- The paper introduces P/D-Serve, an end-to-end system that optimizes disaggregated LLM serving across tens of thousands of xPU devices.
- It employs dynamic P/D ratio adjustments and automated fault management to achieve up to a 6.7x throughput boost and a 42% improvement in TTFT.
- Efficient D2D KVCache transfers are enabled with block-free design and asynchronous batch processing, minimizing overhead and delays.
P/D-Serve: Serving Disaggregated LLM at Scale
The paper, "P/D-Serve: Serving Disaggregated LLM at Scale" (2408.08147), introduces an innovative end-to-end system named P/D-Serve. The system adresses key challenges associated with serving disaggregated LLMs across expansive infrastructures comprising tens of thousands of xPU devices, including GPUs and NPUs. The paper proposes a comprehensive architecture that addresses the challenges of diversity in prompts, accurate workload estimation, and efficient device-to-device (D2D) KVCache transfers, among others.
Disaggregated LLM Architecture
Autoregressive LLMs: This paper focuses on the architectural nuances of autoregressive LLMs, which leverage the self-attention mechanism, distinguished by their capacity for simultaneously using encoder and decoder components. For instance, models such as "Bert" and "Llama" embody typical encoder-only and decoder-only architectures, respectively. These models generate tokens based on previous outputs, utilizing key-value cache (KVCache) to improve inference by storing intermediate computed data — a necessity given the rapid growth in model size and tally of generated tokens.
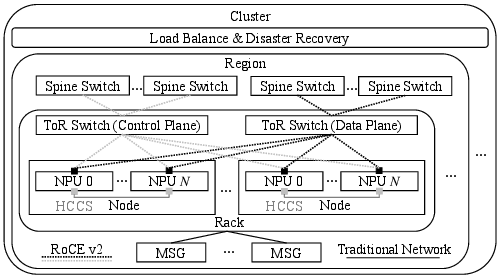
Infrastructure Challenges (Figure 1):
Proposed System: P/D-Serve
P/D-Serve is designed to address the inefficiencies of past disaggregated LLM serving systems, offering efficient resource management at a massive scale. The end-to-end P/D-Serve system integrates several key innovations:
Fine-grained P/D Organization: In response to larger diversity in real-time scenarios (Figure 2), P/D-Serve employs a dynamic RODM over Converged Ethernet (RoCE) to enable precise handling of P/D ratios (Figure 3). The ability to dynamically adjust prompts per scenario minimizes mismatches between processing capabilities of prefill and decoding instances, thereby optimizing throughput and achieving TTFT requirements (Figure 4).
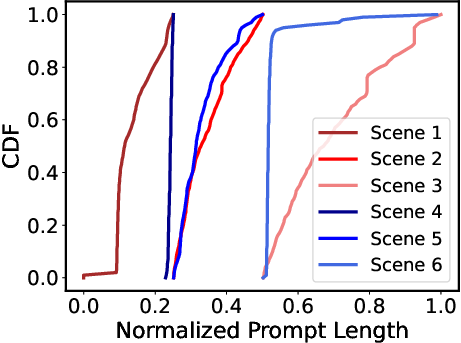
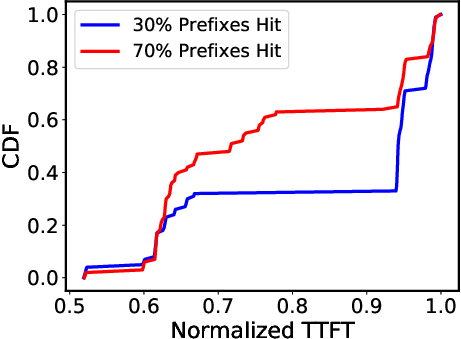
Figure 2: Various Prompts \protect\ in Services (Scenarios).
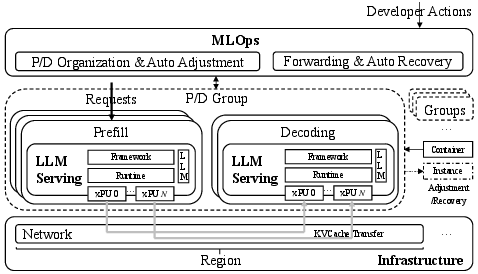
Figure 3: Overview of P/D-Serve.
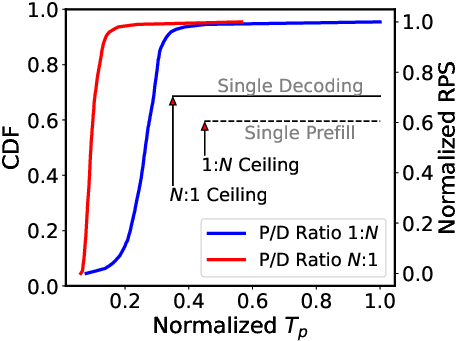
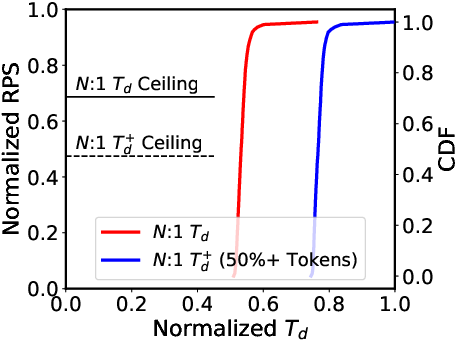
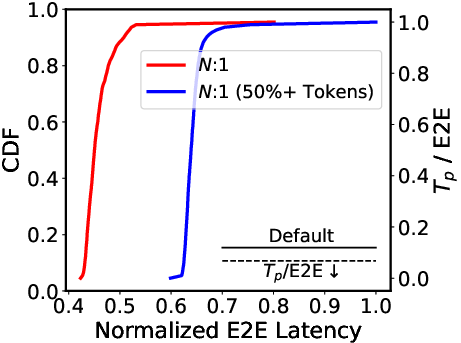
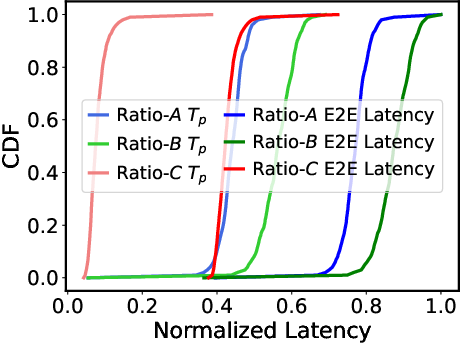
Figure 4: Mismatch and Bottleneck.
Automated Fault Management (Figure 5): The system employs a custom monitoring mechanism using a Flask service integrated per node, resulting in efficient auto-recovery without disrupting ongoing services — particularly essential in environments with large-scale NPU usage.
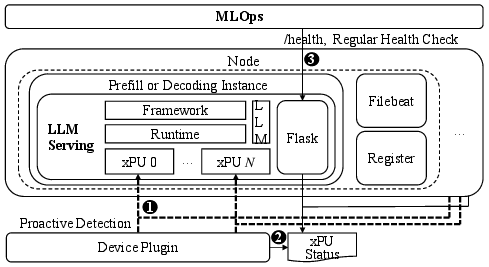
Figure 5: Automatic Fault Detection.
P/D Efficiency Optimization
P/D Ratio Adjustment:
The optimal synchronization between prefill and decoding is achieved through dynamic P/D adjustment reducing processing mismatch and refining E2E throughput (Figure 6 illustrates the success rate improvement). By maintaining a balance, P/D-Serve significantly boosts the throughput, achieving a 6.7x increase compared to centralized systems, with a 60% enhancement in E2E throughput and up to a 42% improvement in TTFT SLO.
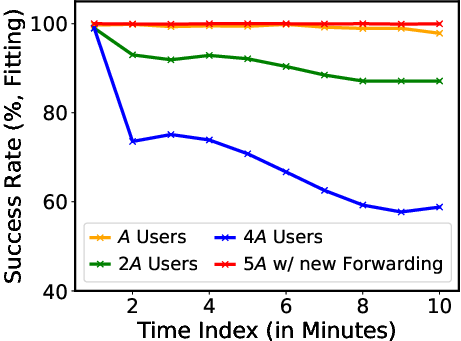
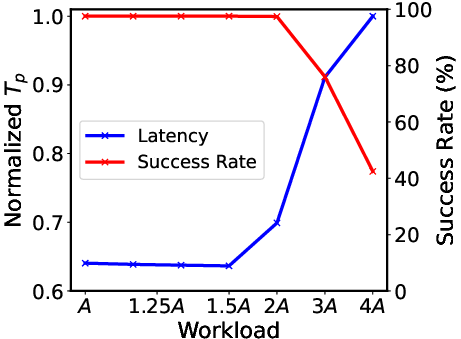
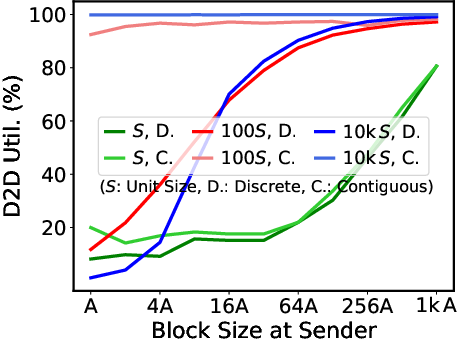
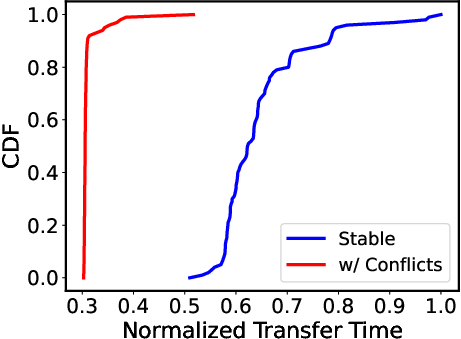
Figure 7: Changes on Success Rate.
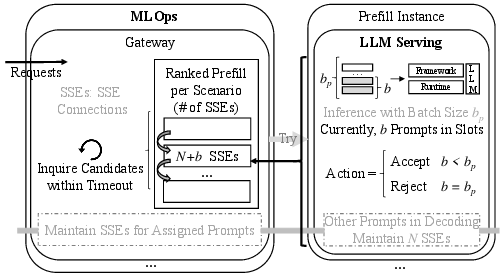
Figure 6: On-demand Forwarding for Idle Prefill.
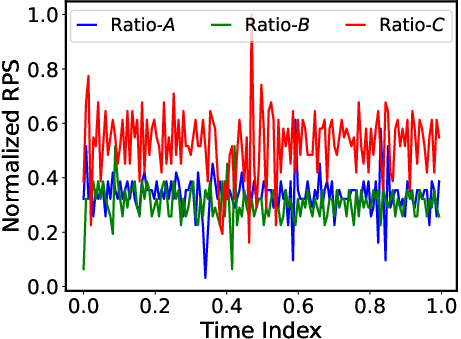
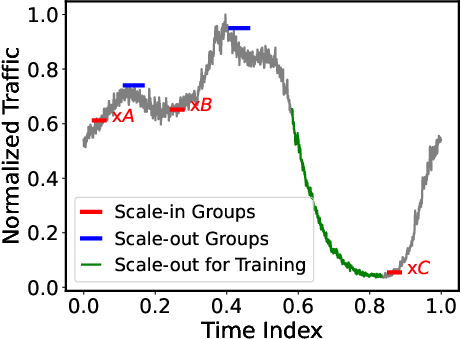
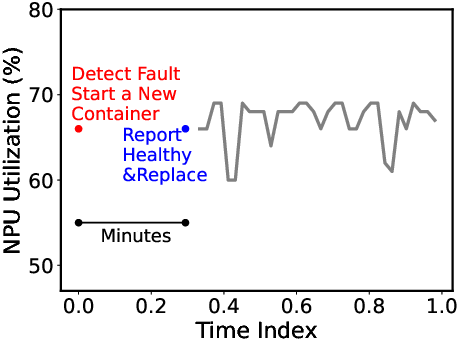
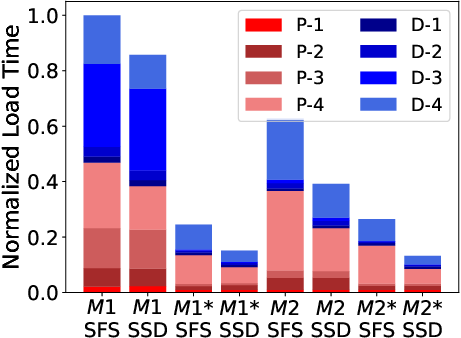
Figure 8: Throughput under Ratios.
Efficient KVCache Transfer (Figure 9):
The infrastructure ensures that D2D KVCache transfers occur with minimized overhead. The paper discusses transitioning to block-free transfers using contiguous buffer organization at sender xPU, minimizing software overhead and optimizing RoCE for efficient transfer (Figure 9). Asynchronous retrieval is facilitated with limited local queues in decoding instances, allowing rapid batch job completion without incurring delays due to queued requests.
Figure 4: Mismatch and Bottleneck.
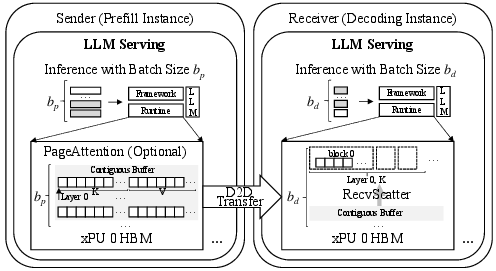
Figure 9: Block-free D2D KVCache Transfer.
Conclusion
The P/D-Serve system significantly enhances the efficiency of serving disaggregated LLMs at scale on infrastructures with vast xPU resources. By addressing challenges such as prompt diversity, optimal P/D instance adjustment, accurate workload estimation, and KVCache transfer, the system exhibits substantial improvements in TTFT, throughput, and D2D transfer capabilities in an energetic xPU environment. These contributions extend the capabilities of existing LLM serving systems, enhancing scalability and efficiency. The deployment of P/D-Serve over eight months demonstrates its applicability in large-scale environments, thereby suggesting promising avenues for further research in optimizing LLM serviceability.
Conclusively, P/D-Serve adds a robust and flexible architecture to the spectrum of LLM serving systems, providing substantial improvements in the practical deployment and operation of large-scale LLMs across diverse and high-demand environments. Future research might consider expanding on multimodal models and increasing the role of heterogeneous computing for even more efficient machine learning operations.