- The paper presents GP-MPPI, which pairs MPPI control with a sparse Gaussian Process subgoal recommender to overcome local minima in unknown environments.
- It leverages SGP-based occupancy and uncertainty modeling from sensor data to plan safe trajectories without relying on global maps.
- Experimental results show 100% task completion, reduced trajectory lengths, and robust real-world performance using dynamic recovery mode.
GP-guided MPPI for Efficient Navigation in Complex Unknown Cluttered Environments
Introduction and Methodological Context
This paper introduces the GP-MPPI control strategy, integrating Model Predictive Path Integral (MPPI) control with a Sparse Gaussian Process (SGP) perception model to enable safe and efficient navigation for autonomous robots in complex, unknown, and cluttered environments (2307.04019). Conventional model predictive control frameworks, particularly sampling-based variants like MPPI, are challenged by limited perception horizons and recalcitrant local minima in unknown spaces. The main innovation in this work is a dual-component architecture where an SGP-based subgoal recommender supplies the local MPPI planner with cost-optimized subgoals derived on-the-fly from local sensor data, thereby eliminating reliance on global maps or offline training.
The architecture consists of two principal modules: the GP-subgoal recommender and the local MPPI planner.
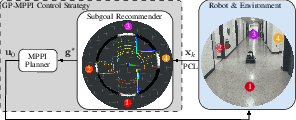
Figure 1: Architecture overview of GP-MPPI, showing SGP-based subgoal recommendation and local trajectory optimization via MPPI.
The GP-subgoal recommender observes the robot’s surroundings, reconstructs an occupancy and a corresponding variance (uncertainty) surface, and recommends the optimal subgoal to the MPPI planner, which then solves the trajectory optimization problem under collision and dynamic constraints.
Sparse Gaussian Process-based Local Perception
The perception backbone utilizes the SGP variant with inducing points to efficiently approximate the local occupancy surface and its predictive uncertainty. Sensor-derived pointclouds are projected onto a 2D spherical surface parameterized by azimuth and elevation, which is then modeled using a SGP with a rational quadratic kernel. The occupancy mean encodes traversable vs occupied regions, while the variance serves as an explicit metric of epistemic uncertainty for each location.

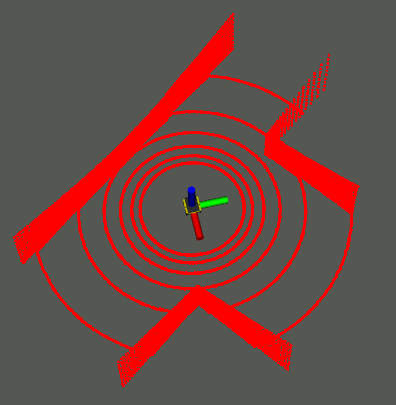


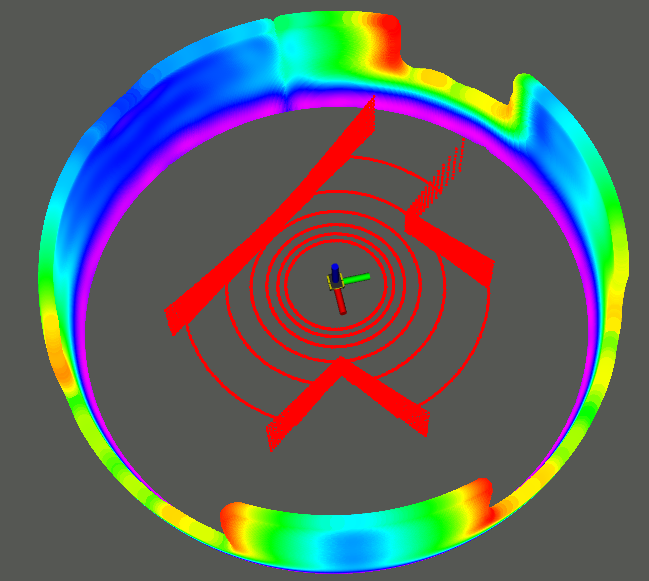
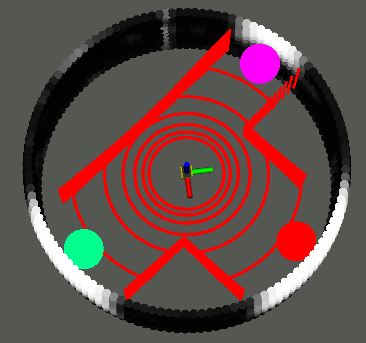
Figure 2: SGP occupancy and variance surface reconstruction for local perception with real sensor data; navigation subgoals are extracted from GP frontiers in high-variance regions.
GP frontiers, defined as centroids of high-uncertainty surface patches, are algorithmically extracted. These serve as candidate subgoals, representing inferred traversable regions immediately beyond the sensor's current field-of-view.
Subgoal Selection Policy and MPPI Integration
The recommended subgoal is selected via a cost function that balances geodesic proximity to the ultimate goal state and alignment with the robot’s current heading, with tunable weighting for distance and direction. This selection is performed online, leveraging the explicit variance structure of the SGP.
The MPPI planner receives the subgoal (in Cartesian coordinates) and generates rollouts under control and collision constraints. Trajectory costs are computed in standard MPPI fashion, with sampling-based updates informed by both state-dependent terms and control costs. Crucially, MPPI optimization is performed without the need for a globally consistent map; the required geometric priors are provided by the local SGP model.
The control framework supports both a simple mode (SM), where MPPI always tracks the recommended subgoal, and a recovery mode (RM), where subgoal following is invoked only when stagnation or local minima are detected—quantified by a drop in the predicted average velocity below a threshold.
Simulation and Experimental Analysis
Extensive simulation-based evaluation contrasts the proposed method with standard MPPI and log-MPPI in both forest-like and maze-like Gazebo environments, under conditions of local observability and partial occlusion.

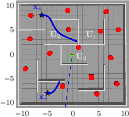
Figure 3: Log-MPPI yields local minima entrapment in forest-like and maze-like environments (blue paths), a failure mode systematically addressed by GP-MPPI.
GP-MPPI achieves 100% task completion across all evaluated scenarios, fully avoiding entrapment in local minima and collisions. This contrasts with strong performance degradation for baselines: e.g., standard MPPI and log-MPPI fail to complete any trials in the maze scenarios due to repeated local minima occupation.
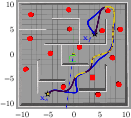
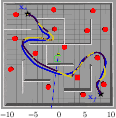
Figure 4: GP-MPPI navigational behavior in a maze environment; recovery mode segments highlighted where GP-based assistance was crucial for escaping local minima.
Activation of the recovery mode reduces average trajectory length in challenging scenarios (e.g., traveling ≈2 m less compared to simple mode in the most complex maze), and enables dynamic responsiveness via selective invocation of the subgoal recommender only when needed.
Velocity profiling further confirms that the RM transitions are triggered precisely when forward progress ceases, as evidenced by the predicted mean velocity dropping below the operational threshold.
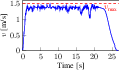
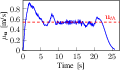
Figure 5: Empirical robot velocity profile in the maze mission, with mean predicted velocities identifying activation intervals of the recovery mode.
In real-world experiments conducted on a Jackal platform navigating a complex indoor L-shaped environment, GP-MPPI retained 100% success with no collisions or local minima over multiple trials, and delivered smooth trajectories at an average velocity of 0.80 m/s. Both vanilla MPPI and log-MPPI systematically failed these real-world tests, underscoring the necessity of the SGP-guided policy in environments with non-trivial occlusion and dead-ends.
Implications and Future Research Directions
The main theoretical implication is the demonstration that local probabilistic perception, endowed with online uncertainty quantification, suffices as a substitute for both global maps and offline value function learning in sampling-based receding horizon planning for autonomous robots. By fusing uncertainty-aware SGP inference with MPPI, the method effectively bridges classical MPPI’s horizon limitation, mitigating local minima through explicit, provably safe subgoal recommendation.
Practical impact lies in robustifying AGV navigation in real-world settings characterized by sparse and incomplete sensor data, with minimal compute requirements through the use of variational SGP. The framework is model-agnostic and compositional, allowing extension to higher-dimensional state spaces, multi-robot interaction scenarios, or integration with learned dynamic models.
Potential research avenues include:
- Extension to 3D environments and heterogeneous sensors;
- Adaptive subgoal cost shaping for improved exploration-exploitation trade-offs;
- Fusion with active perception policies for dynamically modulated uncertainty thresholds;
- Integration with RL or hybrid methods for long-term value estimation while retaining local safety guarantees.
Conclusion
This work provides an authoritative demonstration of how SGP-based online occupancy and variance modeling can augment sampling-based control for efficient and safe navigation in the absence of global priors. The GP-MPPI framework sets a new reference for robust navigation in complex, unstructured, and unknown spaces, with verified superiority over non-hierarchical MPPI methods and strong real-world deployability.

