- The paper introduces a novel multi-modal framework that combines pre-trained visual and audio encoders with a frozen LLM for comprehensive video understanding.
- It employs specialized Video and Audio Q-formers to capture temporal dynamics and enable zero-shot audio comprehension using diverse caption datasets.
- Experimental evaluations demonstrate the model’s superior ability to analyze complex video scenarios by effectively merging visual cues with auditory signals.
Video-LLaMA: An Instruction-tuned Audio-Visual LLM for Video Understanding
Introduction
Video-LLaMA is designed to extend the capabilities of LLMs by enabling them to comprehend both visual and auditory inputs within video data. This research introduces a novel multi-modal framework, leveraging pre-trained visual and audio encoders alongside a frozen LLM to achieve robust video understanding. Two major challenges are addressed: effectively capturing temporal changes in visual scenes and integrating multi-modal audio-visual signals. The model introduces a Video Q-former and an Audio Q-former to specifically tackle these challenges, assembling them into a cohesive audio-visual architecture.
Model Architecture
Video-LLaMA relies on distinct branches for processing vision and audio data, each designed to align with the embedding space of LLMs.
Vision-Language Branch: This component employs a pre-trained image encoder that processes individual frames of a video to extract features, enhanced with temporal position embeddings to reflect sequential information. The video Q-former aggregates these features into a format that LLMs can process, adapting frame-level representations into coherent video queries for textual output.
Audio-Language Branch: Utilizing ImageBind as the audio encoder, this branch processes auditory inputs by converting audio into spectrograms and subsequently into dense embeddings. An Audio Q-former integrates temporal cues, generating fixed-length embeddings that align with LLM embeddings. This design facilitates a comprehensive interpretation of audiovisual content.
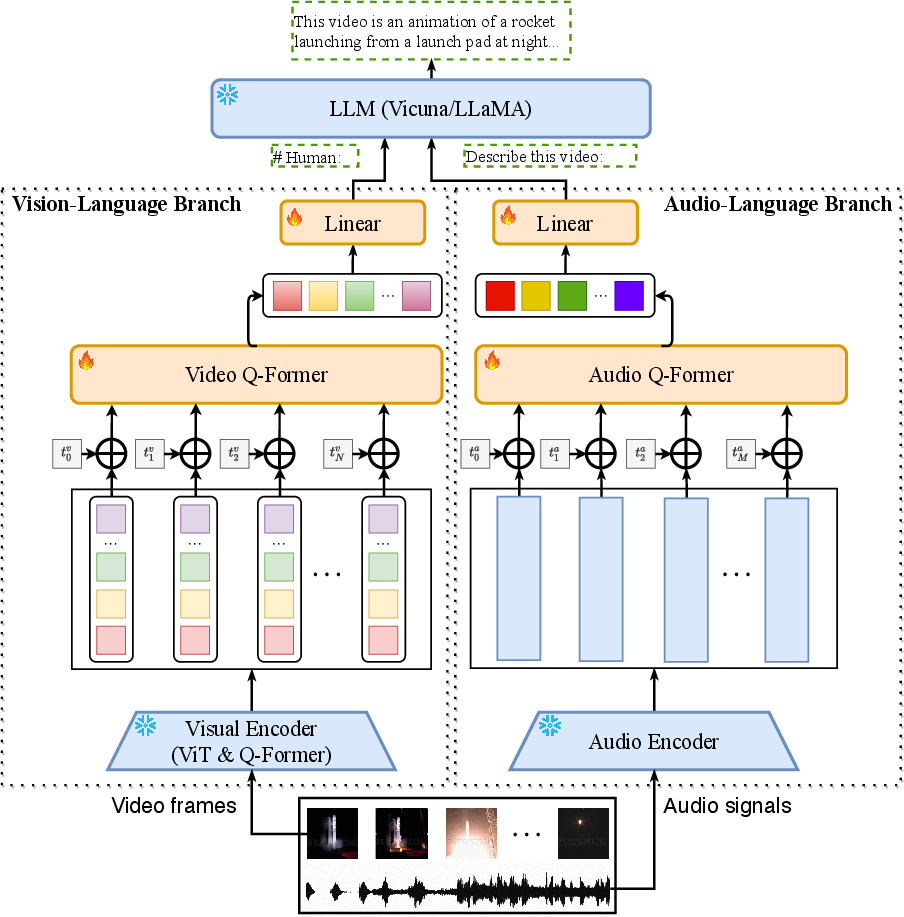
Figure 1: Overall architecture of Video-LLaMA.
Training Methodology
The training process for Video-LLaMA is bifurcated into separate pathways for vision and audio components.
Vision-Language Training: Initiated with extensive video caption datasets like Webvid-2M and complemented with image captions, the pre-training phase focuses on video-to-text generation tasks to build foundational vision-language alignment. Fine-tuning employs high-quality instruction data sets to enhance task-specific performance, ensuring the model accurately follows instructions in multi-modal contexts.
Audio-Language Training: The scarcity of audio-text datasets led to a novel strategy where audio components leverage visual-text data training, capitalizing on ImageBind's multi-modal alignment abilities. This enables zero-shot audio comprehension, empowering the model to generate coherent textual outputs from audio inputs using information learned from visual data relationships.
Experimental Evaluation
Video-LLaMA demonstrates comprehensive multi-modal understanding, notably distinguishing itself through its ability to process combined audio-visual data, surpassing models that focus exclusively on single-modal inputs. Qualitative examples illustrate the model's proficiency in identifying distinct actions, auditory cues, and complex visual dynamics within video content.


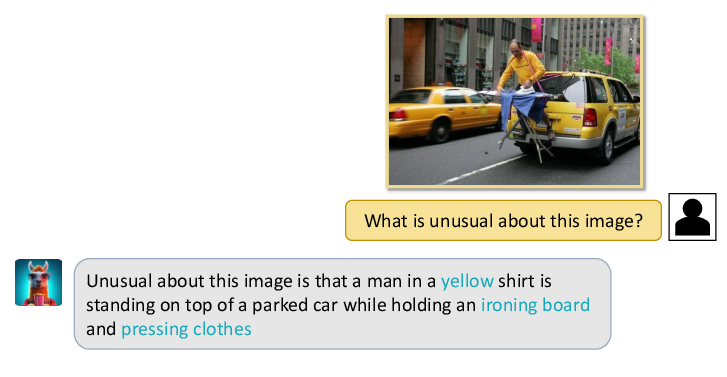

Figure 2: Some examples generated by Video-LLaMA.
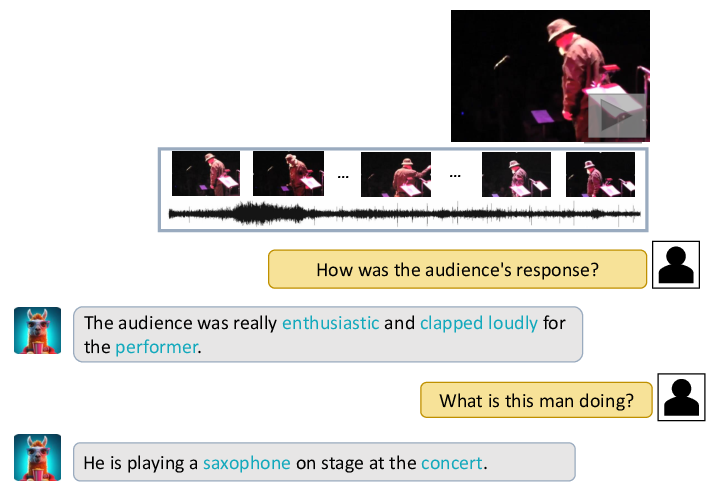
Figure 3: A case showing Video-LLaMA's ability to identify the sound of applause in a video and infer the positive response from the audience. Additionally, it infers that a man is playing the saxophone on stage based on the visual content.
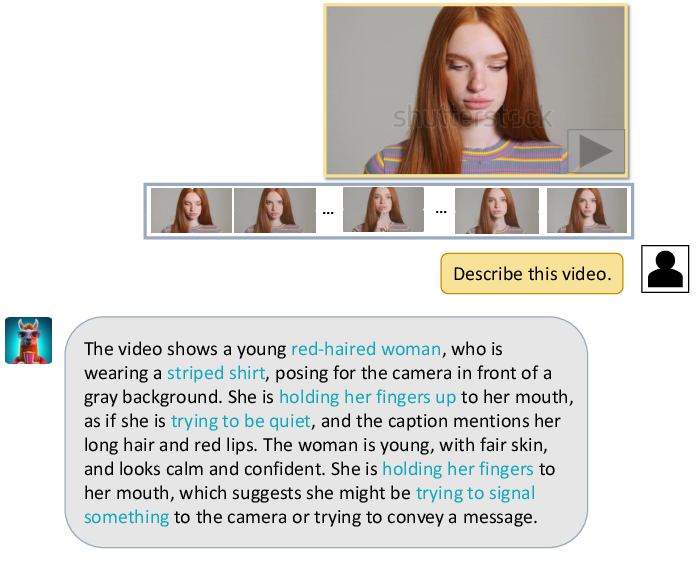
Figure 4: A case where Video-LLaMA provides a detailed description of the visual content in a dynamic video.
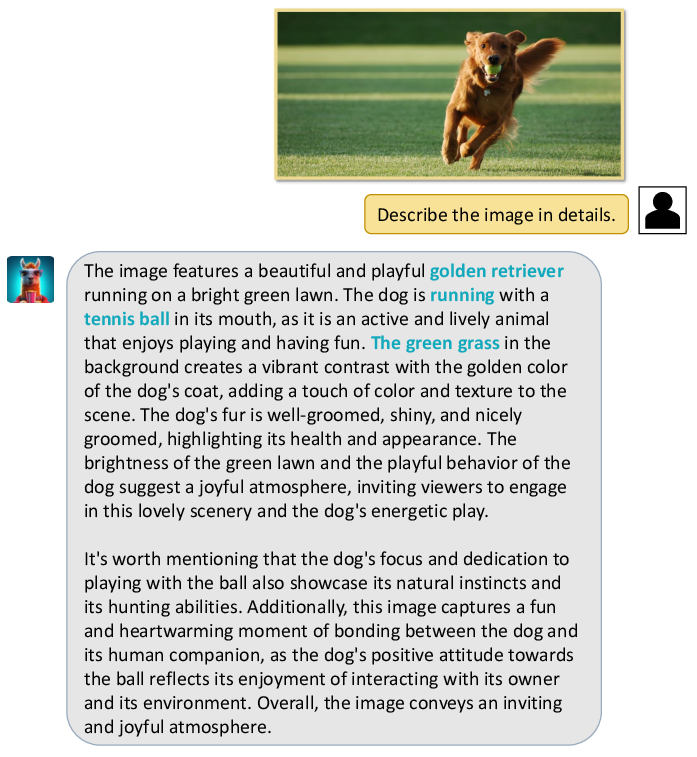
Figure 5: A case where Video-LLaMA provides a detailed description of the static image content.
Conclusion
Video-LLaMA introduces a sophisticated framework that expands LLM capabilities into multi-modal domains, effectively addressing the integration of visual and auditory data in video contexts. The architecture leverages pre-existing encoders and novel query transformers to achieve comprehensive video understanding. This research signifies a step forward in multi-modal LLM development, presenting a model that holds significant potential for audio-visual AI applications.
Future Directions
Anticipated directions for further work include enhancing dataset availability and diversifying multi-modal training to improve model robustness. Addressing the limitations related to scale and computational efficiency in long video processing will be critical for extending Video-LLaMA's practical applicability. Additionally, resolving hallucination issues inherent to LLMs remains a priority to ensure greater accuracy in generated outputs.

