable evaluation methodologies. As LLM agents become increasingly integrated into critical applications, robust evaluation will be essential for ensuring their reliability, safety, and alignment with human values and organizational requirements.