- The paper introduces a novel prompt-guided visual perception framework that selects key video frames and regions, reducing computational tokens by over 20%.
- The paper achieves competitive performance on benchmarks like MSVD-QA by efficiently sampling both temporal and spatial data without additional training.
- The paper demonstrates significant inference speed gains and lower memory consumption, enabling scalable deployment in resource-constrained settings.
Free Video-LLM: Prompt-guided Visual Perception for Efficient Training-free Video LLMs
The paper "Free Video-LLM: Prompt-guided Visual Perception for Efficient Training-free Video LLMs" presents a novel approach to improve the efficiency of training-free video LLMs by leveraging prompt-guided visual perception techniques. This approach minimizes the computational demands typically associated with processing video data, while retaining high performance across several video understanding benchmarks.
Introduction to Training-Free Video LLMs
Training-free video LLMs traditionally adapt image-based LLMs for video tasks, capitalizing on pre-trained models without further specific video training. These models, while reducing training cost, face significant computational challenges due to the vast number of visual tokens generated by video frames. Handling large sequence lengths increases the complexity and resource requirements of inference operations, primarily in architectures based on transformers, where the quadratic complexity of self-attention becomes a bottleneck.
Prompt-guided Visual Perception Framework
The novel contribution of this paper is the prompt-guided visual perception framework, termed Free Video-LLM, designed to streamline inference operations without any additional training burdens. This method features:
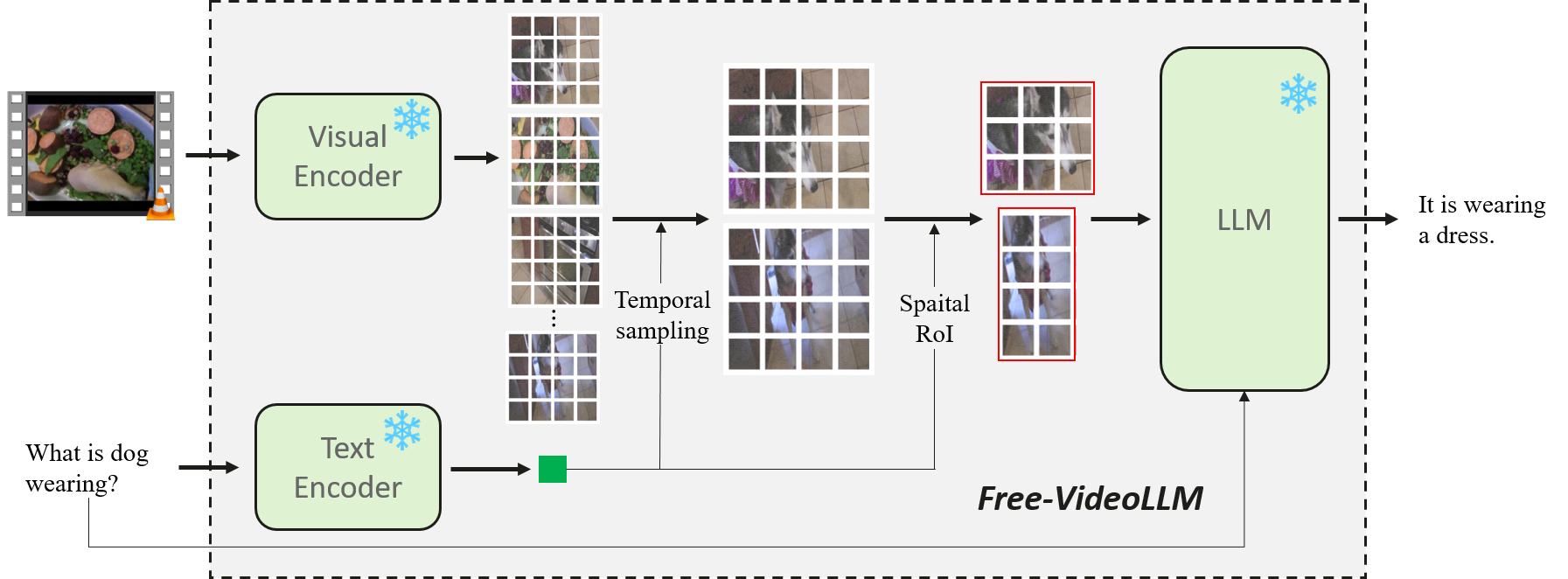
Figure 1: Illustration of the proposed Free Video-LLM with prompt-guided visual perception.
Temporal Frame Sampling and Spatial RoI Cropping
- Temporal Sampling: By employing a task-specific prompt, the system selects relevant frames, pruning unnecessary ones based on their contextual relevance to the prompt. This significantly curtails the number of visual tokens without sacrificing the necessary temporal information.
- Spatial Sampling: For spatial dimension optimization, the framework introduces a region of interest (RoI) cropping strategy, which is driven by the semantic correspondence of visual content and the guiding prompt. Only salient spatial information, as determined by the prompt, is processed, further reducing token congestion.
Results and Evaluation
The proposed framework demonstrates its efficacy across multiple video question-answering benchmarks. The Free Video-LLM achieves competitive performance with significantly fewer processed tokens, showing an optimal balance between accuracy and computational efficiency.
- Quantitative Performance: Against state-of-the-art models like IG-VLM and SF-LLaVA, Free Video-LLM maintains comparable or superior performance on tasks like MSVD-QA and TGIF-QA with over 20% fewer tokens, emphasizing its efficiency improvements.
- Inference Speed: The reduction in visual tokens directly translates to faster inference speeds and lower memory consumption, which holds significant implications for deploying such models in resource-constrained environments.
Implications and Future Directions
The implications of this work are twofold. Practically, it provides a pathway to deploying efficient and scalable video LLMs in real-time applications, where computational resources may be limited. Theoretically, it furthers the understanding of how prompt-based techniques can be used to optimize multi-modal model architectures, suggesting a promising direction for future research in adaptive visual-linguistic modeling.
Future work may explore extending this prompt-guided approach to other multi-modal tasks or refining the granularity of RoI and temporal sampling for even finer efficiency gains.
Conclusion
The Free Video-LLM framework introduces an efficient approach for video understanding tasks, leveraging prompt-guided sampling to significantly reduce computational burdens while achieving high task performance. This work marks an important step towards the scalable application of video LLMs, balancing the demands of high-volume video data processing with technological efficiency.