- The paper proposes SHiRA, a novel adapter framework that finetunes only 1-2% of parameters to enable rapid switching and robust multi-adapter fusion.
- It employs gradient-masking and various sparsity strategies to overcome LoRA’s limitations, achieving efficient parameter modifications.
- Evaluation highlights SHiRA’s enhanced imaging fidelity on Stable Diffusion and a 2.7% accuracy boost on language models like LLaMA over conventional methods.
Sparse High Rank Adapters for Rapid Switching and Multi-Adapter Fusion
The paper "Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters" introduces Sparse High Rank Adapters (SHiRA), a paradigm shift in adapter frameworks aimed at addressing the limitations inherent in Low Rank Adaptation (LoRA) methods. SHiRA focuses on finetuning only 1-2% of the base model's parameters, providing a robust solution to enhance rapid switching and reduce concept loss during multi-adapter fusion. This essay provides an expert overview of the implementation, experimental results, and implications of SHiRA's contributions to the domain.
Introduction to Sparse High Rank Adapters
SHiRA's development emerges from the need to mitigate LoRA's constraints, particularly in deployment scenarios involving mobile and edge devices. LoRA, while efficient in avoiding inference overhead, compromises rapid adapter switching due to its dense parameter modification during fusion. SHiRA overcomes these hurdles by leveraging highly sparse parameter modification, maintaining the pretrained model's integrity while allowing expedited adapter transitions.

Figure 1: Sparse HiRA enabling rapid switching and reduced concept loss by altering a minimal percentage of weights compared to LoRA.
SHiRA Implementation Framework
Sparse Adapter Construction
SHiRA's core mechanism revolves around extreme sparsity, where only a fraction of the pretrained weights is altered. This sparsity is accomplished through gradient-masking during training, ensuring that only significant parameters contribute to the adaptation process. Different masking strategies such as structured, random, weight magnitude, gradient magnitude, and SNIP-based masks facilitate targeted finetuning, allowing SHiRA to outperform traditional low-rank methods.
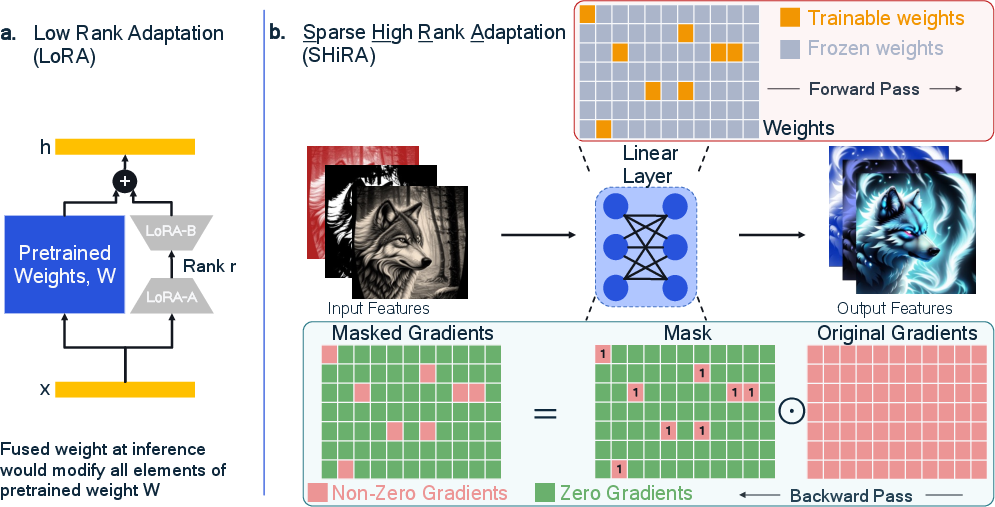
Figure 2: Comparison of SHiRA and LoRA, highlighting minimal weight modification and efficient finetuning in SHiRA.
Efficient Switching and Fusion Techniques
SHiRA's architecture supports rapid switching by permitting the storage of sparse weights and their indices. This capability stands in stark contrast to LoRA's need for a complete fusion stage. Multiple SHiRA adapters can be fused by simple additive operations on sparse weights, promoting efficient concept retention without the typical artifacts found in dense operations.
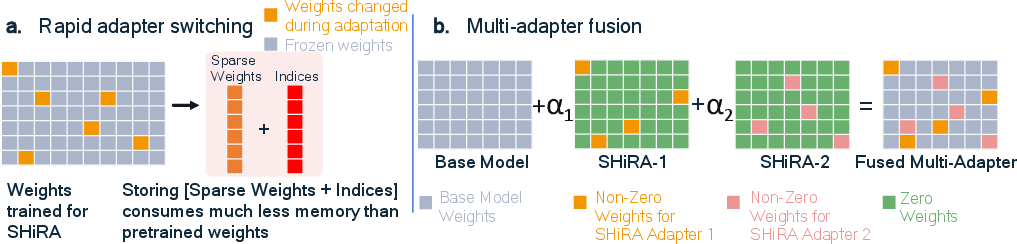
Figure 3: Demonstrates the rapid switching benefits and seamless multi-adapter fusion inherent to SHiRA architecture.
Evaluation on Vision and LLMs
Experiments conducted on Stable Diffusion models show SHiRA's superior performance in generating high-quality images across various styles and contexts. Comprehensive tests with the Bluefire and Paintings datasets reveal SHiRA's capability to maintain image fidelity while enabling rapid adapter transitions, outperforming LoRA in HPSv2 metrics.

Figure 4: SHiRA's superior multi-adapter fusion eliminating concept loss compared to LoRA's limitations in style adaptation.
LLM Enhancements
SHiRA's application to LLMs such as LLaMA-7B and LLaMA2-7B exhibits significant improvements in commonsense reasoning tasks. By finetuning minimal parameters, SHiRA achieves up to a 2.7% increase in accuracy over LoRA, demonstrating its potential for enhancing parameter efficiency and execution speed.
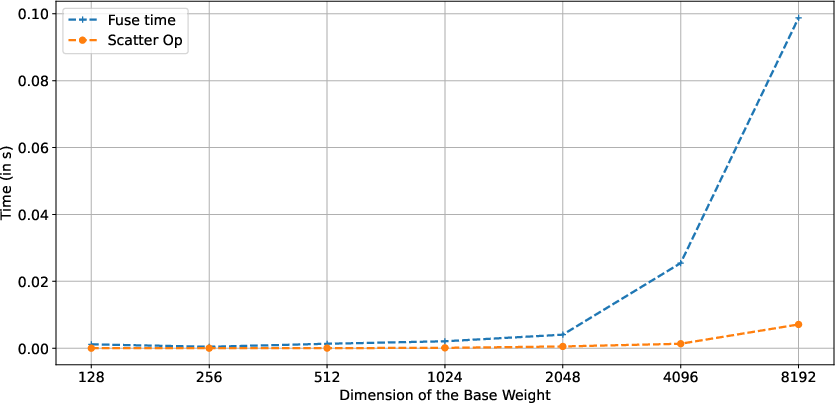
Figure 5: SHiRA's efficient parameter modification and loading time advantages over LoRA in LLM environments.
Implications and Future Directions
SHiRA presents a transformative approach to adapter frameworks, especially in resource-constrained environments. Its sparse high-rank structure ensures efficient parameter usability and seamless adapter transitions, positioning it as a pivotal advancement for both edge device deployment and complex multi-adapter scenarios. Future research may explore further optimizations in sparse finetuning techniques and their integrations with emerging architecture improvements and novel model applications.
Conclusion
The adaptations and efficiencies introduced by Sparse High Rank Adapters profoundly reshape the landscape of adapter frameworks in AI model finetuning. SHiRA provides compelling advantages in rapid switching and multi-adapter fusion, paving the way for innovative deployments across diverse computing environments. This framework significantly enhances the adaptability and robustness of pretrained models, potentially laying the groundwork for more flexible, efficient AI systems.

