On the Importance of Uncertainty in Decision-Making with Large Language Models
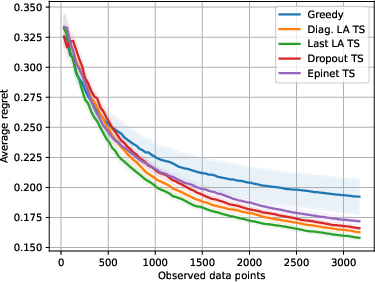
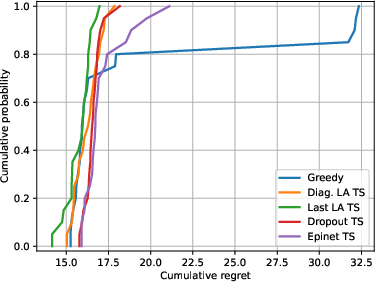
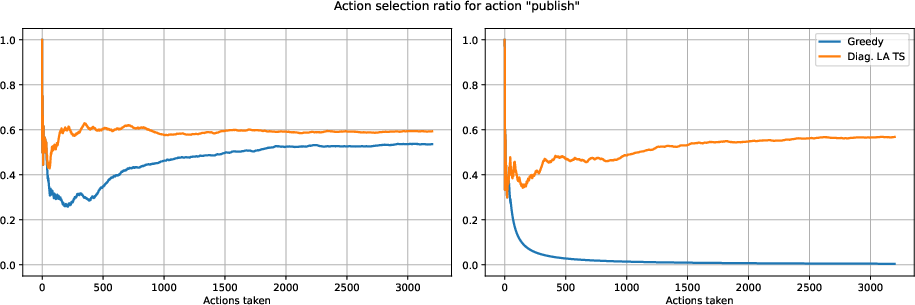
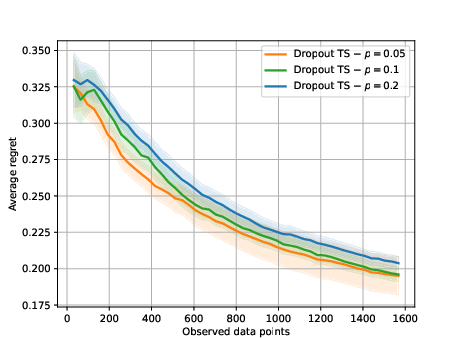
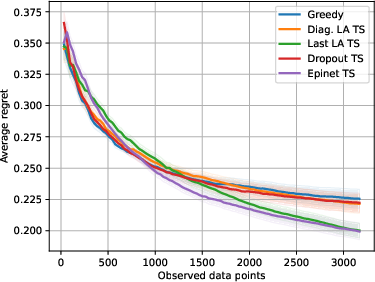
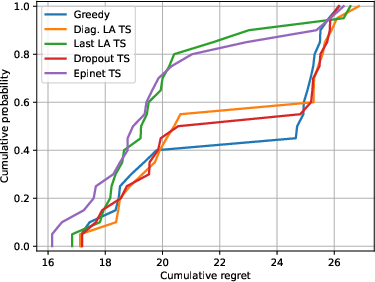
Abstract: We investigate the role of uncertainty in decision-making problems with natural language as input. For such tasks, using LLMs as agents has become the norm. However, none of the recent approaches employ any additional phase for estimating the uncertainty the agent has about the world during the decision-making task. We focus on a fundamental decision-making framework with natural language as input, which is the one of contextual bandits, where the context information consists of text. As a representative of the approaches with no uncertainty estimation, we consider an LLM bandit with a greedy policy, which picks the action corresponding to the largest predicted reward. We compare this baseline to LLM bandits that make active use of uncertainty estimation by integrating the uncertainty in a Thompson Sampling policy. We employ different techniques for uncertainty estimation, such as Laplace Approximation, Dropout, and Epinets. We empirically show on real-world data that the greedy policy performs worse than the Thompson Sampling policies. These findings suggest that, while overlooked in the LLM literature, uncertainty plays a fundamental role in bandit tasks with LLMs.
- Near-optimal regret bounds for thompson sampling. Journal of the ACM (JACM), 64(5):1–24, 2017.
- Bayesian inference in statistical analysis. John Wiley & Sons, 2011.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Grounding large language models in interactive environments with online reinforcement learning. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 3676–3713. PMLR, 2023. URL https://proceedings.mlr.press/v202/carta23a.html.
- An empirical evaluation of thompson sampling. Advances in neural information processing systems, 24, 2011.
- Introspective tips: Large language model for in-context decision making. arXiv preprint arXiv:2305.11598, 2023.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Laplace redux-effortless bayesian deep learning. Advances in Neural Information Processing Systems, 34:20089–20103, 2021.
- Yarin Gal. Uncertainty in deep learning. 2016.
- Bayesian convolutional neural networks with bernoulli approximate variational inference. arXiv preprint arXiv:1506.02158, 2015.
- Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pp. 1050–1059. PMLR, 2016.
- Pal: Program-aided language models. In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- Algorithmic content moderation: Technical and political challenges in the automation of platform governance. Big Data & Society, 7(1):2053951719897945, 2020.
- Alex Graves. Practical variational inference for neural networks. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/file/7eb3c8be3d411e8ebfab08eba5f49632-Paper.pdf.
- Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. arXiv preprint arXiv:2305.11554, 2023.
- Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine Learning, 110:457–506, 2021.
- Parallelised bayesian optimisation via thompson sampling. In International Conference on Artificial Intelligence and Statistics, pp. 133–142. PMLR, 2018.
- What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems, 30, 2017.
- Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Motif: Intrinsic motivation from artificial intelligence feedback. arXiv preprint arXiv:2310.00166, 2023.
- Limitations of the empirical fisher approximation for natural gradient descent. Advances in neural information processing systems, 32, 2019.
- Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30, 2017.
- Pre-trained language models for interactive decision-making. Advances in Neural Information Processing Systems, 35:31199–31212, 2022.
- “how advertiser-friendly is my video?”: Youtuber’s socioeconomic interactions with algorithmic content moderation. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW2):1–25, 2021.
- Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies, pp. 142–150, 2011.
- David JC MacKay. Bayesian interpolation. Neural computation, 4(3):415–447, 1992.
- Augmented language models: a survey. arXiv preprint arXiv:2302.07842, 2023.
- OpenAI. Gpt-4 technical report, 2023.
- Epistemic neural networks. Advances in Neural Information Processing Systems, 36, 2023a.
- Approximate thompson sampling via epistemic neural networks. In Proceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, UAI ’23. JMLR.org, 2023b.
- Training language models to follow instructions with human feedback, 2022.
- Improving language understanding by generative pre-training. 2018.
- Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. In International Conference on Learning Representations, 2018.
- A tutorial on thompson sampling. Foundations and Trends® in Machine Learning, 11(1):1–96, 2018.
- Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- William R Thompson. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25(3-4):285–294, 1933.
- Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- “at the end of the day facebook does what it wants” how users experience contesting algorithmic content moderation. Proceedings of the ACM on human-computer interaction, 4(CSCW2):1–22, 2020.
- Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Bandit problems with side observations. IEEE Transactions on Automatic Control, 50(3):338–355, 2005.
- Explicit inductive bias for transfer learning with convolutional networks. In International Conference on Machine Learning, pp. 2825–2834. PMLR, 2018.
- Gpt4tools: Teaching large language model to use tools via self-instruction. arXiv preprint arXiv:2305.18752, 2023a.
- Foundation models for decision making: Problems, methods, and opportunities. arXiv preprint arXiv:2303.04129, 2023b.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.