- The paper introduces PicoAudio, enhancing text-to-audio generation with precise control over timestamps and event frequencies via simulated audio-text datasets.
- It employs a VAE and diffusion model to convert detailed temporal instructions into latent representations, achieving sub-second accuracy.
- Experimental results show significant improvements in controlling single and multiple audio events, outperforming models like AudioLDM2 and Amphion.
Summary of PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-Audio Generation
The paper "PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-audio Generation" (2407.02869) presents a novel framework designed to enhance audio generation models with precise temporal control capabilities. This work addresses significant limitations in current audio generation methodologies, which generally lack the ability to specify exact timestamps and occurrence frequencies of sound events, crucial for real-world applications.
Introduction
The demand for improved audio generation techniques that integrate precise temporal controls is growing with the evolution of generative models. While existing models can produce high-fidelity audio, they often struggle with fine-grained temporal controls such as timing and frequency of sound events. This paper identifies two main challenges: the absence of temporally-aligned audio-text datasets and the inherent limitations of existing model architectures like diffusion models that do not natively incorporate temporal information.
PicoAudio Framework
Data Simulation and Text Processing
The PicoAudio framework introduces a data simulation pipeline that facilitates the creation of temporally-aligned audio-text datasets. Audio clips, gathered from various online sources, are segmented and filtered to generate a database of high-quality audio events. This simulation process uses a method that pairs synthesized audio with timestamp and frequency captions, enabling the learning of precise temporal controls.
A key component of PicoAudio is its text processor, which uses a one-hot matrix to represent audio event timestamps. This matrix, combined with powerful text processing capabilities of LLMs such as GPT-4, allows PicoAudio to convert complex temporal instructions into a format that models can directly utilize for training and inference.
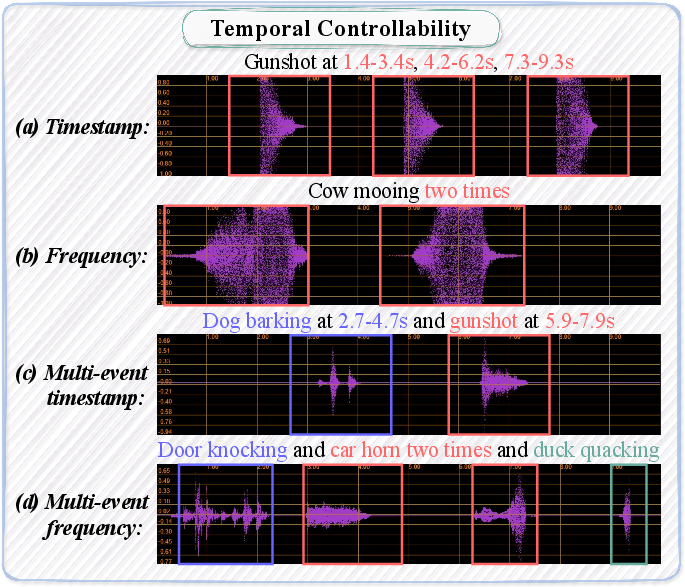
Figure 1: Illustration of controlling timestamp / occurrence frequency of audio events by PicoAudio. It can enable precise controlling of single events or multiple events.
Model Design
PicoAudio employs a Variational Autoencoder (VAE) for effective audio representation, which compresses spectrogram information into latent space. This is critical for handling the high dimensionality and variability of audio data. The system uses a diffusion model to predict latent representations based on timestamp and event embeddings, allowing for granular temporal control during audio synthesis.
A tailored diffusion model enables PicoAudio to achieve sub-second temporal accuracy, addressing significant shortcomings in previous methodologies. By leveraging an integrated training framework with frozen pre-trained components, PicoAudio efficiently learns robust temporal controls.
Experimental Evaluation
The paper provides a detailed experimental setup with tasks that assess both timestamp and frequency controls. The evaluation uses objective metrics like segment F1 score and L1freq error, alongside subjective metrics such as MOS for control accuracy and audio quality. PicoAudio demonstrates substantial improvements over existing models like AudioLDM2 and Amphion, particularly in tasks requiring multiple-event control and frequency precision.
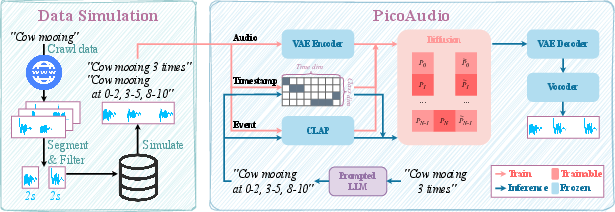
Figure 2: PicoAudio Flowchart. (Left) illustrates the simulation pipeline, wherein data is crawled from the Internet, segmented and filtered, resulting in one-occurrence segments stored in a database. (Right) showcases the model framework.
Results and Implications
PicoAudio provides a significant advancement in achieving precise temporal control, enabling applications in complex auditory scenarios where exact timing and frequency are paramount. The method displays superior performance across both single-event and multi-event tests, with results nearing the ground truth in simulation settings. This makes PicoAudio a compelling choice for applications that require detailed audio scene synthesis.
With its ability to handle arbitrary temporal control requirements via powerful text transformations, PicoAudio positions itself as a versatile tool for future audio generation applications. The framework's modularity and reliance on simulated data indicate potential scalability and adaptability to diverse soundscapes, though further developments are needed to extend its capacity to more varied audio events.
Conclusion
The PicoAudio framework represents a significant step toward more refined and precise text-to-audio generation systems. By addressing the critical limitations of existing models, PicoAudio not only enhances practical applicability but also opens new avenues for research into temporal control within generative audio models. Future work will focus on expanding its event control capabilities and exploring broader applications across different audio contexts.

