- The paper proposes a KVCache-centric, disaggregated architecture that separates prefill and decoding to optimize LLM serving throughput.
- It introduces a novel layer-wise prefill mechanism and intelligent scheduling, achieving up to a 525% increase in throughput over baseline systems.
- The design incorporates early rejection strategies to maintain low latency (TTFT and TBT) and manage overload conditions effectively.
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving
Introduction
Mooncake introduces a KVCache-centric disaggregated architecture for serving LLMs with a focus on efficient resource utilization and maintaining Service Level Objectives (SLOs) related to latency, such as Time to First Token (TTFT) and Time Between Tokens (TBT). This architecture is designed to separate the prefill and decoding processes, and utilizes underused CPU, DRAM, and SSD resources within the GPU cluster to implement an efficient structure for high throughput of LLM serving under varied workloads and overload conditions.
Architectural Overview
Mooncake employs a disaggregated architecture that separates the prefill and decoding stages to enhance efficiency and scalability in LLM serving. The core of Mooncake is structured around the management and scheduling of a global KVCache, which is implemented using a combination of CPU memory, SSD, and advanced network technologies like GPUDirect for efficient data transfer. This architecture allows Mooncake to manage the inflow and outflow of requests efficiently, especially during different stages of processing which demand varied resources and computational throughput.
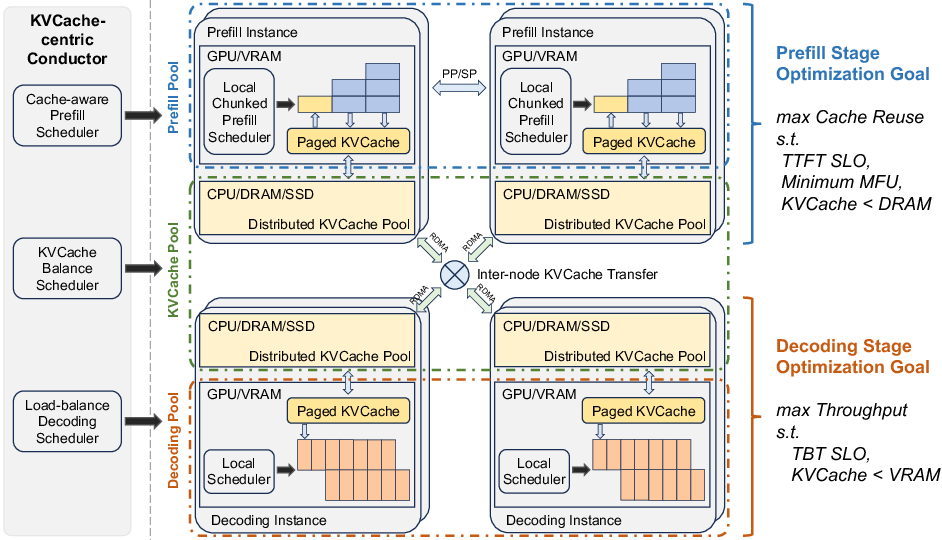
Figure 1: Mooncake Architecture
KVCache Management
KVCache Pool and Scheduling
The KVCache in Mooncake plays a critical role in optimizing throughput and meeting latency requirements. Its management includes intelligently scheduling requests based on cache usage, workload distribution, and anticipated computational requirements. The KVCache is stored as paged blocks in the CPU memory, enabling efficient transfer across nodes, managed by the scheduling component known as the Conductor. The Conductor handles the complex scheduling of prefill and decoding operations, ensuring that SLOs are met while maximizing the reuse of cached computations.
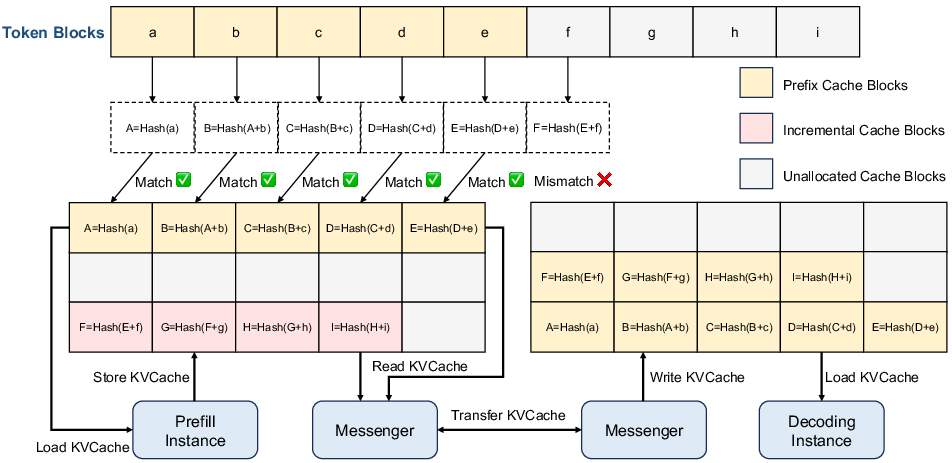
Figure 2: The KVCache pool in CPU memory. Each block is attached with a hash value determined by both its own hash and its prefix for deduplication.
Layer-wise Prefill
An innovative feature is the layer-wise prefill mechanism, which asynchronously handles layer-level computations and data transfer to minimize latency during prefill operations. This setup enables the efficient overlap of computation and data transfer, thus maximizing GPU resource utilization without violating memory limits. The chunking of prefill operations across nodes further aids in handling long-context inputs without degrading performance, allowing for the consistent attainment of SLOs.
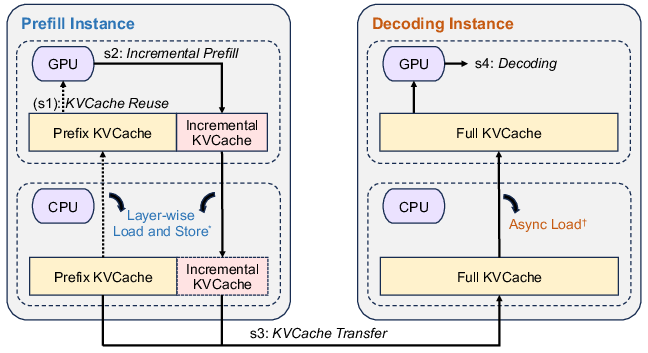
Figure 3: Workflow of inference instances. (
) For prefill instances, the load and store operations of the KVCache layer are performed layer-by-layer and in
parallel with prefill computation to mitigate transmission overhead.*
Scheduling Techniques in Overload Scenarios
Mooncake's design incorporates a scheduling mechanism that not only focuses on efficiency during normal operation but also includes strategies for managing scenarios when the system is overloaded with requests. The key to this is the Early Rejection mechanism, which predicts potential future loads and makes informed decisions on whether to accept or reject incoming requests to prevent resource wastage. Two primary approaches, Early Rejection and Early Rejection Based on Prediction, help stabilize system performance and maintain high throughput even during peak times.
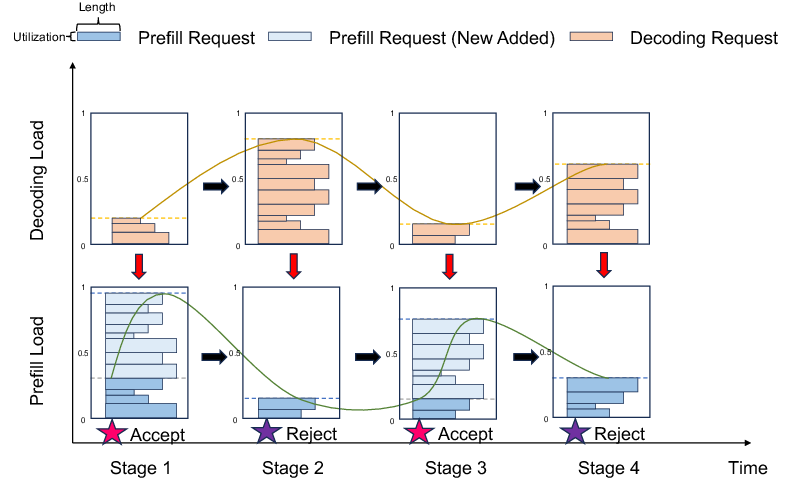
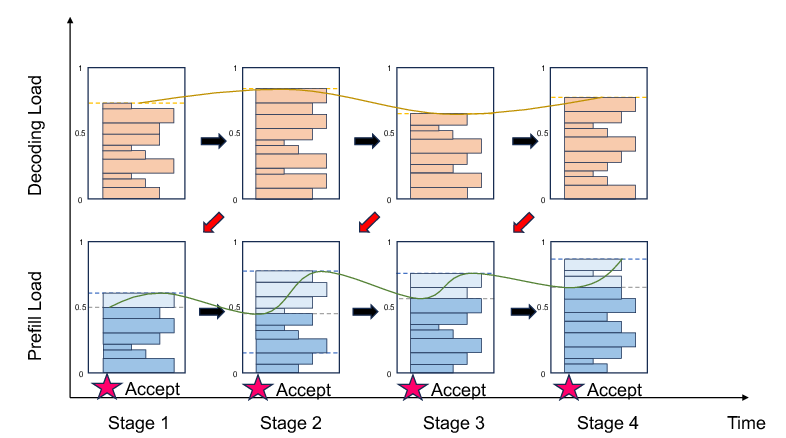
Figure 4: Instance load when applying Early Rejection and Early Rejection Based on Prediction.
Both public datasets and real-world trace data were used to evaluate Mooncake's performance. These experiments demonstrated that Mooncake can improve throughput significantly while adhering to TTFT and TBT constraints. Compared to baseline systems like vLLM, Mooncake achieved up to a 525% increase in throughput in some scenarios, handling 75% more requests under real workloads without sacrificing response times or user experience adversely.
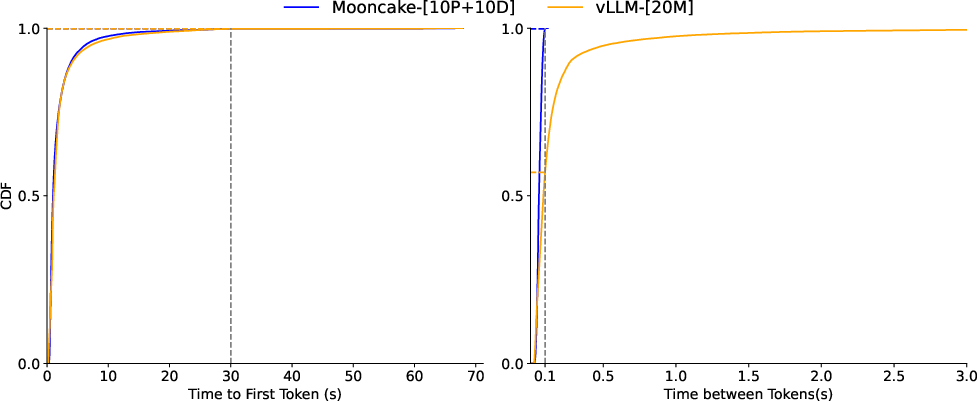
Figure 5: Request TTFT and TBT distributions of Mooncake and vLLM under real workloads.
Conclusion
Mooncake offers a robust framework for LLM serving, emphasizing enhanced throughput and compliance with latency SLOs through a clever disaggregation of resources and focused management of KVCache. Its capability to efficiently handle increasing loads and varying request types highlights its suitability for modern LLM serving requirements. While Mooncake already demonstrates significant improvements over existing solutions, future work is expected to further explore the integration of heterogeneous resources and more advanced memory management strategies to push the boundaries of efficient LLM servicing.