Published 30 Sep 2025 in cs.LG, cs.AI, and cs.DC | (2510.00206v1)
Abstract: Low-Rank Adaptation (LoRA) has become the leading Parameter-Efficient Fine-Tuning (PEFT) method for LLMs, as it significantly reduces GPU memory usage while maintaining competitive fine-tuned model quality on downstream tasks. Despite these benefits, we identify two key inefficiencies in existing LoRA fine-tuning systems. First, they incur substantial runtime overhead due to redundant memory accesses on large activation tensors. Second, they miss the opportunity to concurrently fine-tune multiple independent LoRA adapters that share the same base model on the same set of GPUs. This leads to missed performance gains such as reduced pipeline bubbles, better communication overlap, and improved GPU load balance. To address these issues, we introduce LoRAFusion, an efficient LoRA fine-tuning system for LLMs. At the kernel level, we propose a graph-splitting method that fuses memory-bound operations. This design eliminates unnecessary memory accesses and preserves the performance of compute-bound GEMMs without incurring the cost of recomputation or synchronization. At the scheduling level, LoRAFusion introduces an adaptive batching algorithm for multi-job fine-tuning. It first splits LoRA adapters into groups to intentionally stagger batch execution across jobs, and then solves a bin-packing problem within each group to generate balanced, dependency-aware microbatches. LoRAFusion achieves up to $1.96\times$ ($1.47\times$ on average) end-to-end speedup compared to Megatron-LM, and up to $1.46\times$ ($1.29\times$ on average) improvement over mLoRA, the state-of-the-art multi-LoRA fine-tuning system. Our fused kernel achieves up to $1.39\times$ ($1.27\times$ on average) kernel performance improvement and can directly serve as a plug-and-play replacement in existing LoRA systems. We open-source LoRAFusion at https://github.com/CentML/lorafusion.
The paper introduces a novel fusion strategy that targets memory-bound operations in LoRA modules to cut redundant memory accesses.
It presents fused kernels like FusedLoRA and FusedMultiLoRA, achieving up to 1.96× speedup across various LLMs and hardware platforms.
The adaptive MILP-based scheduler minimizes pipeline bubbles and load imbalance, improving GPU utilization during distributed fine-tuning.
LoRAFusion: Efficient LoRA Fine-Tuning for LLMs
Introduction and Motivation
LoRAFusion addresses two critical inefficiencies in the current landscape of Low-Rank Adaptation (LoRA) fine-tuning for LLMs: (1) substantial runtime overhead due to redundant memory accesses in LoRA modules, and (2) missed opportunities for concurrent fine-tuning of multiple LoRA adapters sharing the same base model. While LoRA is the dominant Parameter-Efficient Fine-Tuning (PEFT) method, existing systems largely inherit optimizations from full-model fine-tuning, failing to exploit LoRA's unique characteristics. Profiling reveals that LoRA adapters, despite their minimal parameter footprint, introduce up to 40% throughput degradation, primarily due to memory-bound operations on large activation tensors. Additionally, the lack of multi-adapter scheduling leads to pipeline bubbles and load imbalance, further reducing GPU utilization.
Figure 1: Comparison between traditional full model fine-tuning and LoRA fine-tuning.
System-Level Bottlenecks in LoRA Fine-Tuning
Memory-Bound Overhead
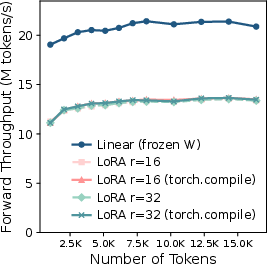
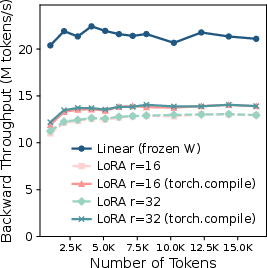
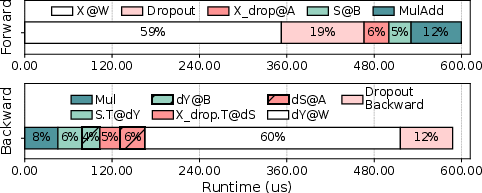
LoRA modules add two trainable low-rank matrices to each linear layer, theoretically incurring negligible computational cost. However, empirical analysis demonstrates that the down-projection and up-projection operations are memory-bandwidth-bound, with arithmetic intensity far below the hardware's machine balance. For instance, the down-projection GEMM (XA) with small rank r results in excessive memory traffic, as large activation tensors are repeatedly loaded and stored. Nsight Compute profiling quantifies this, showing a 2.64× increase in global memory traffic compared to the frozen linear layer.
Figure 2: Throughput comparison of the frozen linear layer (n=k=4096) vs. the corresponding LoRA linear layer with different numbers of tokens and ranks.
Figure 3: Runtime breakdown of a LoRA linear module with n=k=4096, r=16, and tokens=8192. @ is matrix multiplication, d indicates a gradient, and .T represents a transpose.
Distributed Training Inefficiencies
Distributed fine-tuning with data parallelism (DP), fully sharded data parallelism (FSDP), and pipeline parallelism (PP) suffers from load imbalance due to variable sequence lengths in real datasets. This results in pipeline bubbles and idle GPU time, with practical slowdowns up to 30% compared to ideal fixed-length scenarios. Multi-LoRA approaches, such as mLoRA, attempt to mitigate this by batching adapters, but fail to address memory access bottlenecks and do not optimally balance workloads across GPUs.
Figure 4: Performance slowdown of practical LoRA fine-tuning of LLaMa-3.1-70B on 4 H100 GPUs compared to ideal fixed-length distributed training scenarios.
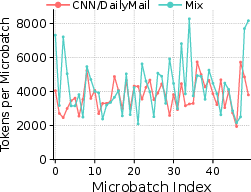
Figure 5: Number of tokens per micro-batch with a fixed micro batch size = 4.
LoRAFusion: Kernel and Scheduling Innovations
FusedLoRA and FusedMultiLoRA Kernels
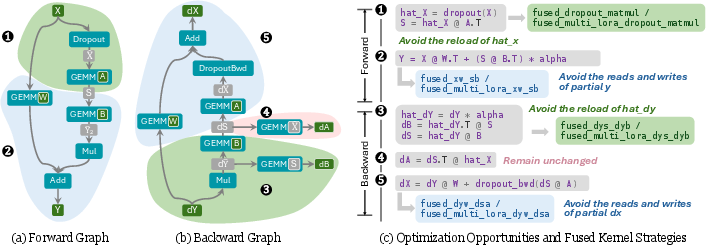
LoRAFusion introduces a graph-splitting fusion strategy, targeting memory-bound operations without disrupting compute-bound GEMMs. Instead of fusing the entire computation graph—which would degrade GEMM performance due to register and shared memory pressure—LoRAFusion splits at the intermediate tensor S=XA, which is small and cheap to materialize. This enables horizontal fusion of memory-heavy operations, reducing redundant memory accesses while preserving optimal tiling for GEMMs.
Figure 6: Overview of our fusion strategy for LoRA modules in the forward pass, illustrating the full graph fusion approach vs. the split graph fusion approach.
Figure 7: LoRA kernel design. FusedLoRA reduces memory accesses by combining memory-heavy LoRA branches with base GEMM operations on frozen weights. The right figure has transposed weight tensors to match the hardware memory layout.
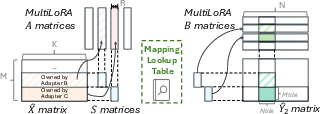
FusedMultiLoRA extends this to support multiple adapters in a single batch, using tile-level routing to dynamically select adapter weights and configurations. This avoids separate kernel launches per adapter and maintains high GPU utilization.
Figure 8: Illustration of FusedMultiLoRA in the forward pass. The routing of LoRA adapters is done at the tile level.
Multi-LoRA Adaptive Scheduler
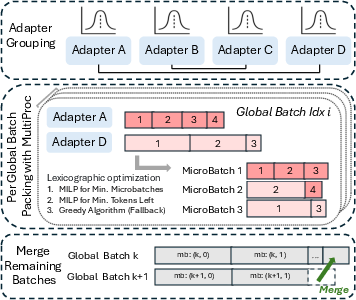
LoRAFusion's scheduler operates at the job level, grouping adapters and batching samples to balance GPU load and minimize pipeline bubbles. The scheduling algorithm uses a two-stage Mixed Integer Linear Programming (MILP) formulation to solve the bin-packing problem: first minimizing the number of microbatches, then minimizing the smallest bin size to facilitate merging and reduce underfilled microbatches. Adapter grouping is performed based on sequence length statistics, and a greedy fallback is used if the MILP solver exceeds a timeout.
Figure 9: Multi-LoRA adapter scheduling workflow. Top: Adapter grouping by sequence length statistics. Middle: Two-stage MILP optimization for microbatch creation. Bottom: Cross-batch merging of underfilled microbatches.
Evaluation and Performance Analysis
End-to-End Throughput
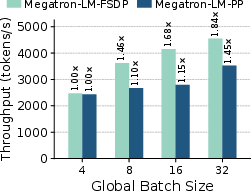
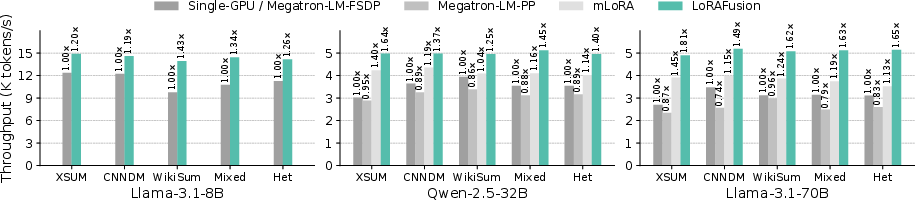
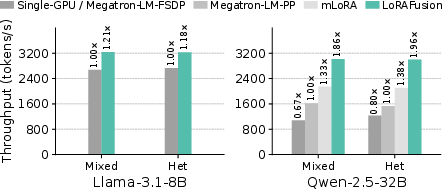
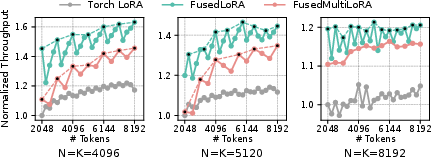
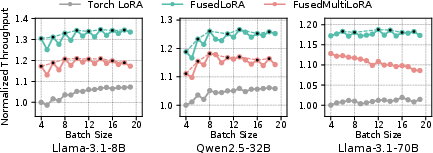
LoRAFusion achieves up to 1.96× speedup (average 1.47×) over Megatron-LM and up to 1.46× (average 1.29×) over mLoRA across LLaMa-3.1-8B, Qwen-2.5-32B, and LLaMa-3.1-70B models on H100 and L40S GPUs. The fused kernels alone provide up to 1.39× speedup (average 1.27×) and can be used as plug-and-play replacements in existing LoRA systems.
Figure 10: End-to-end training throughput (tokens/sec) of training 4 LoRA adapters on 1, 2, and 4 H100 GPUs. The first four bars per subfigure represent homogeneous workloads (same dataset), and the final (Het) shows heterogeneous adapters trained on different datasets.
Figure 11: End-to-end training throughput (tokens/sec) of training 4 LoRA adapters on 1 and 4 L40S GPUs.
Scalability
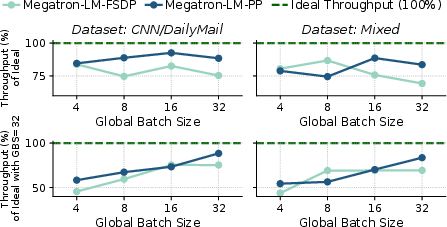
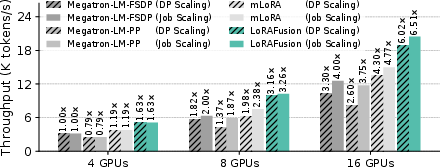
Job-level scaling (more concurrent jobs per GPU) consistently outperforms DP scaling (more GPUs per job), achieving up to 1.25× higher throughput on 16 H100 GPUs. LoRAFusion is compatible with both scaling strategies and multi-node setups.
Figure 12: Scalability of LoRAFusion across 4, 8, and 16 H100 GPUs when training 4 LoRA adapters simultaneously. DP scaling means the more GPUs are used to increase the DP degree for the same job, while Job scaling means different LoRA fine-tuning jobs are scheduled to utilize more GPUs. Global batch sizes are scaled proportionally with GPU count to ensure fair comparison.
Kernel-Level and Memory Traffic Analysis
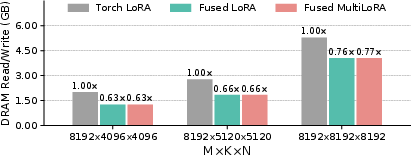
FusedLoRA and FusedMultiLoRA kernels reduce DRAM traffic by 34–37%, with performance gains most pronounced on hardware with high compute-to-memory bandwidth ratios. Layer-wise analysis shows consistent speedup across decoder layers.
Figure 13: Performance of FusedLoRA kernel in forward and backward passes.
Figure 14: Performance of FusedLoRA kernel in decoder layers of different models.
Figure 15: GPU DRAM memory traffic comparison between different kernels from NVIDIA Nsight Compute (NCU).
Pipeline Bubble Reduction and Scheduling Overhead
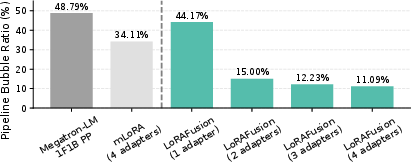
LoRAFusion's scheduler reduces pipeline bubble ratios from 44% (single adapter) to 11% (four adapters), outperforming mLoRA. The scheduling overhead is negligible due to parallel execution and efficient fallback strategies.
Figure 16: Pipeline bubble ratio under different methods.
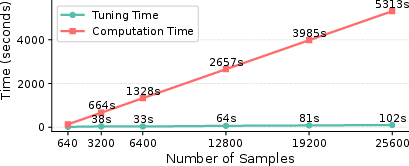
Figure 17: Tuning and computation time vs. number of samples for 4-stage pipeline with 4 adapters.
Speedup Breakdown
The combined effect of kernel fusion and adaptive scheduling yields the highest speedup, with each component contributing incrementally. Kernel fusion alone provides a 1.13× gain, while adaptive scheduling and multi-adapter batching further increase throughput.
Figure 18: Speedup breakdown of LoRAFusion on LLaMa-3.1-70B with 4 GPUs.
Practical and Theoretical Implications
LoRAFusion demonstrates that system-level optimizations tailored to LoRA's memory and parallelism characteristics can yield substantial performance improvements without compromising model quality or convergence. The fusion strategy is extensible to LoRA variants (e.g., DoRA, VeRA) and compatible with quantized models (e.g., QLoRA). The scheduler's MILP-based approach is generalizable to other multi-tenant fine-tuning scenarios and can be integrated with automatic parallelization frameworks.
The reduction in memory traffic and improved GPU utilization have direct implications for cost and energy efficiency in large-scale LLM fine-tuning. As hardware trends continue to favor increased compute FLOPS over memory bandwidth, the benefits of LoRAFusion's fusion strategy are expected to grow.
Conclusion
LoRAFusion systematically addresses the memory and parallelism bottlenecks in LoRA fine-tuning for LLMs through a combination of kernel-level fusion and job-level adaptive scheduling. The system achieves up to 1.96× speedup over state-of-the-art baselines, with robust scalability and generalizability across models, datasets, and hardware platforms. The open-source release of LoRAFusion provides immediate practical value for researchers and practitioners seeking efficient, scalable LoRA fine-tuning solutions.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.