- The paper presents RAPID, a framework that distills expert knowledge from LLM-generated data to enable adaptive policy learning in autonomous driving.
- It integrates offline data distillation and a robust loss mechanism with a mixture-of-policy strategy to counter distribution shifts and adversarial inputs.
- Experiments on HighwayEnv show that RAPID significantly outperforms DQN and DDQN by enhancing cumulative rewards while ensuring robustness.
Robust RL with LLM-Driven Data Synthesis and Policy Adaptation for Autonomous Driving
This paper presents RAPID, a framework that leverages the reasoning capabilities of LLMs to enhance Reinforcement Learning (RL) in the autonomous driving domain. The RAPID framework is designed to overcome the challenges posed by the inference time and dynamic interaction needs of LLMs, and integrates robust knowledge distillation techniques to build adaptive RL policies.
Framework Design and Components
RAPID Framework Architecture
RAPID introduces a novel framework termed as Robust Adaptive Policy Infusion and Distillation. The focus of RAPID includes robust distillation from LLMs, offline distillation of expert knowledge, and adaptive learning through online interaction.
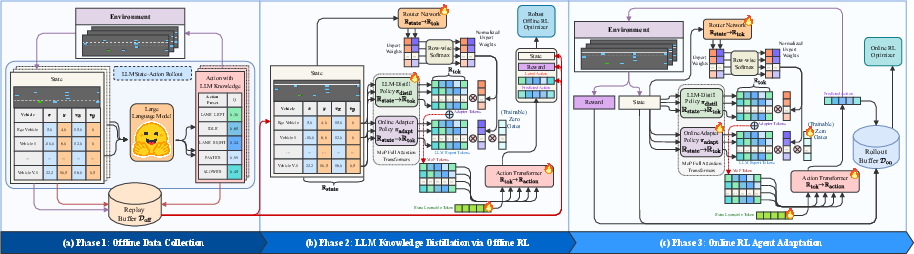
Figure 1: Proposed RAPID framework illustration.
The framework's key components involve three design stages:
- Offline Data Distillation: Utilizing offline data from an LLM agent to distil robust and performance-oriented knowledge into RL policies.
- Robust Distillation: Implementing robust knowledge distillation that maintains both the performance and adversarial robustness of the LLM model.
- Mixture-of-Policy Approach: This involves using a policy adapter to facilitate joint decision-making and dynamic adaptation in the environment.
Offline Dataset Collection
To collect the offline dataset, experiments were conducted on HighwayEnv using GPT-3.5. The LLM was tasked with collecting state-action transitions to form a dataset that includes both standard driving scenarios and edge cases.
Robust Distillation Mechanism
The robust distillation mechanism is designed to address challenges such as distribution shift in the action space during the offline RL phase. A new robust loss term Jrobust is introduced:
Jrobust=J(Q,π,D)+β⋅additional penalty on state misalignment
This loss term aids in aligning the behavior of distilled student policies with the robustness characteristics of the LLM teacher policy.
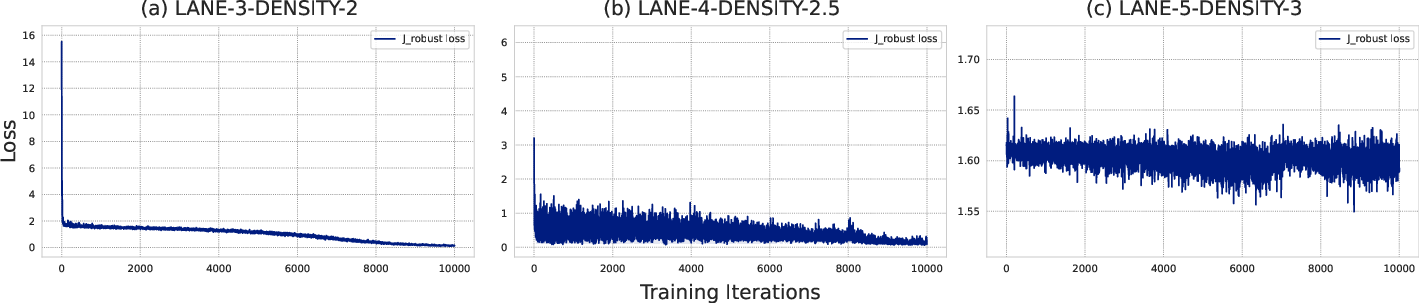
Figure 2: Detailed view of the offline training process with robust distillation.
Online Adaptation and Policy Infusion
Integration with Environment
RAPID uses a mixture-of-policies (MoP) strategy for integrating LLM-derived policies with policies learned directly from interaction, enabling the system to adapt based on real-time input.
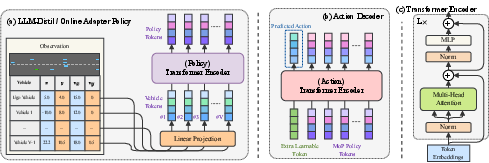
Figure 3: Detailed architecture of policy networks using transformer encoders.
This strategy ensures that while the distilled policy provides a strong base, the adapter policy refines behavior through continued interaction with the environment.
Zero Gating Mechanism
To avoid interference between πdistil and πadapt during offline training, a zero gating mechanism is employed. This mechanism ensures the robustness of adaptation by segregating learned knowledge until needed.
Experimentation and Results
Experiments conducted across various traffic density environments using HighwayEnv demonstrate RAPID's efficacy. The framework consistently outperformed traditional models such as DQN and DDQN, particularly with the combined utilization of LLM-generated datasets and robust distillation.
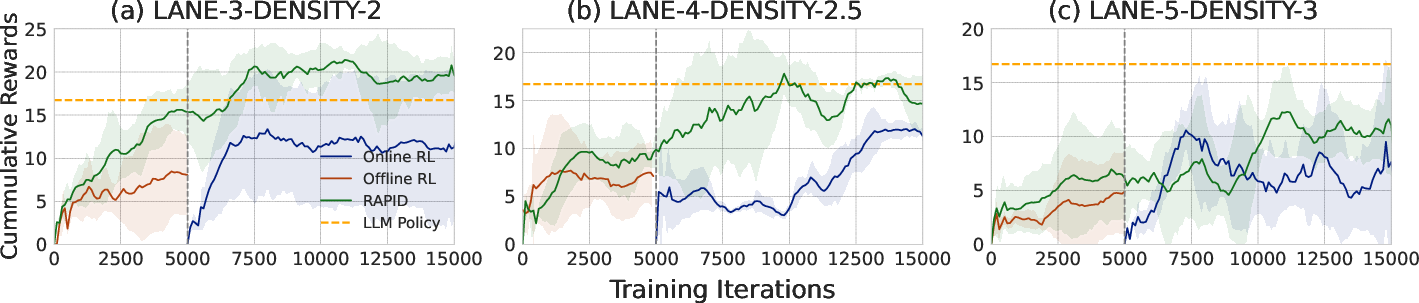
Figure 4: Performance metrics across three different driving environments.
Strong numerical results show that RAPID improves cumulative reward performance significantly while retaining robustness against adversarial attacks.
LLM-Generated Dataset Impact
Augmenting traditional datasets with LLM-generated data results in superior policy performance, especially when the optimal dataset ratio is identified. The framework benefits from the LLM's reasoning capabilities even in unseen environments.
Conclusion
RAPID represents a significant step forward in integrating LLM-derived reasoning and context into RL-driven autonomous systems. The robust distillation and adaptive policy strategies ensure flexibility and reliability in dynamic environments, addressing key challenges in autonomous driving. Future work might explore more complex environments, such as those presented by visually and contextually rich simulators like CARLA.
This innovative approach not only enhances real-time performance but also extends the applicability of RL in practical, real-world scenarios, supported by narratives that are generated through advanced data synthesis and adaptation techniques.

