- The paper presents VoltanaLLM, which employs phase-aware, fine-grained frequency control to reduce energy consumption and satisfy strict SLOs.
- It integrates EcoFreq, EcoRoute, and EcoPred modules to dynamically adjust GPU frequency and route requests based on real-time load and latency predictions.
- Empirical results demonstrate up to 36.3% energy savings compared to static frequency baselines while maintaining comparable SLO attainment rates.
VoltanaLLM: Feedback-Driven Frequency Control and State-Space Routing for Energy-Efficient LLM Serving
Motivation and Problem Characterization
The rapid proliferation of LLM-powered interactive applications has led to a surge in inference workloads, making energy efficiency a critical concern for sustainable deployment. The paper introduces VoltanaLLM, a system that addresses the dual challenge of minimizing energy consumption while meeting stringent SLOs (e.g., TTFT and ITL) in LLM serving. The authors identify three key empirical observations: (1) a non-monotonic, U-shaped energy-frequency relationship in both prefill and decode phases, (2) strong temporal variation in prefill/decode demand, and (3) batch size boundary-induced inefficiencies, particularly in decode. These insights motivate a phase-aware, fine-grained control strategy that leverages the architectural decoupling of prefill and decode in modern serving systems.
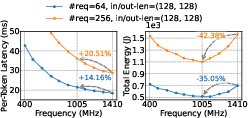
Figure 1: The per-token latency decreases with frequency, but energy consumption follows a U-shaped curve, indicating an optimal frequency for minimal energy per token.
System Architecture and Control-Theoretic Design
VoltanaLLM is architected around three core modules: EcoFreq (feedback-driven frequency controller), EcoRoute (state-space navigation-based router), and EcoPred (lightweight latency predictor). The system is built atop a P/D disaggregated serving architecture, enabling independent control of prefill and decode instances.
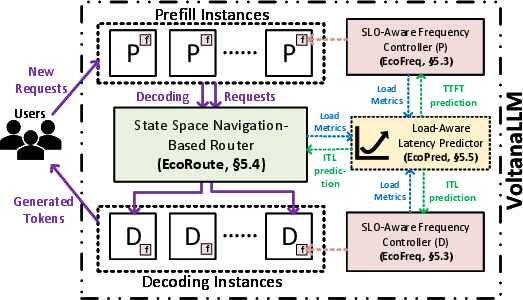
Figure 2: VoltanaLLM architecture: requests are handled by prefill instances, then routed to decode instances with per-instance frequency control and SLO-aware routing.
EcoFreq: Fine-Grained, Phase-Specific Frequency Control
EcoFreq operates as a per-instance, per-phase controller, running in a separate process to avoid engine loop overhead. It receives real-time load metrics and batch information, queries EcoPred for latency predictions at candidate frequencies, and selects the lowest frequency that satisfies the SLO. The control cycle is sub-4ms, enabling per-iteration responsiveness, which is critical for adapting to rapid batch size fluctuations, especially in prefill.
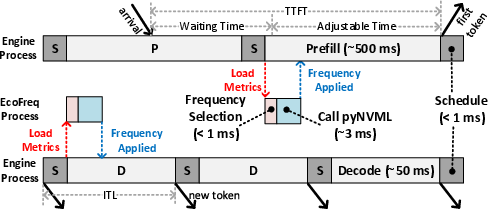
Figure 3: EcoFreq runs asynchronously, receiving load metrics and setting GPU frequency with minimal overhead.
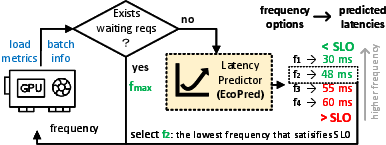
Figure 4: EcoFreq algorithm: selects the lowest frequency meeting SLO constraints based on predicted latency for each batch.
EcoRoute: State-Space Routing for Decode Instances
EcoRoute exploits the state space of decode instances, defined by the number of active requests and tokens in KV cache. It performs a "what-if" analysis for each routing decision, evaluating the impact of assigning a request to each instance on the required frequency and SLO attainment. The router asymmetrically dispatches requests to avoid batch size boundaries that would force high-frequency operation, thus maximizing the time spent at energy-optimal frequencies.
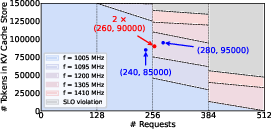
Figure 5: State space of a decode instance, with axes for request and KV token counts; color encodes EcoFreq-selected frequency.
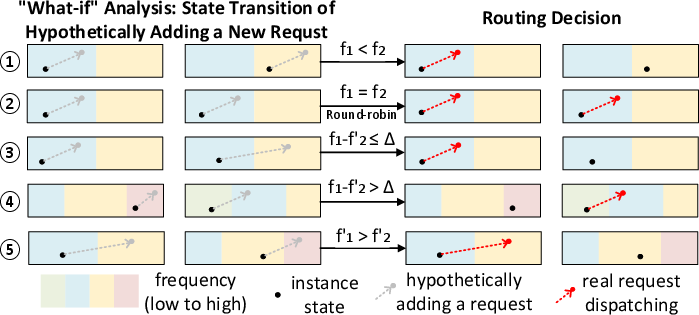
Figure 6: EcoRoute routing logic: "what-if" analysis determines the routing that avoids unnecessary frequency increases.
EcoPred: Lightweight, Load-Aware Latency Prediction
EcoPred employs linear regression models, calibrated offline, to predict TTFT and ITL as functions of batch size, request count, and KV cache size at each frequency. This enables fast, interpretable, and accurate latency estimation, which is essential for the responsiveness and reliability of both EcoFreq and EcoRoute.
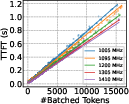
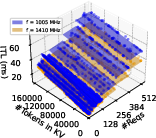
Figure 7: TTFT prediction as a function of batched token count, showing strong linearity and high predictive accuracy.
Empirical Analysis and Key Results
VoltanaLLM is evaluated on multiple SOTA LLMs (Ministral-3B, LLaMA-3.1-8B, Qwen3-32B) and real-world datasets (ShareGPT, LMSYS-Chat-1M) using SGLang as the serving backend. The system is compared against SGLang with static frequency (1005 MHz, 1410 MHz) and round-robin routing.
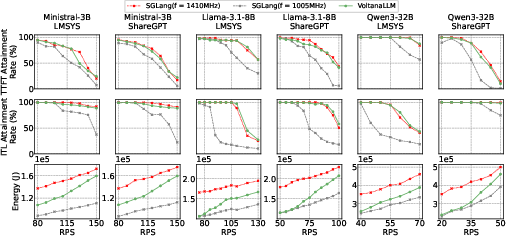
Figure 8: VoltanaLLM achieves SLO attainment rates comparable to static max-frequency baseline, with up to 36.3% energy savings.
Key findings:
- VoltanaLLM maintains SLO attainment rates on par with static max-frequency serving, while reducing energy consumption by up to 36.3%.
- Static low-frequency serving (1005 MHz) yields lower energy but fails to meet SLOs under load.
- The energy benefit is most pronounced at low request rates, where VoltanaLLM operates predominantly at low frequency, but remains significant at higher loads due to adaptive control.
Ablation and Sensitivity Analyses
The authors conduct extensive ablations to isolate the contributions of EcoFreq and EcoRoute, and to assess sensitivity to SLO profiles, frequency granularity, and control interval.
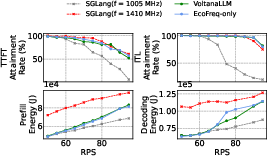
Figure 9: EcoFreq alone yields substantial energy savings; EcoRoute provides additional benefit for decode instances.
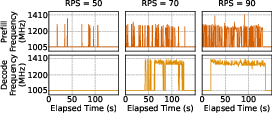
Figure 10: Frequency dynamics: at low request rates, instances run at low frequency; high rates increase high-frequency operation.
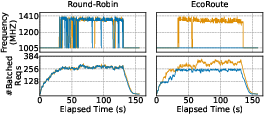
Figure 11: EcoRoute maintains one decode instance below the batch size boundary, enabling lower frequency operation compared to round-robin.
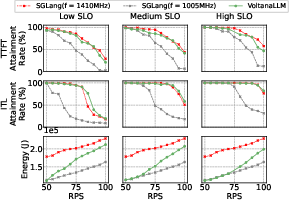
Figure 12: VoltanaLLM generalizes to different SLO profiles, consistently achieving high SLO attainment and energy savings.
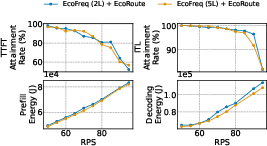
Figure 13: Increasing frequency granularity yields marginal additional energy savings, primarily for decode.
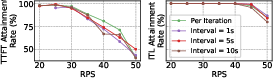
Figure 14: Per-iteration frequency control is critical for SLO attainment, especially in prefill; window-based control degrades performance.
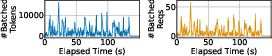
Figure 15: Prefill batch size and token count fluctuate rapidly, necessitating fine-grained control.
Theoretical and Practical Implications
VoltanaLLM demonstrates that phase-aware, feedback-driven control, enabled by P/D disaggregation, is essential for energy-efficient LLM serving under SLO constraints. The U-shaped energy-frequency curve invalidates the naive assumption that lower frequency always yields lower energy, and highlights the need for dynamic, workload-adaptive policies. The state-space routing approach in EcoRoute is a novel application of control-theoretic principles to inference serving, and the lightweight, interpretable latency prediction model in EcoPred provides a practical alternative to black-box ML predictors.
The system's modularity and reliance on offline profiling for calibration make it readily deployable in production environments. The results suggest that further gains may be achievable by integrating more granular hardware telemetry, extending the state space to include additional resource metrics, or incorporating learning-based controllers for non-stationary workloads.
Conclusion
VoltanaLLM provides a comprehensive, control-theoretic solution to the problem of energy-efficient, SLO-aware LLM serving. By leveraging phase-specific frequency control and state-space-aware routing, the system achieves substantial energy savings without compromising latency guarantees. The work establishes a new baseline for sustainable LLM inference and opens avenues for further research in adaptive, resource-aware serving architectures.

