- The paper introduces an empirical comparison showing NeuralLinear's superior performance by achieving low cumulative regret across diverse tasks.
- It evaluates various uncertainty estimation techniques—including variational inference, dropout, and bootstrapping—addressing the exploration-exploitation trade-off.
- It emphasizes that decoupling representation learning from uncertainty estimation is key to robust, scalable online decision-making.
Empirical Evaluation of Bayesian Deep Networks for Thompson Sampling in Contextual Bandits
Introduction
This paper presents a comprehensive empirical study of Bayesian deep learning methods for uncertainty estimation in sequential decision-making, specifically within the contextual bandit framework using Thompson Sampling. The central question addressed is how different approximate posterior inference techniques for deep neural networks affect the exploration-exploitation trade-off and cumulative regret in online decision-making scenarios. The study benchmarks a wide range of Bayesian neural network approaches, including variational inference, expectation-propagation, dropout, Monte Carlo methods, bootstrapping, direct noise injection, and Gaussian processes, alongside linear and hybrid methods.
Thompson Sampling and Contextual Bandits
Thompson Sampling is a Bayesian approach to balancing exploration and exploitation by sampling from the posterior over models and acting greedily with respect to the sampled model. In contextual bandits, at each timestep t, the agent observes a context Xt∈Rd, selects an action at from k possible actions, receives a reward rt, and updates its internal model. The goal is to minimize cumulative regret relative to the optimal policy. The effectiveness of Thompson Sampling depends critically on the quality of the posterior approximation, especially in online settings where data is non-i.i.d. and model updates are frequent.
Posterior Approximation Algorithms
The study evaluates several classes of algorithms for posterior approximation:
- Linear Methods: Exact Bayesian linear regression serves as a baseline, with closed-form updates for the posterior over parameters. Diagonal approximations to the covariance and precision matrices are also considered to assess the impact of independence assumptions.
- NeuralLinear: A hybrid approach where a deep neural network learns a representation, and Bayesian linear regression is performed on the final layer's output. This decouples representation learning from uncertainty estimation.
- Variational Inference (VI): Mean-field VI (e.g., Bayes By Backprop) approximates the posterior by minimizing KL divergence within a tractable family, typically assuming independence across weights.
- Expectation-Propagation (EP): Black-box α-divergence minimization generalizes VI and EP, optimizing local KL divergences via stochastic gradient descent.
- Dropout: Interpreted as a Bayesian approximation, dropout is used both during training and inference to induce posterior variability.
- Monte Carlo Methods: Stochastic Gradient Langevin Dynamics (SGLD), Stochastic Gradient Fisher Scoring (SGFS), and constant-SGD inject noise into gradient updates to sample from the posterior.
- Bootstrap: Multiple models are trained on resampled datasets, and actions are selected according to randomly chosen models.
- Direct Noise Injection: Gaussian noise is injected into network parameters during action selection, with layer normalization to control scale.
- Gaussian Processes (GPs): Non-parametric Bayesian models are used as a gold-standard for uncertainty quantification, with both standard and sparse approximations.
Feedback Loop and Posterior Quality in Sequential Decision-Making
A key insight is the difference between static (supervised) and dynamic (sequential) settings. In sequential decision-making, the posterior approximation not only affects predictions but also the data collected, creating a feedback loop. Poor uncertainty estimates can lead to suboptimal exploration, resulting in data that reinforces the model's errors. The study visualizes this effect using linear bandits:



Figure 1: Two independent instances of Thompson Sampling with the true linear posterior, illustrating the variability in posterior estimates and their impact on data collection.
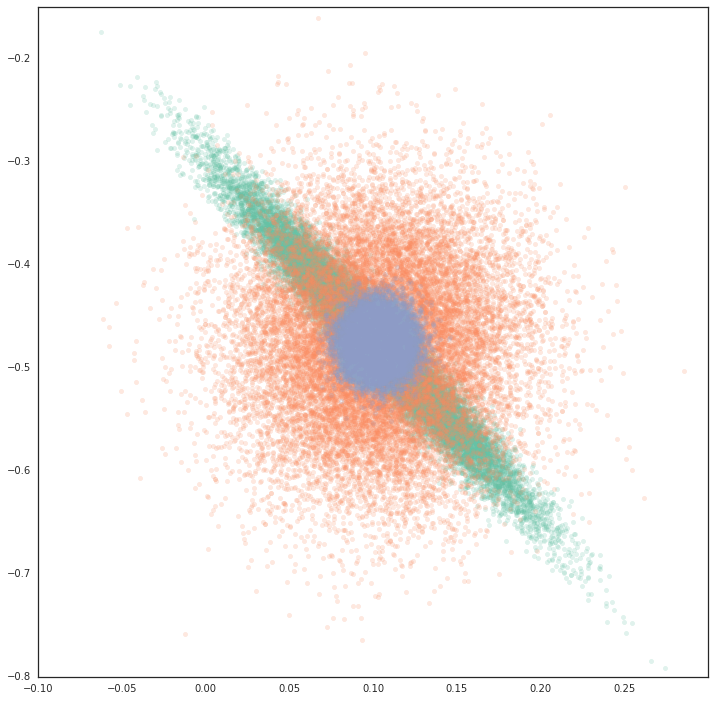
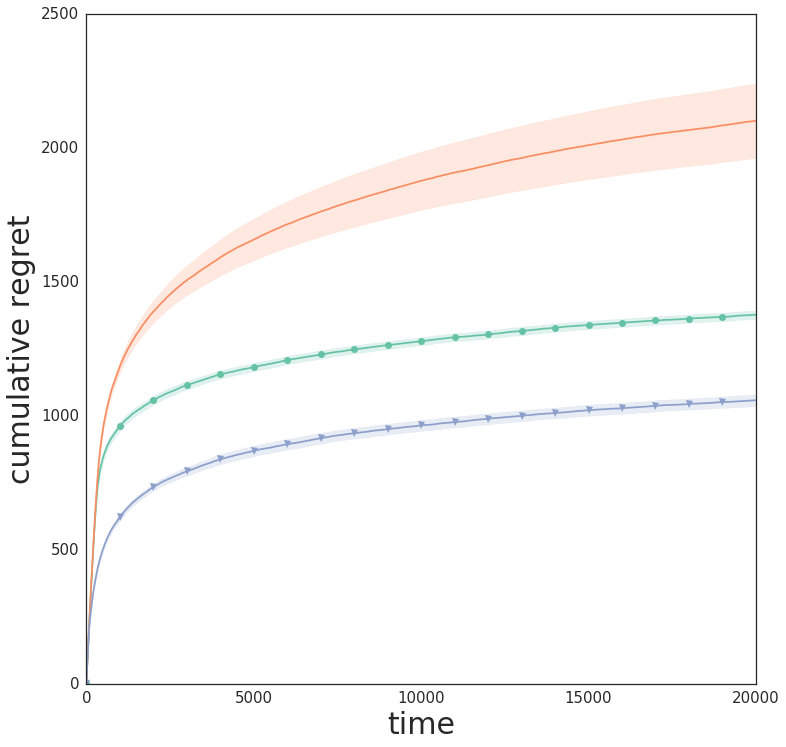
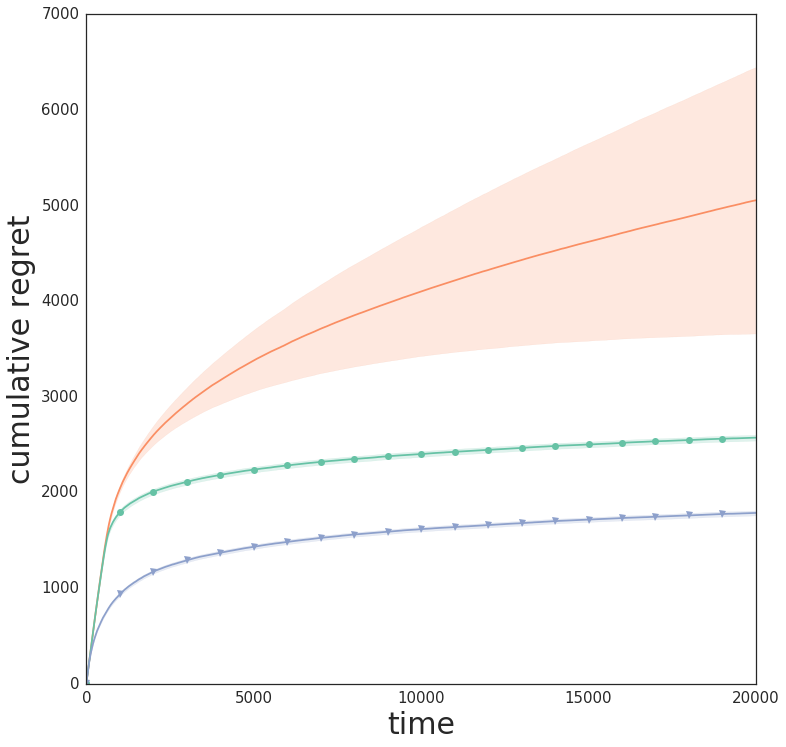
Figure 2: Posterior Approximations for linear models, comparing exact, diagonal, and precision-diagonalized posteriors.
The impact of diagonal approximations is further quantified:
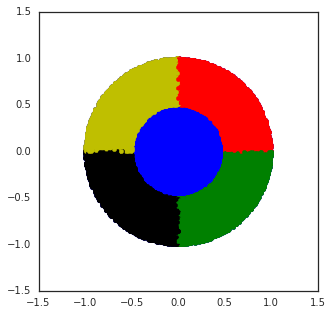
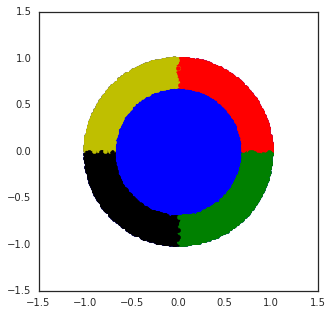
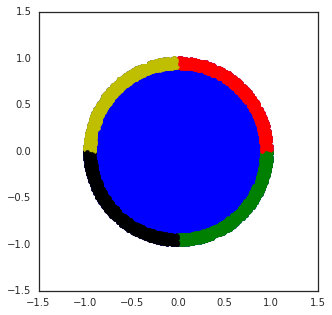
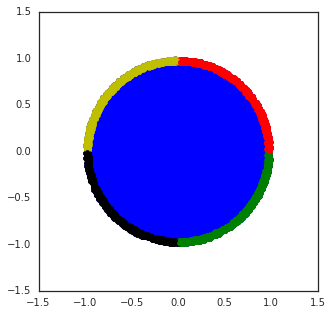
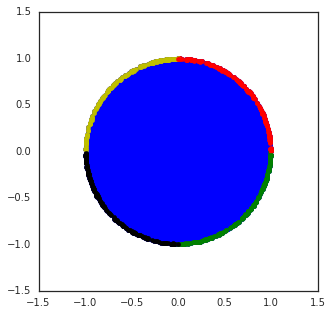
Figure 3: Wheel bandit with δ=0.5, demonstrating the challenge of exploration in synthetic tasks with sparse high-reward regions.
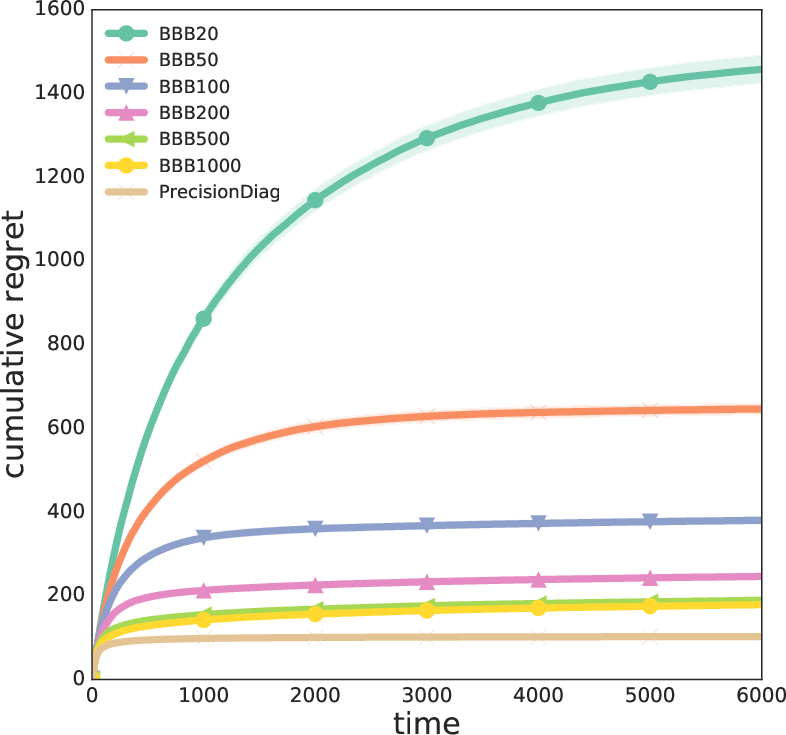
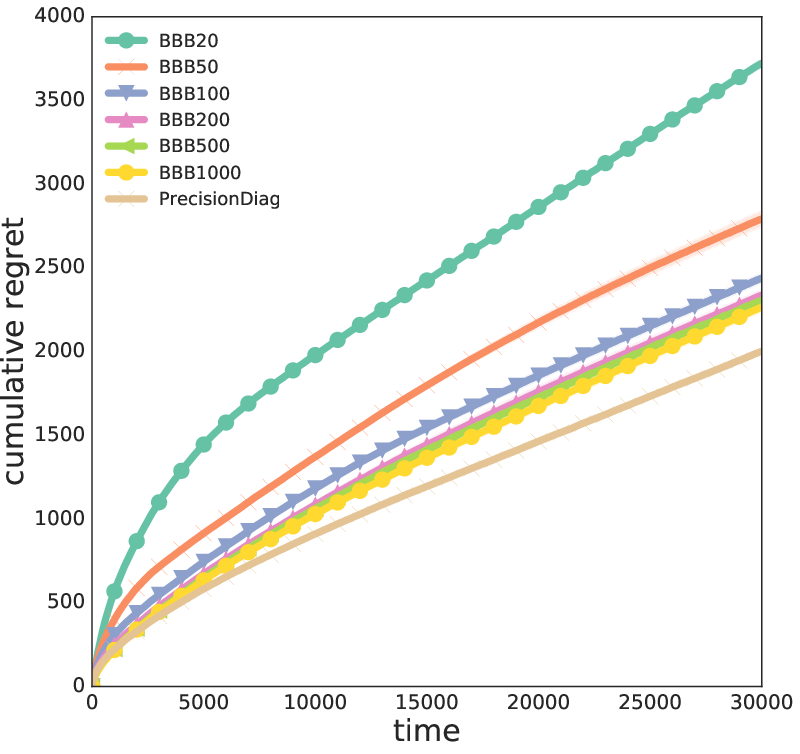
Figure 4: Cumulative regret for linear data (d=10, k=6), showing the performance gap between exact and approximate posteriors.
Empirical Results
Real-World and Synthetic Bandits
The algorithms are evaluated on a suite of real-world datasets (Mushroom, Statlog, Covertype, Financial, Jester, Adult, Census, Song) and synthetic tasks (Wheel bandit). Key findings include:
- NeuralLinear consistently achieves low cumulative regret across diverse tasks, outperforming pure neural and linear baselines, especially in problems requiring both representation learning and robust uncertainty estimation.
- Linear methods with exact or precision-diagonalized posteriors are surprisingly competitive, particularly in low-dimensional or well-specified tasks.
- VI and EP methods (e.g., BBB, AlphaDivergence) underperform due to slow convergence and sensitivity to partial optimization, which is problematic in online settings.
- Dropout, bootstrapping, and parameter noise provide moderate improvements but fail in tasks requiring deep exploration (e.g., Wheel bandit with high δ).
- Monte Carlo methods (SGFS, constant-SGD) offer robust exploration in some tasks but are computationally intensive and sensitive to hyperparameters.
- GPs excel in small-data regimes but are computationally prohibitive for large-scale problems.
Trade-offs and Implementation Considerations
- Decoupling representation learning and uncertainty estimation (NeuralLinear) is empirically superior, as it allows closed-form uncertainty quantification without requiring full posterior optimization at every step.
- Diagonal approximations to the precision matrix (mean-field VI) are preferable to diagonalizing the covariance, as they avoid over-exploration in high dimensions.
- Partial optimization of uncertainty estimates (VI, EP) can lead to catastrophic decisions; online settings require methods that converge rapidly or allow exact updates.
- Hyperparameter sensitivity is a major practical concern; robust methods should minimize the need for extensive tuning.
- Computational efficiency is critical for deployment in real-time systems; linear and NeuralLinear methods are fast and scalable, while Monte Carlo and GP methods are less practical for large-scale online learning.
Implications and Future Directions
The study demonstrates that many Bayesian deep learning methods successful in supervised learning do not translate directly to sequential decision-making due to the feedback loop between uncertainty estimation and data collection. The NeuralLinear approach, which decouples representation and uncertainty, emerges as a robust and easy-to-tune solution for contextual bandits. The findings suggest that future research should focus on scalable methods for rapid and accurate uncertainty estimation, possibly leveraging hybrid architectures and efficient online updates.
Further work is needed to extend these insights to more complex reinforcement learning domains, investigate the impact of finite data buffers, and develop principled approaches for hyperparameter selection in online settings. The challenge of deep exploration in sparse-reward environments remains open, and methods that can coordinate exploration across time and actions are of particular interest.
Conclusion
This empirical comparison highlights the limitations of current Bayesian deep learning methods for Thompson Sampling in contextual bandits and identifies promising directions for practical uncertainty estimation in sequential decision-making. Decoupled approaches like NeuralLinear offer a compelling balance of representation power and uncertainty quantification, while many sophisticated Bayesian methods require further adaptation for online learning. The results provide a reproducible benchmark and a foundation for future research in Bayesian deep reinforcement learning.