- The paper presents a novel evaluation metric using R'enyi entropy, achieving a 0.78 Pearson correlation with Bleu scores for machine translation.
- It demonstrates that balanced token frequency distributions in efficient tokenization directly enhance model learnability and downstream performance.
- Experimental results show that tokenization strategies optimized with R'enyi metrics outperform conventional Shannon-based methods in NLP tasks.
Tokenization and the Noiseless Channel
Introduction
This paper explores the intricacies of subword tokenization within NLP pipelines, focusing on the correlation between tokenization methods and their impact on downstream model performance. It introduces an information-theoretic framework, positing that efficient channel usage—an aspect quantified by the ratio of Shannon entropy to maximum possible entropy—leads to superior tokenization. However, Shannon entropy, while optimal in certain contexts, poses limitations by disproportionately affecting low-frequency tokens. The paper proposes using R\'enyi entropy to justify efficiency, which penalizes both extreme token frequencies, particularly demonstrating strong correlation with machine translation performance metrics such as Bleu.
Tokenization and Efficiency
Tokenization, defined as the segmentation of text into tokens, significantly influences model performance. The paper considers tokenization as analogous to encoding information in a noiseless channel, aiming for efficient compression. Efficient channel usage is crucial, as it directly impacts the learnability and representational quality of tokens. The authors argue that efficient tokenization should maintain high entropy, reflecting a balanced token distribution, which facilitates learning representations across the vocabulary.
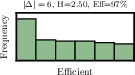
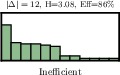
Figure 1: Examples of unigram distributions with efficient and inefficient channel usage.
To formalize this, the paper employs Shannon's Source Coding Theorem, establishing bounds on expected code lengths in relation to Shannon entropy. It further extends this framework by introducing a measure called "efficiency" to evaluate tokenization functions, offering a more nuanced view through the use of R\'enyi entropy.
R\'enyi Efficiency
R\'enyi entropy provides a generalized measure allowing adjustable penalization of token frequencies. Its flexibility helps address the shortcomings of Shannon entropy by offering a more granular control over token distribution imbalances. Particularly, the paper identifies that R\'enyi entropy at α=2.5 achieves high Pearson correlation ($0.78$) with Bleu scores, outperforming traditional Shannon-based measures.
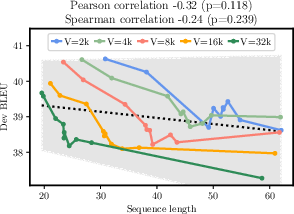
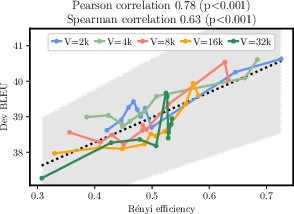
Figure 2: Efficiency of sequence length and H2.5/H0 as predictors of MT performance.
The integration of R\'enyi entropy improves prediction models for tokenization efficiency, supporting the hypothesis that it correlates strongly with model performance due to its penalization of frequent token imbalances. This insight underscores the importance of selecting optimal token frequencies tailored to specific NLP tasks.
Experimental Results
The experimental segment evaluates various tokenization strategies, including BPE, Unigram, and Morfessor, and their respective impacts on MT performance. Notably, manipulating BPE to control compression introduced variability in tokenization efficiency. The results consistently favored tokenizations optimized using R\'enyi entropy, showcasing substantial correlations with Bleu scores and highlighting the predictive capability of R\'enyi efficiency.
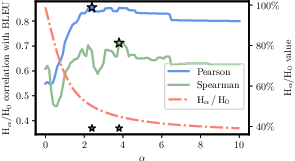
Figure 3: Correlation of R\'enyi efficiency (Hα/H0) with Bleu on train data. Maximums marked with star.
Further analysis explores the integration of tokenization schemes as random effects within linear models predicting Bleu scores, reinforcing the orthogonal predictive power of R\'enyi efficiency alongside these schemes.
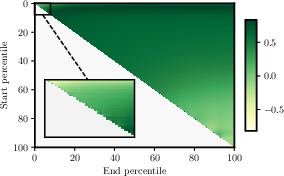
Figure 4: Results for grid search over the best hyperparameters for percentile frequency predictor.
Conclusion
The paper introduces a novel approach to evaluating tokenization using information theory, leveraging R\'enyi efficiency to reconcile token frequency distributions with downstream model performance. It demonstrates practical benefits by simplifying intrinsic tokenization evaluation and theoretically by bridging compression and learnability principles in NLP. The findings advocate for a reevaluation of standard tokenization practices, proposing that nuanced entropy measures such as R\'enyi can significantly enhance model performance predictions. The comprehensive analysis and robust empirical evidence provided make a compelling case for the adoption of R\'enyi-based metrics in refining NLP pipelines.

