LoRA-Switch: Boosting the Efficiency of Dynamic LLM Adapters via System-Algorithm Co-design
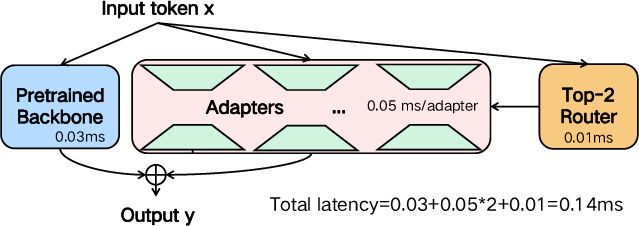
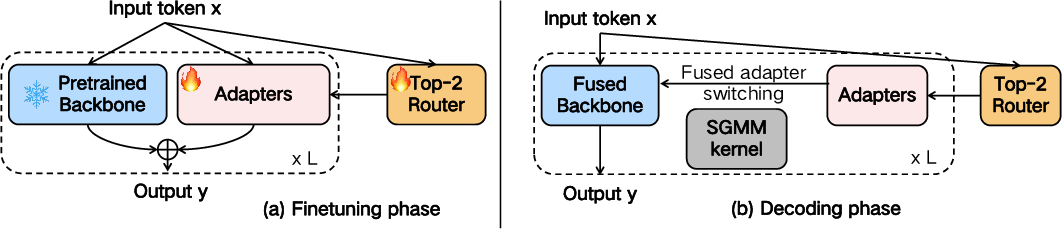
Abstract: Recent literature has found that an effective method to customize or further improve LLMs is to add dynamic adapters, such as low-rank adapters (LoRA) with Mixture-of-Experts (MoE) structures. Though such dynamic adapters incur modest computational complexity, they surprisingly lead to huge inference latency overhead, slowing down the decoding speed by 2.5+ times. In this paper, we analyze the fine-grained costs of the dynamic adapters and find that the fragmented CUDA kernel calls are the root cause. Therefore, we propose LoRA-Switch, a system-algorithm co-designed architecture for efficient dynamic adapters. Unlike most existing dynamic structures that adopt layer-wise or block-wise dynamic routing, LoRA-Switch introduces a token-wise routing mechanism. It switches the LoRA adapters and weights for each token and merges them into the backbone for inference. For efficiency, this switching is implemented with an optimized CUDA kernel, which fuses the merging operations for all LoRA adapters at once. Based on experiments with popular open-source LLMs on common benchmarks, our approach has demonstrated similar accuracy improvement as existing dynamic adapters, while reducing the decoding latency by more than 2.4 times.
- Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774 (2024).
- Punica: Multi-Tenant LoRA Serving. arXiv:2310.18547 [cs.DC]
- Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. ArXiv abs/1803.05457 (2018).
- QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314 [cs.LG]
- LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin. arXiv:2312.09979 [cs.CL]
- Mixture-of-LoRAs: An Efficient Multitask Tuning for Large Language Models. arXiv:2403.03432 [cs.CL]
- Higher Layers Need More LoRA Experts. arXiv:2402.08562 [cs.CL]
- A framework for few-shot language model evaluation. https://doi.org/10.5281/zenodo.10256836
- Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning. arXiv:2312.12379 [cs.CV]
- Measuring Massive Multitask Language Understanding. Proceedings of the International Conference on Learning Representations (ICLR) (2021).
- Parameter-Efficient Transfer Learning for NLP. arXiv:1902.00751 [cs.LG]
- LoRA: Low-Rank Adaptation of Large Language Models. ArXiv abs/2106.09685 (2021). https://api.semanticscholar.org/CorpusID:235458009
- Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024).
- Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691 (2021).
- MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA based Mixture of Experts. arXiv:2404.15159 [cs.CL]
- Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv:2101.00190 [cs.CL]
- SlimOrca: An Open Dataset of GPT-4 Augmented FLAN Reasoning Traces, with Verification. https://https://huggingface.co/Open-Orca/SlimOrca
- TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 3214–3252. https://doi.org/10.18653/v1/2022.acl-long.229
- Moelora: An moe-based parameter efficient fine-tuning method for multi-task medical applications. arXiv preprint arXiv:2310.18339 (2023).
- GPT Understands, Too. arXiv:2103.10385 [cs.CL]
- Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs.LG]
- Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS).
- MoELoRA: Contrastive Learning Guided Mixture of Experts on Parameter-Efficient Fine-Tuning for Large Language Models. arXiv:2402.12851 [cs.CL]
- SpecInfer: Accelerating Large Language Model Serving with Tree-based Speculative Inference and Verification. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS ’24). ACM. https://doi.org/10.1145/3620666.3651335
- Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. In EMNLP.
- OpenChat. 2023. ShareGPT4 Dataset. Hugging Face Datasets. https://huggingface.co/datasets/openchat/openchat_sharegpt4_dataset/blob/main/sharegpt_clean.json Accessed: 2024-05-11.
- WinoGrande: An Adversarial Winograd Schema Challenge at Scale. arXiv preprint arXiv:1907.10641 (2019).
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In International Conference on Learning Representations.
- Snowflake AI Research Team. 2024. Snowflake Arctic: The Best LLM for Enterprise AI — Efficiently Intelligent, Truly Open. https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/. Accessed on April 26, 2024.
- CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy Doran, and Thamar Solorio (Eds.). Association for Computational Linguistics, Minneapolis, Minnesota, 4149–4158. https://doi.org/10.18653/v1/N19-1421
- The Mosaic Research Team. 2024. Introducing dbrx: A New State-of-the-Art Open LLM. https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm. Accessed on April 26, 2024.
- LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 [cs.CL]
- Llama 2: Open Foundation and Fine-Tuned Chat Models. ArXiv abs/2307.09288 (2023). https://api.semanticscholar.org/CorpusID:259950998
- Magicoder: Source Code Is All You Need. arXiv preprint arXiv:2312.02120 (2023).
- Parameter-Efficient Sparsity Crafting from Dense to Mixture-of-Experts for Instruction Tuning on General Tasks. arXiv:2401.02731 [cs.AI]
- Parameter-Efficient Sparsity Crafting from Dense to Mixture-of-Experts for Instruction Tuning on General Tasks. arXiv preprint arXiv:2401.02731 (2024).
- xAI. 2024. Open release of grok-1. https://x.ai/blog/grok-os
- MoRAL: MoE Augmented LoRA for LLMs’ Lifelong Learning. arXiv preprint arXiv:2402.11260 (2024).
- MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models. arXiv preprint arXiv:2309.12284 (2023).
- HellaSwag: Can a Machine Really Finish Your Sentence?. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199 (2023).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

