- The paper demonstrates that next-token prediction biases logit matrices toward a sparse plus low-rank structure, distinguishing empirical co-occurrence and support patterns.
- Experimental results reveal that context embeddings with identical support patterns collapse onto the same direction, evidencing a subspace collapse effect.
- A proxy based on centered support matrices efficiently approximates induced geometries, bridging the gap between theory and practical model interpretability.
Implicit Geometry of Next-token Prediction in LLMs
Introduction and Theoretical Framework
This work systematically analyzes the geometric structure implicitly induced on context and word representations by next-token prediction (NTP) objectives in overparameterized LLMs, independent of architectural specifics. The study establishes NTP as a soft-label classification task using sparse probabilistic labels, where the conditional probability of the next token, given a context, is encoded as a sparse vector. Embeddings are treated as unconstrained and the empirical risk minimization is examined in the regime where cross-entropy (CE) loss saturates at the empirical entropy bound. The optimization is recast as a rank-constrained nuclear-norm regularized minimization in logit (pre-softmax) space, facilitating explicit analysis of the logit, word, and context embedding geometries that result from NTP.
The central claim is that NTP implicitly biases the learned logit matrix towards a sparse plus low-rank structure: the sparse component encodes empirical co-occurrence probabilities, while the low-rank component—amplified during training—depends only on the binary support pattern (co-occurrence sparsity) and not on the specific conditional probabilities.
Analytical Decomposition and Geometric Consequences
The principal theoretical results are summarized as follows:
- Sparse plus Low-rank Logit Decomposition: The logit matrix L∗ in the vanishing-regularization limit asymptotically decomposes as
L∗≈Lsparse+R(λ)⋅Llow-rank,
where Lsparse encodes the empirical log-odds for in-support tokens, and Llow-rank emerges as the solution to a nuclear norm-constrained max-margin problem separating in-support from off-support tokens. The norm R(λ) diverges as λ→0.
- Directional Alignment and Subspace Collapse: Word and context embedding matrices converge directionally to the singular vectors of Llow-rank, with a global orthogonal transformation ambiguity. Importantly, context embeddings associated with contexts followed by identical support sets collapse onto the same direction as R(λ)→∞, regardless of the actual probability values:
support(pj)=support(pj′)⟹cos(hj,hj′)→1.
This subspace-collapse result implies that the geometry of learned representations reflects only the support, not the frequencies, of next-token patterns.
This framework demonstrates that, under expressive parametrization and sufficient optimization, the structure of language statistics is reflected in the angles and spans of the learned embeddings, and that the alignment of contextual representations is dictated by shared combinatorial support in the next-token matrix.
Experimental Validation Across Datasets and Architectures
Rigorous experiments are conducted on synthetic datasets and word-level text from the TinyStories corpus to validate theory-experiment agreement. Models include overparameterized transformers and deep MLPs trained until CE loss reaches empirical entropy.
- Empirical CE Loss Saturation and Divergence of Embedding Norms: Training leads CE loss to saturate at the empirical entropy, and norm growth is observed for context and word embeddings as predicted.
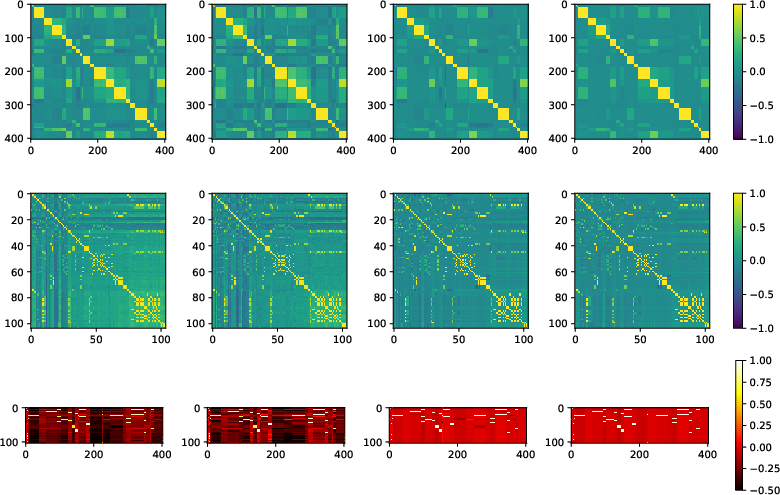
- Convergence to Proxy Geometry: Structural similarity metrics and heatmap visualizations confirm that the learned context and word embedding Gram matrices align closely with those obtained from the sparsity-based proxy, particularly as training approaches the entropy bound, as can be seen in:
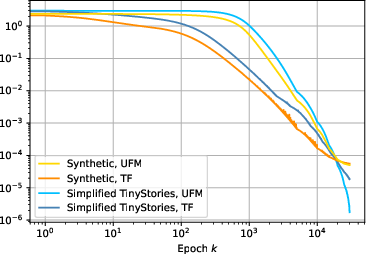

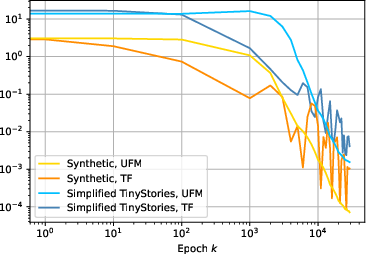


Figure 2: Loss approaches entropy, parameter norms diverge, projections onto the data subspace converge to soft-labels, and embedding correlations converge to proxy across synthetic and TinyStories settings.
- Semantic Consistency and Subspace Collapse: Visualizations on real datasets show clusters of contexts with similar linguistic continuation patterns collapsing to shared embedding directions, and clustering of word embeddings along syntactic or semantic categories.

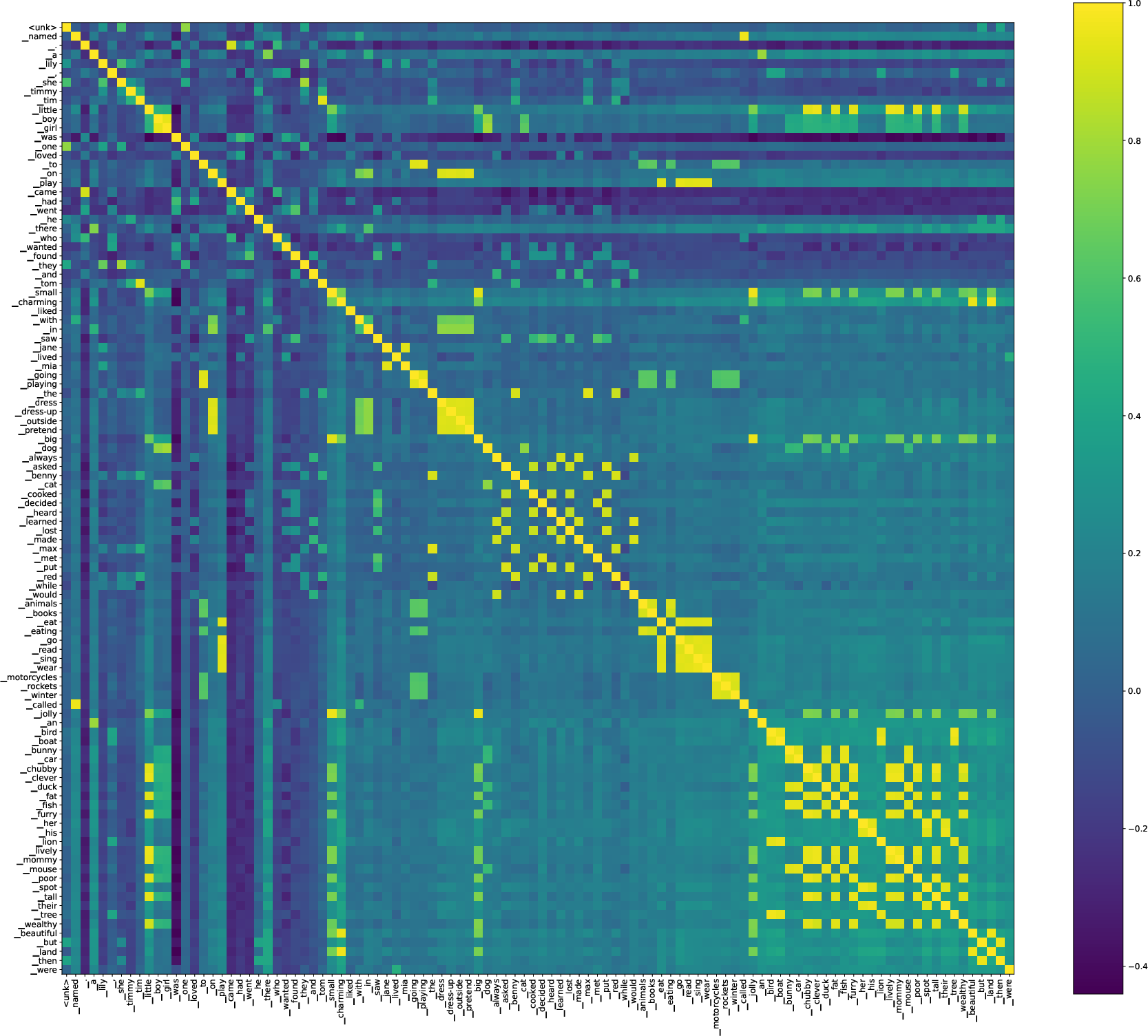
Figure 3: Implicit geometry of context (top) and word (bottom) embeddings with text annotations for the Simplified TinyStories dataset. High similarity (lighter color) reflects linguistic and syntactic groupings.
- Robustness to Architecture: Results are shown to hold across both transformer and deep MLP architectures, conditional on sufficient model capacity and training (Appendix Fig. 14).
In the perfectly symmetric regime (each context followed by k out of V words, all combinations appearing), the subspace collapse and directional alignment admit closed-form solutions: word embeddings form an equiangular tight frame (ETF), and context embeddings co-align with the centroid of their in-support words (Fig. 6 in the Appendix).
When supports are not symmetric and vocabulary sizes are large, a centered support-set proxy predicts both word and context geometry up to an orthogonal transformation, surviving to realistic language datasets.
Broader Implications, Limitations, and Future Work
This analysis formalizes and quantifies how implicit bias in overparameterized NTP pushes model representations to cluster and align with support-sets of next-token distributions, irrespective of frequency information. Concrete implications include:
- Interpretability: Provides an analytic handle for interpreting and probing language embedding geometries in overparameterized settings, especially regarding why similar linguistic settings (i.e. similar support patterns) lead to similar representations.
- Practical Training: Suggests that learning dynamics under CE loss will generically erase absolute frequency information in the dominant subspace, encoding only the support pattern unless explicit regularization or architecture constraints are imposed.
- Proxy-based Analysis: Motivates computationally tractable proxies (support-centered Gram matrices) for geometric analysis, useful for large-scale empirical interpretability and for model debugging.
- Links to Neural Collapse and Matrix Factorization: Connects the language modeling regime to work on neural collapse in classification settings as well as to Word2Vec's PMI factorization. The study generalizes these ideas to arbitrary sparsity and soft-label structures.
- Generalization Beyond Transformers: Framework is agnostic to architecture if the loss is driven to the lower bound and representations are sufficiently rich. However, in practice, transformers saturate the bound more efficiently than MLPs.
Open Questions and Directions:
- Can the characterization be generalized to cases where d<V (embedding smaller than vocabulary)? Empirically, convergence slows but geometry persists.
- How does the introduction of explicit regularization, non-converged training, or capacity constraints modify the implicit bias seen here?
- Does the identified structure influence higher-level linguistic phenomena (e.g., analogical structure, syntactic regularities) observed in large LMs?
- What are the implications for robustness, data bias, and explainable AI in NLP?
- How does the phenomenon extend to autoregressive training with variable context window and in settings with more naturalistic, non-sparse support patterns?
- Finally, could regularization or architectural design tune the balance between memorizing frequency information and support-alignment, offering a knob for interpretability or generalization?
Conclusion
This work provides a detailed analytic and empirical foundation for understanding the geometric inductive bias of next-token prediction in LLMs. It shows that, up to finite differences capturing empirical frequencies, context and word embedding spaces align almost entirely according to the binary support structure of next-token probabilities, with subspace collapse for contexts sharing identical supports. Both insights and proxies derived in this work have immediate applications for interpretability, generalization analysis, and the principled design of LLM training procedures.