- The paper introduces a unified system, MemServe, that integrates context caching with disaggregated inference, significantly reducing redundant computations.
- The paper presents MemPool, an elastic memory pool that efficiently manages CPU DRAM and GPU HBM resources while minimizing memory fragmentation and network call overheads.
- The paper demonstrates through extensive evaluations that MemServe improves job completion time and time-to-first-token across diverse LLM serving workloads.
"MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool"
Introduction
The paper "MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool" addresses the evolving landscape of serving LLMs by proposing a unified system, MemServe, that integrates inter-request and intra-request optimizations, specifically context caching and disaggregated inference. LLMs have become essential in data centers, necessitating scalable serving architectures without prohibitive costs. While traditional stateless systems have transitioned to stateful setups, managing memory and computation efficiently remains a challenge. MemServe introduces MemPool, an elastic memory pool managing distributed memory resources, which lays the foundation for context caching and disaggregated inference to coexist and enhance performance metrics like job completion time and time-to-first-token.
MemServe Architecture
MemServe is structured to support various inference instances: prefill-only, decode-only, and PD-colocated setups, as illustrated in its architectural overview.
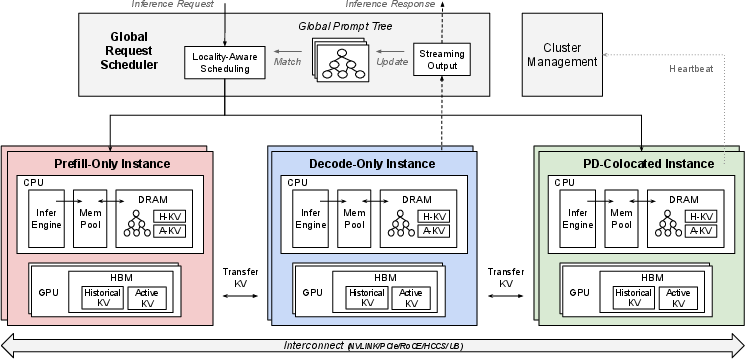
Figure 1: MemServe Architecture featuring multiple inference configurations, each utilizing AI servers according to parallelism needs.
The core component, MemPool, manages memory resources across these instances, providing APIs for efficient memory allocation, index management, and distributed data transfers. This architecture supports the reuse of the KV cache, crucial for optimizing LLM-serving workflows, facilitating operations like inter-instance KV cache exchange and context caching, thus overcoming previous architectural bottlenecks in KV cache management.
Elastic Memory Pool (MemPool)
MemPool handles memory at a cluster level, integrating CPU DRAM and GPU HBM resources. It provides APIs for memory block allocation, indexing active and historical KV caches, and transferring data across instances, which are indispensable for both intra-request and inter-request optimizations.
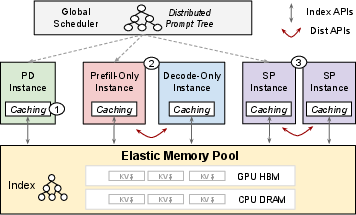
Figure 2: Use Cases Enabled By MemPool, demonstrating the integration of context caching, disaggregated inference, and sequence parallelism within a unified platform.
MemPool simplifies these complex operations by masking underlying hardware heterogeneity, enabling efficient KV cache reuse through a robust indexing system based on prompt tokens, thus allowing broad applicability across LLM serving scenarios.
Context Caching for Disaggregated Inference
The combination of context caching with disaggregated inference is novel, addressing previous limitations in simultaneous optimization application. MemPool facilitates this integration by utilizing its APIs in a step-by-step manner to achieve full-fledged caching capabilities in disaggregated setups.
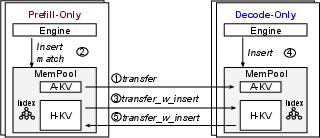
Figure 3: Enhancing Disaggregated Inference with Context Caching using MemPool APIs, showing specific steps and caching improvements.
Design milestones are laid out to gradually introduce caching at prefill and decode instances, culminating in an architecture where historical KV caches from both phases can significantly reduce redundant computations and data transmission needs, improving efficiency especially in scenarios with overlapping sessions.
Memory and Network Optimization
Memory fragmentation and network transmission inefficiencies in disaggregated inference are addressed by proposing improvements to existing discrete memory layouts. MemServe implements aggregation techniques akin to huge pages, reducing the number of network calls by minimizing the fragmentation of KV caches, thus optimizing communication overheads.
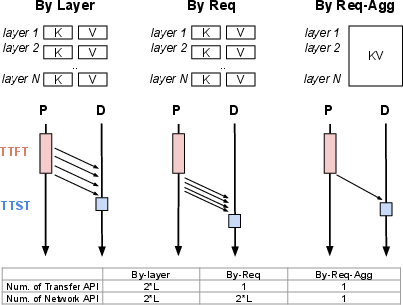
Figure 4: Network and Memory Layout Optimization Study, illustrating efficiency improvements in data transmission and memory usage.
Global Scheduler Design
MemServe's global scheduler employs a locality-aware policy based on global prompt trees, maximizing KV cache reuse across serving sessions, thereby optimizing serving latency and throughput.
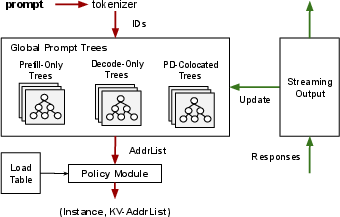
Figure 5: Global Scheduler Architecture utilizing prompt trees for locality-aware request scheduling.
This scheduling mechanism prioritizes instances with maximum cache reuse potential by analyzing the prompt token commonality, thus effectively minimizing redundant computations across distributed systems.
Evaluation of MemServe
Extensive tests demonstrate MemServe's ability to improve serving efficiency across multiple workloads, showing substantial reductions in job completion time and latency compared to traditional models.
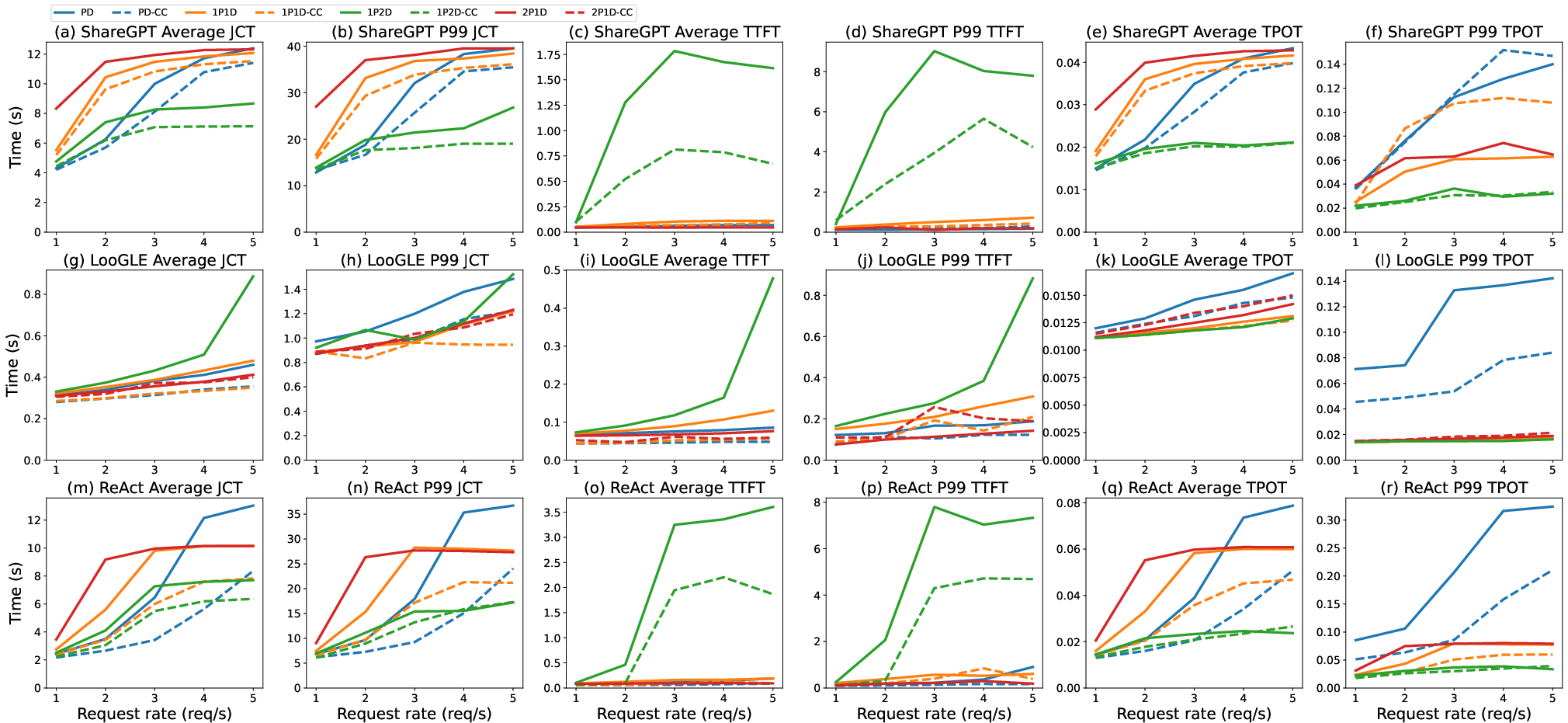
Figure 6: End-to-End Evaluation showcasing MemServe's performance improvements across different request rates.
Key insights are drawn from microbenchmarks, validating the lightweight nature of MemPool APIs and their scalable integration into LLM serving systems.
Conclusion
MemServe effectively introduces a novel architectural framework for stateful LLM serving, integrating context caching and disaggregated inference to enhance computational efficiency. Its implementation of MemPool and global scheduler architectures addresses and resolves critical challenges in KV cache management, paving the way for future developments in scalable AI systems that require robust memory and scheduling solutions. The implications of this work suggest a paradigm shift in efficiently serving expansive LLMs by unifying previously disparate optimization techniques.

