- The paper introduces a novel event-roll-guided framework for audio editing that precisely deletes, inserts, or enhances sound events in complex audio scenes.
- The model employs an encoder-decoder transformer on SoundStream token sequences, using synthetic data to mix isolated events with real-world backgrounds for training.
- Experimental results using MSD and KLD metrics demonstrate significant improvements in targeted regions, while ablation studies highlight the critical role of timing, action, and class conditioning.
Event-Roll-Guided Generative Audio Editing with Recomposer
Introduction and Motivation
Recomposer introduces a generative approach to audio editing that operates at the level of discrete sound events within complex, real-world sound scenes. Traditional audio editing tools are limited in their ability to manipulate overlapping sound sources, especially when precise, event-level modifications (such as deleting a cough or enhancing a doorbell) are required. Generative models, with their strong priors over audio structure, offer the potential to perform such edits by inferring plausible content for masked or modified regions. Recomposer leverages this capability, enabling users to delete, insert, or enhance individual sound events based on explicit, time-aligned edit instructions and event class labels.
The system is built around the concept of an "event roll"—a graphical and symbolic representation of the timing and class of sound events in an audio scene, which serves as the control interface for editing operations.
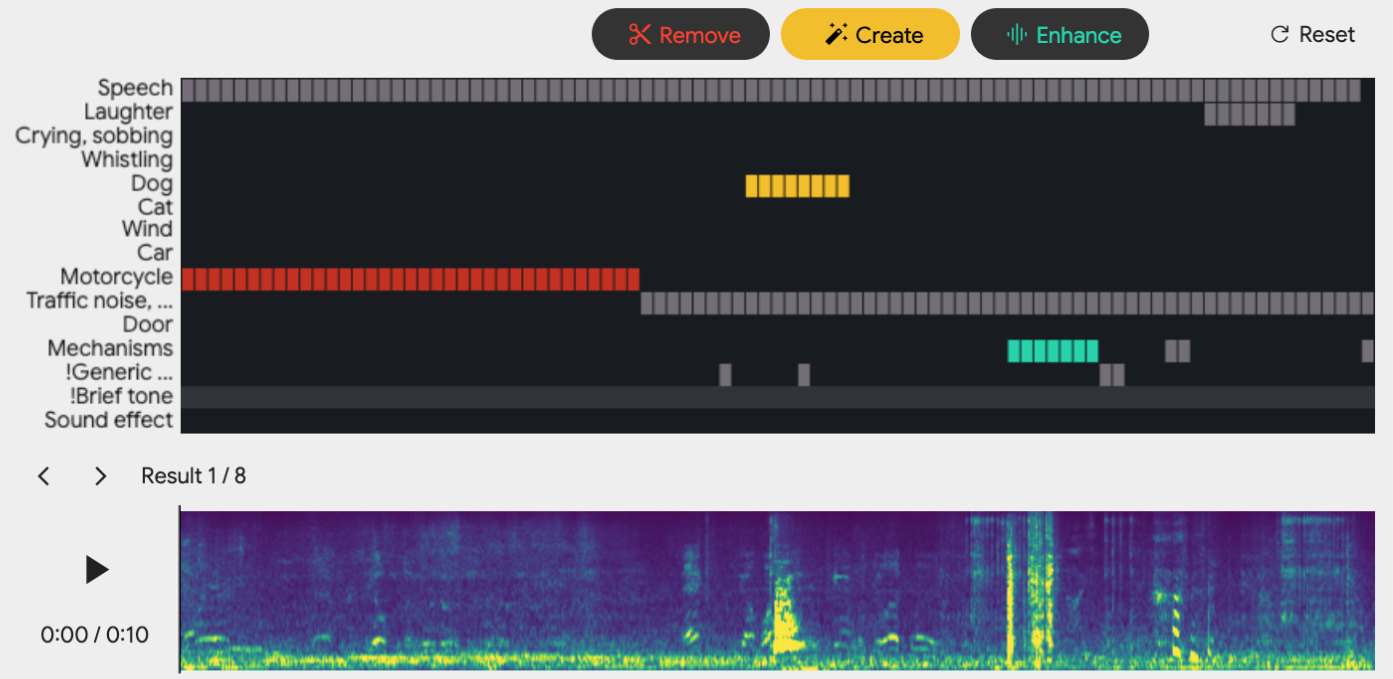
Figure 1: The Sound Recomposition editor visualizes event timing and class, allowing users to select and edit individual events.
Model Architecture
Recomposer employs an encoder-decoder transformer architecture that operates directly on SoundStream residual vector quantization (RVQ) token sequences. The model is conditioned on both the input audio and a set of edit instructions, which are encoded as a time-aligned stack of audio features and instruction embeddings. The edit instructions specify the action (delete, insert, enhance), the target event class, and the precise temporal extent of the edit.
The text encoder (Sentence-T5) and the audio encoder/decoder (SoundStream) are pretrained and frozen, while the transformer is trained to autoregressively generate the output SoundStream token sequence, which is then decoded to produce the edited audio waveform.
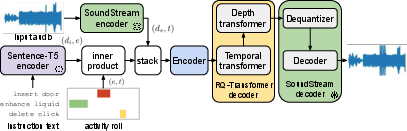
Figure 2: The Recomposer model architecture: an encoder-decoder transformer conditioned on audio and edit instructions, generating SoundStream tokens for waveform synthesis.
The transformer comprises a 12-layer encoder, a 12-layer temporal transformer, and a 3-layer depth transformer, totaling approximately 390M parameters. The temporal transformer models dependencies across time, while the depth transformer autoregressively generates the RVQ tokens for each frame.
Synthetic Data Generation
A critical component of Recomposer is the construction of large-scale, realistic training data. Since ground-truth pairs of (input audio, desired output audio, edit description, timing) are not available for arbitrary edits, the authors synthesize training examples by mixing isolated target events (from Freesound) into dense, real-world backgrounds (from AudioSet) at random times and target-to-background ratios (TBRs). This enables the creation of precise training pairs for the three edit operations:
- Delete: Remove a target event from the mixture.
- Insert: Add a target event to the background.
- Enhance: Amplify a weak target event in the mixture.
The synthetic data pipeline ensures diversity in both background and target content, and allows for controlled manipulation of event timing and level.
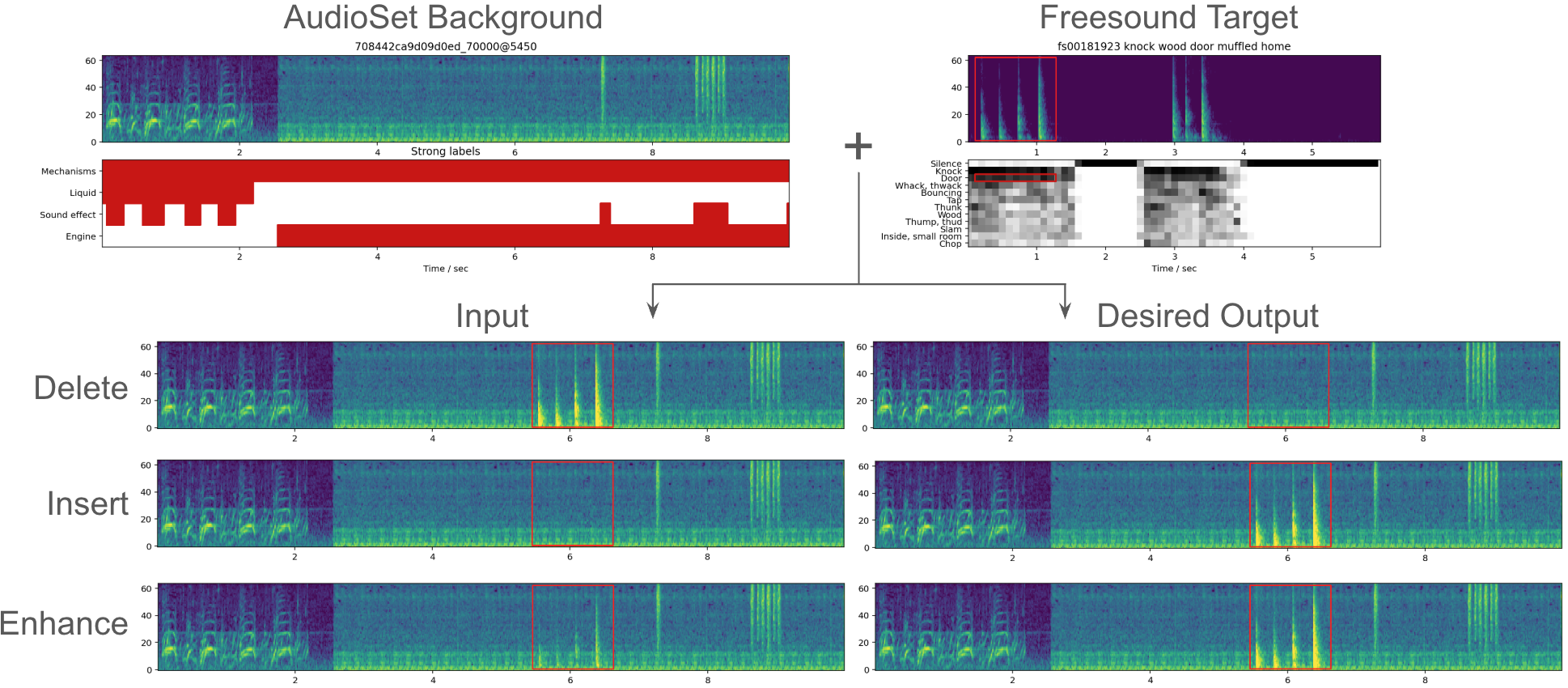
Figure 3: Synthetic data creation pipeline: backgrounds from AudioSet are mixed with target events from Freesound at random times and TBRs to generate training pairs for each edit operation.
Evaluation Metrics and Experimental Results
Recomposer is evaluated using two primary metrics:
- Multiscale Spectral Distortion (MSD): Measures signal-level similarity between spectrograms of the model output and the desired target, tolerant to minor timing differences.
- Classifier KL Divergence (KLD): Measures the divergence between class posterior distributions (from YAMNet) of the model output and the target, focusing on semantic class similarity.
Both metrics are computed per time frame, allowing for separate analysis of target (edited) and nontarget (unchanged) regions.
Main Results
The model demonstrates substantial improvements over the unprocessed baseline in the target regions for all three edit operations. For deletion, the MSD improvement is 2.3, and for enhancement, the KLD is reduced by 0.7. Insertions, which require the model to generate plausible new events from class and timing information alone, show smaller but still significant improvements.
A dedicated enhancement-only model was trained and evaluated across a wide range of input TBRs. The results show that as the input event becomes more prominent (higher TBR), both MSD and KLD improve, indicating a smooth transition from generative event synthesis (for weak inputs) to source separation (for strong inputs).
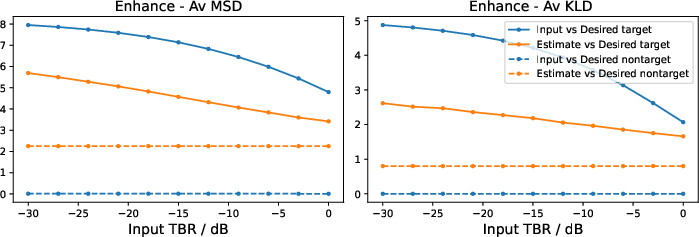
Figure 4: MSD and KLD for enhancement as a function of input TBR, showing improved performance as the input event becomes more prominent.
Ablation Studies
Ablation experiments systematically removed components of the conditioning information (timing, action, class) to assess their impact. The results confirm that:
- Timing information is critical for localizing edits; its removal leads to erroneous or missed edits, especially in the presence of decoy events.
- Action information is necessary for distinguishing between enhancement and deletion.
- Class information is essential for insertion, as the model must generate an event of the correct class.
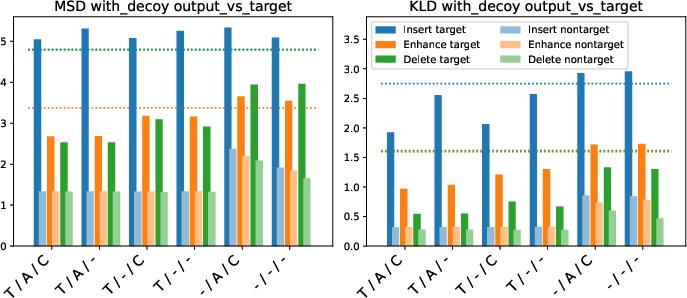
Figure 5: Ablation study results: removing timing, action, or class information degrades performance, especially for insertion and in the presence of decoy events.
Subjective Evaluation
Informal listening tests corroborate the quantitative findings. The model generally applies the correct edits at the specified times, with minimal distortion to unedited regions. Deletions are typically clean, with plausible background inpainting. Insertions and enhancements produce events of the correct class, though enhanced events may differ in timbre from the original. When conditioning information is ablated, the model often fails to localize or apply the correct edit.
Limitations and Future Directions
While Recomposer demonstrates the feasibility of event-level generative audio editing, several limitations remain:
- The vocabulary of event classes is restricted to AudioSet labels; richer, free-form text descriptions are not yet supported.
- The model always generates output events at a fixed TBR, limiting control over event prominence.
- The system relies on accurate event rolls, which require robust sound event recognition as a preprocessing step.
- The synthetic data generation process may introduce artifacts due to mismatched recording conditions between targets and backgrounds.
Future work should address these limitations by expanding the range of supported edit descriptions, incorporating video or other modalities for conditioning, and developing more sophisticated training data pipelines. Improved evaluation metrics that better capture perceptual edit quality and localization are also needed.
Conclusion
Recomposer presents a practical approach to generative audio editing at the event level, leveraging explicit timing and class conditioning to enable precise deletion, insertion, and enhancement of sound events in complex scenes. The model architecture, synthetic data strategy, and ablation analyses collectively demonstrate the importance of fine-grained conditioning for controllable audio generation. While further work is required to generalize beyond fixed class vocabularies and synthetic data, Recomposer establishes a foundation for future research in event-centric, user-guided audio editing.

