- The paper presents a method that reduces KV cache transfer latency by up to 96% through memory layout optimization and dynamic load-aware scheduling.
- It employs NCCL-based pipelines to achieve speed-ups of 24x in single-node setups and 15x in multi-node setups.
- FlowKV significantly enhances system throughput and resource utilization across disaggregated LLM inference environments, including heterogeneous GPU clusters.
FlowKV: A Disaggregated Inference Framework with Low-Latency KV Cache Transfer and Load-Aware Scheduling
The paper "FlowKV: A Disaggregated Inference Framework with Low-Latency KV Cache Transfer and Load-Aware Scheduling" (2504.03775) presents an advanced framework for improving the performance of disaggregated LLM inference systems by optimizing KV cache transfer and load balancing between computing nodes. Below, the framework's methodology, evaluation, and implications are detailed.
Introduction
Transformer-based LLMs are pivotal in various AI applications, each typically involving two distinct stages during inference: prefill and decode. These stages are separated in disaggregated deployment models to enhance efficiency and scalability. However, this separation introduces significant KV cache transfer delays, further complicated by imbalanced loads due to fixed node roles.
FlowKV tackles this inefficiency by reducing KV cache transfer latency and introducing dynamic load scheduling. The framework achieves a notable 96% reduction in average KV cache transfer time and enhances system throughput substantially across various workloads, including those with heterogeneous GPUs.
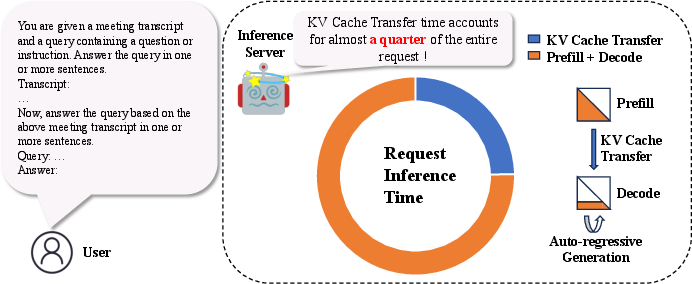
Figure 1: Time distribution of Prefill + Decode and KV Cache Transfer in a single request.
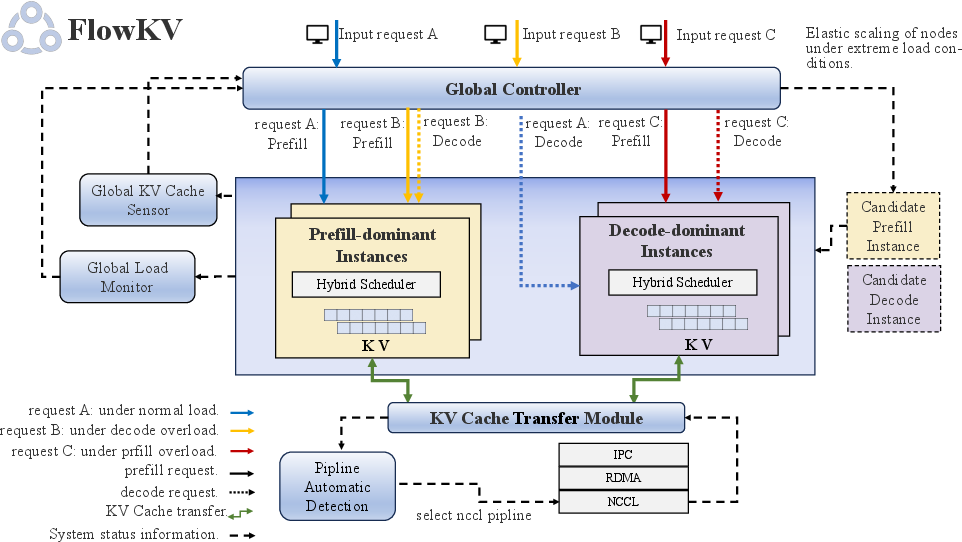
FlowKV Framework
FlowKV is designed to facilitate rapid KV cache transfer between prefill (P) nodes and decode (D) nodes while employing a load-aware scheduler to ensure balanced resource utilization.
Architecture
The FlowKV framework (Figure 2) comprises the following components:
Methodology
The core innovations in FlowKV include:
KV Cache Transfer Optimization
FlowKV enhances transfer efficiency by restructuring the KV cache memory layout to minimize the number of transfers required (i.e., from O(n) times to O(1)). This involves aligning memory accesses in contiguous blocks, significantly reducing barriers imposed by discrete memory layouts.
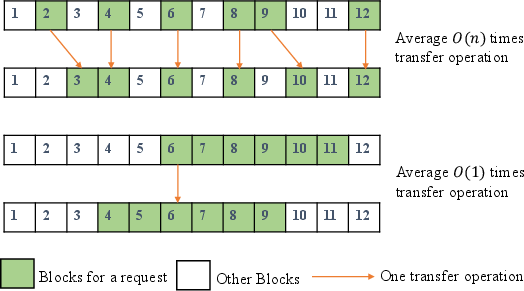
Figure 3: Optimized KV Cache transfer using contiguous memory segments.
Load-Aware Scheduling
FlowKV employs a load-aware scheduling strategy that dynamically responds to workload variations by adjusting roles and allocations of P and D nodes. This scheduler reduces hardware-induced latency during inference by monitoring each node’s load metrics, such as utilization and queue lengths, and readjusting tasks between nodes based on current demand.
Experimental Evaluation
Homogeneous and Heterogeneous Deployments
Experiments demonstrate that FlowKV substantially surpasses existing frameworks (Mooncake, vLLM-Disagg) in throughput across different LLM sizes and deployment configurations. Specifically, FlowKV showed up to 95% improvement in throughput for simulated data scenarios and substantial latency reductions in heterogeneous settings using real-world datasets.
KV Cache Transfer Latency
The comparison in KV cache transfer latency indicates that FlowKV's NCCL-based optimization achieves 24x and 15x speed-ups in single-node and multi-node setups, respectively, relative to traditional layerwise transfer methods.
Implications and Conclusions
FlowKV introduces a robust framework for enhancing the throughput and reducing the latency of disaggregated LLM inference systems. Its significant improvements in KV cache transfer latency and resource utilization suggest broader applicability across varied infrastructure configurations, including those with heterogeneous GPU clusters. These innovations could drive AI deployments toward more efficient, scalable solutions, setting a benchmark for future research in distributed AI inference frameworks.
The paper's contributions advance the state of disaggregated inference and offer compelling insights into optimizing system configurations for modern generative AI applications. Future work may explore integrating these methods into broader AI ecosystem applications, increasing fault tolerance, and exploring implications for new AI hardware designs.