Assessing Episodic Memory in LLMs with Sequence Order Recall Tasks
(2410.08133v1)
Published 10 Oct 2024 in cs.CL, cs.AI, and cs.LG
Abstract: Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
The paper introduces the Sequence Order Recall Task (SORT) to evaluate LLMs’ ability to recall temporal order in text segments.
It compares methodologies including in-context presentation, fine-tuning, and retrieval augmentation, noting that accuracy declines with longer contexts.
Findings indicate that despite improved performance with in-context methods, current LLM architectures still show limitations compared to human episodic memory.
Episodic Memory Evaluation in LLMs Using Sequence Order Recall Tasks
Introduction and Objectives
LLMs today often employ benchmarks to test their semantic and factual memory, but the important cognitive aspect of episodic memory remains largely unexplored within these models. Episodic memory, which allows individuals to recall the context in which memories were formed, including temporal order, is pivotal for cognitive tasks and predictions. The paper presents the Sequence Order Recall Task (SORT), adapted from cognitive psychology, to investigate the episodic memory capabilities of LLMs. The authors crafted the Book-SORT dataset comprising 36k segment pairs from public domain books, aiming to challenge models in recalling temporal order. Findings from human participants were also documented, presenting an initial reference point for comparison. This paper evaluates several approaches to embedding memory, detailing performance across diverse configurations.
Overview of the Sequence Order Recall Task
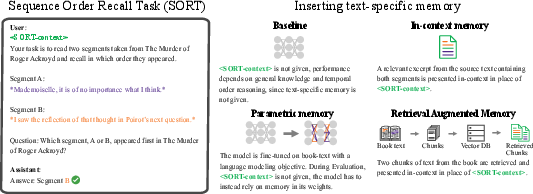
SORT necessitates LLMs to discern the proper sequence order of segments within a book (Figure 1). Importantly, it was designed without resorting to external annotations, making it easily extendable to new datasets.
Figure 1: Overview of the Sequence Order Recall Task (SORT) to evaluate how models can access memory of temporal order.
Participant human trials demonstrated an average accuracy of 70% in recalling sequence order from long-term memory, establishing a baseline for assessment.
Methodology
Formal Description of SORT: The task involves sequential data X∈RT×F, where two non-overlapping segments are extracted. The model Mθ infers which segment appeared first. The general task input is:
Each component of the task is crafted to simulate contextual memory and offer flexible memory insertion methods.
Memory Evaluation Techniques
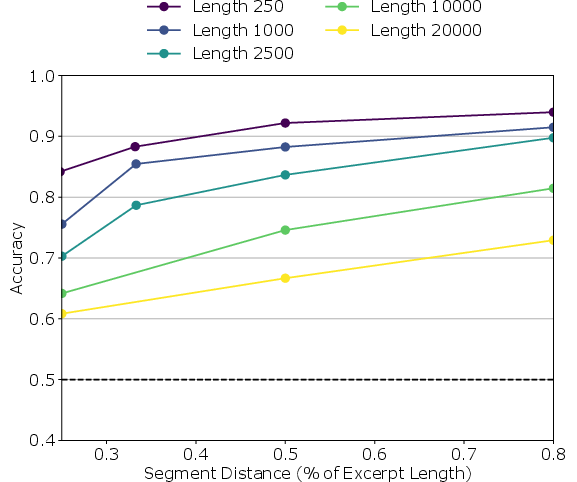
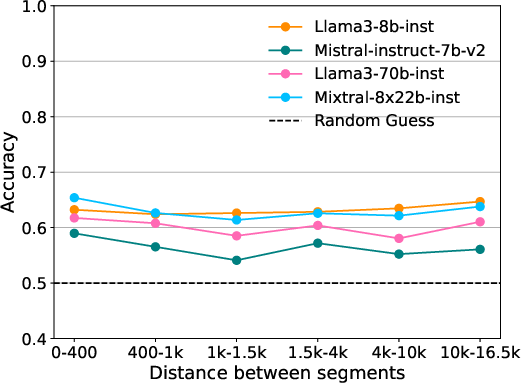
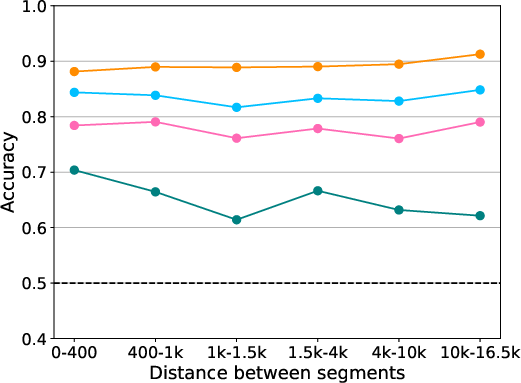
In-Context Presentation: This technique presents relevant book excerpts as context, facilitating sequence order prediction. Models achieved high accuracy, with performance degrading as context length increased (Figure 2).
Figure 2: By excerpt lengths showcasing that accuracy decreases as excerpts length increases.
Fine-Tuning: Full parameter fine-tuning with a LLMing objective did not enhance SORT performance, suggesting current LLM architectures might not adeptly support episodic memory-like functions without context.
Retrieval-Augmented Generation (RAG): Retrieving relevant passages improved recall rates but performed inferiorly to in-context methods. An order-preserving approach showcased potential improvements, reflecting the importance of maintaining temporal order.
Figure 3: Vanilla RAG indicating limitations in recalling sequences properly when using standard RAG models.
Results Analysis
Experiments showcased significant findings:
Human Benchmark: Participants exhibited variable recall proficiency, challenging models to reach comparable accuracy benchmarks.
Model Performance: All in-context memory models surpassed baseline performance, diminishing with increased excerpt lengths.
Model Comparisons: Large models do not necessarily outperform smaller ones; effectiveness hinges on in-context data presentation and order retention.
Discussion on Episodic Memory
The paper explores the associations and divergences between in-context memory in LLMs and human episodic memory systems, highlighting computational limitations inherent in LLMs. Additionally, the paper laid groundwork for future research into episodic-like memory augmentation using advanced learning strategies and architectures, such as separate memory systems.
Conclusion
The introduction of the SORT framework provides a promising avenue for future research in interpreting and enhancing memory capabilities in LLMs. While still confined by architectural and design limitations, the insights gained from this paper pave the way for improvements in how models could integrate holistic memory in future AI developments. Researchers could adopt these methodologies to probe and extend memory functions, fostering advancements in adaptive and intelligent systems integration.