- The paper presents MiniCache, which compresses KV caches in LLMs by merging similar states across layers to significantly reduce memory usage.
- It employs a dual strategy of cross-layer merging using SLERP and token retention, ensuring near-lossless performance while reducing computational demands.
- Key experimental results include up to 5.02× compression, a 5× boost in inference throughput, and a notable 41% memory footprint reduction compared to FP16 baselines.
MiniCache: KV Cache Compression in Depth Dimension for LLMs
LLMs have become critical tools in artificial general intelligence, yet their computational demands pose significant challenges to efficient deployment. The "MiniCache: KV Cache Compression in Depth Dimension for LLMs" paper (2405.14366) introduces an innovative approach called MiniCache, which aims to address the memory strain associated with the Key-Value (KV) cache in LLM inference processes. This essay provides a detailed summary of the methodologies, findings, and implications of this work, focusing on its technical contributions and practical impacts.
Introduction to KV Caching Challenges
LLMs, such as GPT-3 and LLaMA models, are typically deployed using KV caching techniques. The KV cache stores key-value pairs of previously generated tokens, thereby reducing redundancy in computations during autoregressive text generation. However, the memory footprint of KV caches increases linearly with sequence length, leading to prohibitive demands for GPUs during long-context input applications. This paper argues that while quantization and sparsity have addressed intra-layer redundancies, they overlook significant inter-layer redundancies. MiniCache proposes to compress KV caches in the depth dimension by exploiting this inter-layer redundancy, merging similar cache states from adjacent layers to significantly reduce memory usage.
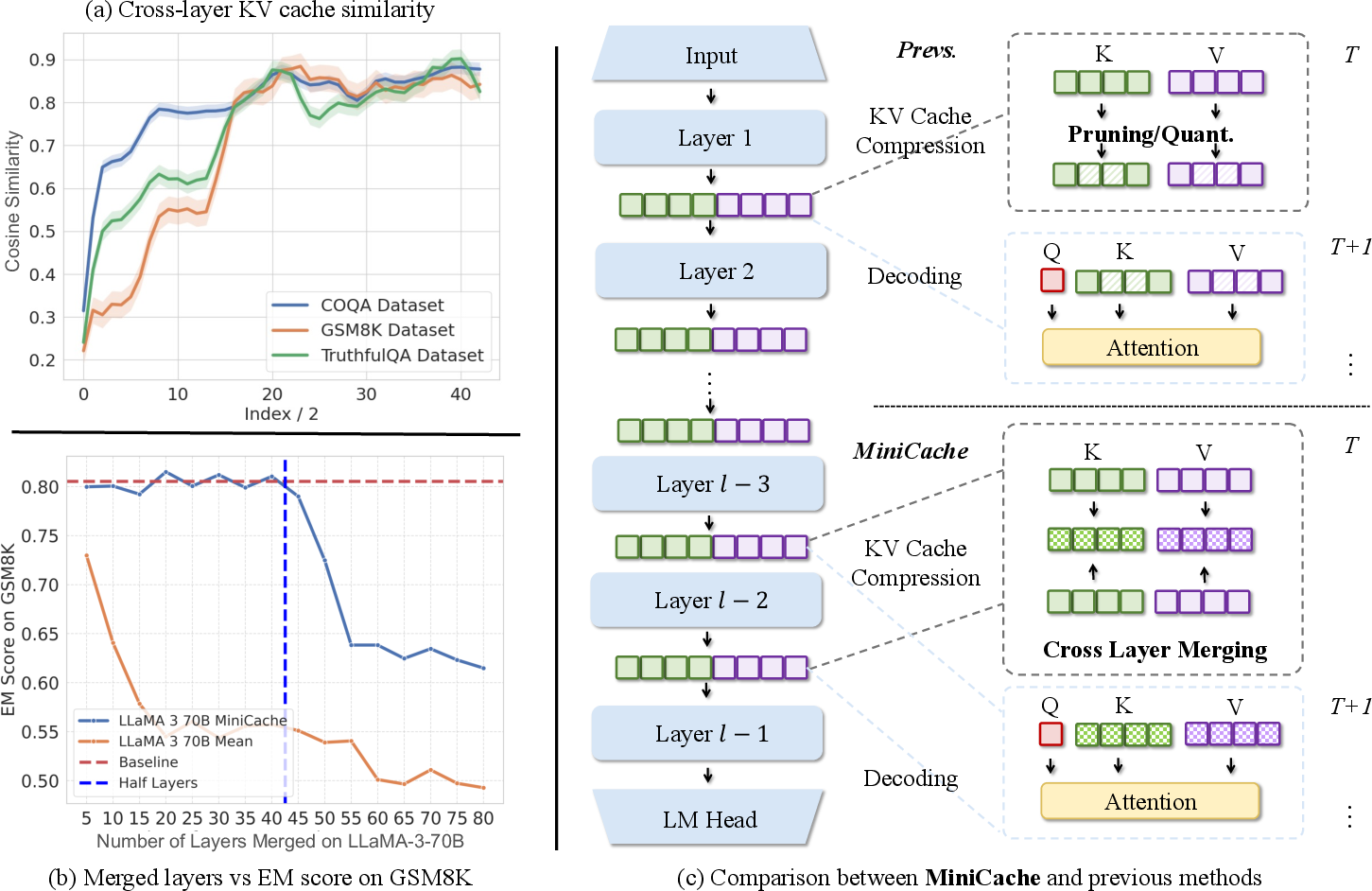
Figure 1: Overview of MiniCache strategy showcasing KV cache similarities between adjacent layers and MiniCache's performance compared to baselines.
Methodology: MiniCache Design
The core contribution of MiniCache lies in two components: cross-layer merging and token retention. The method starts from the midpoint of layer depth, leveraging high similarity in KV cache states between adjacent middle-to-deep layers. The merging process involves decomposing cache states into magnitudes and directional components, interpolating directions while preserving magnitudes, akin to weight normalization techniques.
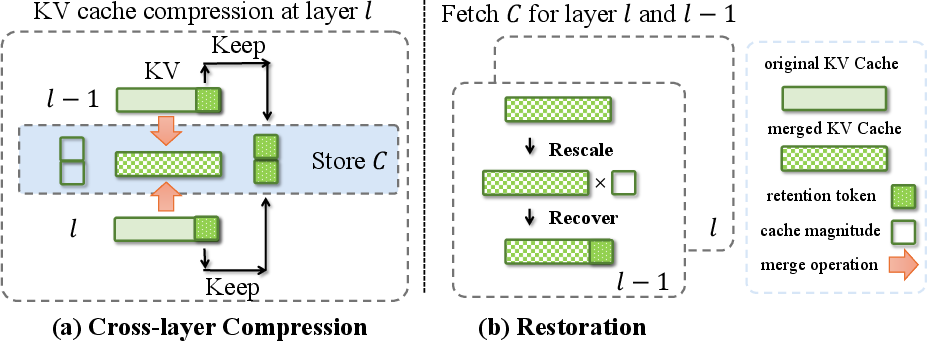
Figure 2: Illustration of MiniCache method, detailing cross-layer compression and cache merging strategies.
This interpolation, facilitated by Spherical Linear intERPolation (SLERP), maintains geometric integrity, ensuring semantic preservation during cache consolidation. Tokens exhibiting low similarity are separately retained, minimizing performance loss due to their distinct semantic contributions.
Experimental Evaluation
Through extensive evaluation across various LLMs, including LLaMA-2, LLaMA-3, Phi-3, and Mixtral models, MiniCache has demonstrated its robustness. Key performance metrics reveal compression ratios up to 5.02×, inference throughput improvements by approximately 5×, and a 41% reduction in memory footprint compared to traditional FP16 cache baselines. These improvements are achieved while maintaining near-lossless performance on several language understanding and generation benchmarks.
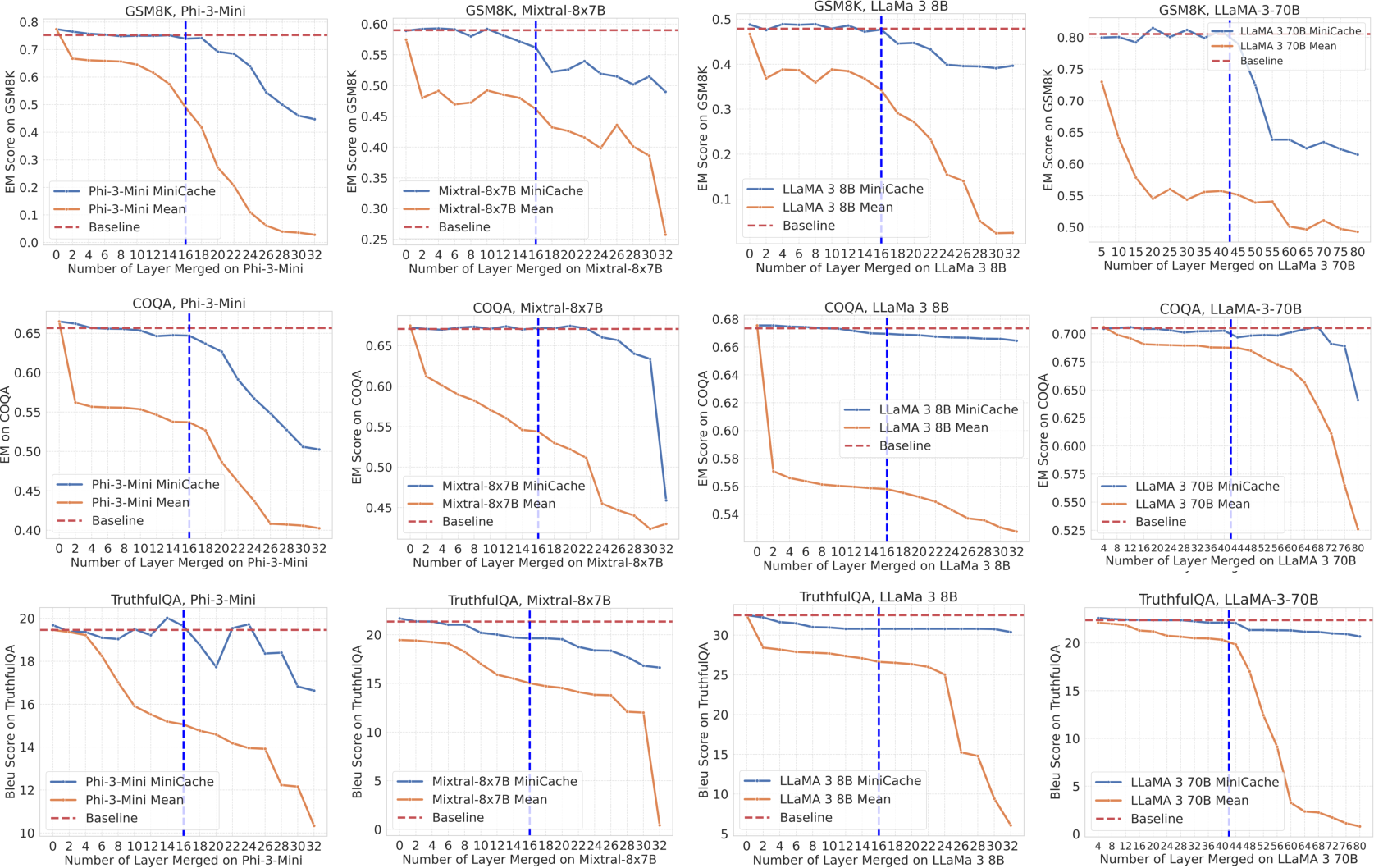
Figure 3: Performance comparison across datasets, highlighting superior compression and efficiency of MiniCache compared to baselines.
Implications and Future Work
MiniCache presents notable advancements in reducing the computational and memory requirements for deploying LLMs, potentially making such models more accessible for deployment on resource-constrained environments like mobile devices. The training-free nature and general applicability of MiniCache complement existing compression strategies without the need for model retraining.
Future research directions may explore more sophisticated merging algorithms or cross-multiple-layer compression techniques, thereby further enhancing efficiency and scalability for LLM applications. Integrating such approaches with dynamic inference strategies and layer pruning could further optimize performance and reduce computational overhead.
Conclusion
The MiniCache approach represents a significant step forward in addressing the challenges of KV cache management in LLMs. By innovatively exploiting inter-layer redundancies, the paper effectively demonstrates substantial memory savings and throughput enhancements without compromising model performance. MiniCache not only contributes to efficient LLM deployment but also sets the stage for further exploration of compression techniques in AI. This work could catalyze advancements in making AI models more adaptable and sustainable for diverse computational environments.