- The paper introduces WAVE, a novel model that unifies text, audio, and video representations using multimodal LLMs and contrastive learning.
- It employs a hierarchical feature-fusion approach and dual-encoder design to generate context-aware embeddings for enhanced video-to-audio and text retrieval.
- Experimental results demonstrate state-of-the-art performance, indicating promising applications in VR, location-based services, and AI-driven interactions.
"WAVE: Learning Unified & Versatile Audio-Visual Embeddings with Multimodal LLM" Overview
This essay provides an authoritative summary of the research paper titled "WAVE: Learning Unified & Versatile Audio-Visual Embeddings with Multimodal LLM" (2509.21990). The paper introduces WAVE, a novel approach utilizing multimodal LLMs (MLLM) to create unified representations across text, audio, and video modalities. It promises enhancements in cross-modal retrieval and prompt-aware embedding generation, alongside being the first to set impressive performance benchmarks across various retrieval tasks.
Multimodal Embedding Challenges
Existing methods in multimodal embedding typically employ separate modalities aligned in a shared space. While effective, these approaches often struggle with more dynamic modalities like audio and video, focusing mainly on static images. They do not fully explore the possibilities offered by advanced MLLMs in effectively handling these dynamic data types. By integrating all modalities within a single MLLM, WAVE aims to overcome these limitations, improving on performance in tasks such as video-to-audio retrieval and multimodal question answering.
Architectural Innovations of WAVE
The WAVE model employs a hierarchical feature-fusion strategy and dual-encoder setup tailored for audio processing. It is designed to enhance semantic alignment across modalities, enabling coherent and context-aware multimodal representations.
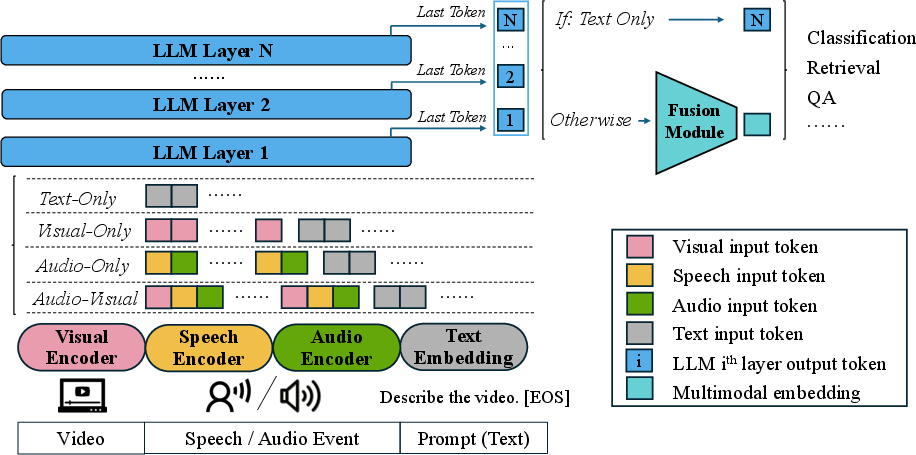
Figure 1: The model processes input through distinct encoders for non-text modalities, achieving unified embeddings via hierarchical feature fusion.
Distinct non-text modality encoders are employed. The visual encoder processes video frames into tokens, while audio is handled by a dual-encoder comprising a speech encoder and a general audio encoder to comprehensively capture different sounds. Multimodal inputs finish with token concatenation and feature-fusion within the LLM to derive unified embeddings.
Training Strategy
The training leverages contrastive learning to align various modality representations within a unified space, with a focus on both retrieval tasks and question answering (QA). The multimodal embeddings are optimized through a two-part strategy of retrieval and QA tasks. These tasks ensure that the model can understand and process inputs from diverse modalities while preserving the semantic alignment essential for effective retrieval and QA.
Experimental Results
The model demonstrates state-of-the-art performance in several benchmark tasks. In video-specific evaluations, WAVE significantly outperforms other models in tasks like video-to-text retrieval on the MMEB-v2 dataset. In the audio domain, it achieves superior results in audio and video-audio retrieval, benefiting greatly from its dual-encoder setup.
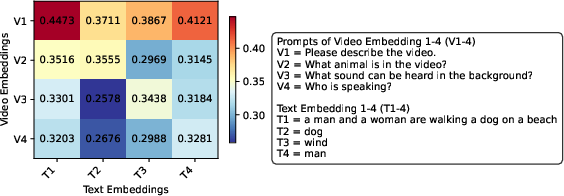
Figure 2: Heatmap of cosine similarity between video and text embeddings, demonstrating WAVE's adaptability to different textual prompts.
The case study visualized in Figure 2 highlights WAVE's ability to generate prompt-aware embeddings, dynamically adjusting its focus based on user queries to produce nuanced and contextually appropriate outputs.
Implications and Future Prospects
The implications of WAVE's approach suggest significant advancements in cross-modal retrieval and semantic understanding applications, thanks to its robust training strategy that fuses different modalities. The unified embedding approach promises to facilitate advancements in mixed-modality applications such as VR experiences, location-based services, and sophisticated AI-driven interaction systems.
Conclusion
The introduction of WAVE highlights a significant stride in utilizing MLLMs for versatile, cross-modal embedding generation. With its robust architecture and promising results, WAVE sets a new standard for future research on MLLM-based representation learning, potentially inspiring innovations in developing highly integrated AI systems that effectively bridge gaps across disparate data modalities.