- The paper demonstrates that LLMs exhibit human-like analogical reasoning with a moderate 53% success rate on controlled tasks, despite occasional reliance on flawed premises.
- The paper finds that LLMs struggle with spatial reasoning without visual context, achieving only 55% accuracy on structured text entailment challenges.
- The paper shows that LLMs provide nuanced moral reasoning responses in ethical dilemmas, though their subjective assessments require cautious interpretation.
Exploring Domain-Agnostic Reasoning Skills of LLMs
The paper "Are LLMs the Master of All Trades? : Exploring Domain-Agnostic Reasoning Skills of LLMs" (arXiv ID: (2303.12810)) investigates the multifaceted reasoning abilities of LLMs. It focuses on analogical, spatial, and moral reasoning, examining whether LLMs can emulate human-like reasoning across these distinct domains. This essay explores the methodology, experiments, findings, and implications presented in the paper.
Introduction to Reasoning Domains
Understanding reasoning capabilities across diverse domains is pivotal since reasoning underpins cognitive tasks such as problem-solving and decision-making. Humans employ different reasoning styles, including analogical, spatial, causal, and moral reasoning. This study specifically evaluates analogical reasoning by leveraging existing datasets (e.g., BATS) and exploring spatial reasoning inspired by data from SpartQA. Moral reasoning is assessed through open-ended questions exploring ethical dilemmas, providing a qualitative analysis.
Experimental Setup
Analogical Reasoning
For analogical reasoning, the study uses GPT-3 (davinci-003) on the BATS dataset and ChatGPT for conversational prompts. Tasks involve both controlled datasets, with cloze-style queries, and free-form questions designed to assess the models' qualitative capabilities. Despite achieving a fairly moderate success rate of 53% exact match on the controlled dataset, GPT-3 displays a proficiency in constructing analogies for complex explanations, although it sometimes persists with incorrect statements to maintain coherence.
Spatial Reasoning
Spatial reasoning is evaluated through a structured text entailment task derived from SpartQA and a simulated house layout challenge. GPT-3's performance on structured tasks achieved a 55% accuracy, indicating limitations due to the model's lack of multimodal training. A conversational challenge required the model to visualize a house layout from a text description and reason about spatial queries. While it successfully drew a reasonable model layout, its performance faltered on complex multi-step spatial reasoning.

Figure 1: Visualization of Controlled Dataset Example.
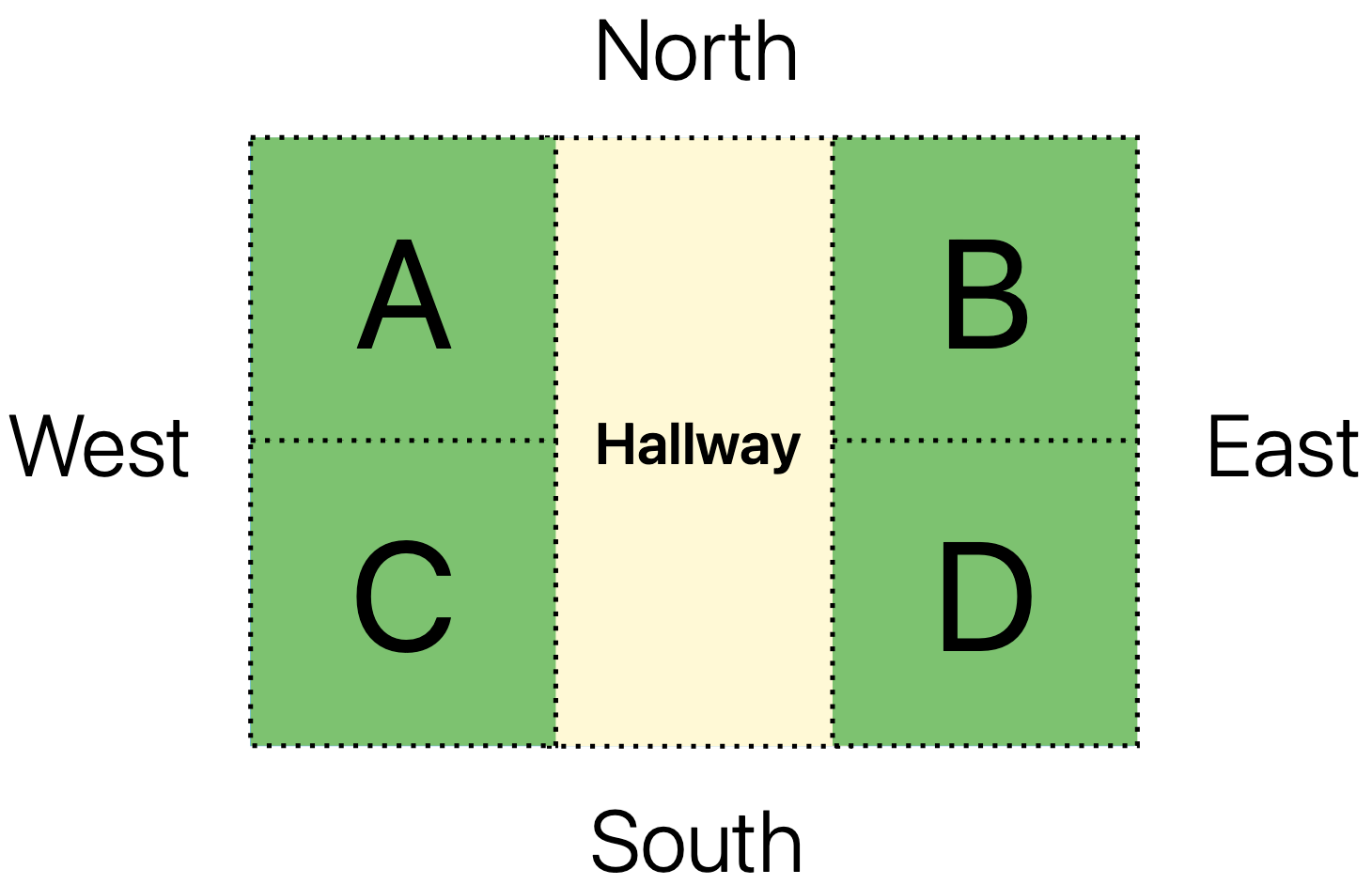
Figure 2: Visualization of the layout of house described via textual description.
Ethical and Moral Reasoning
The study of moral reasoning leverages open-ended scenarios posed to ChatGPT to gauge its responses to ethical dilemmas. While results indicated impressive handling of nuanced situations, the inherently subjective nature of moral reasoning suggests that evaluations are subject to reader interpretation. This setup highlights the difficulty of quantifiable assessments for moral reasoning, differing from the more concrete measures in analogical and spatial assessments.
Experimental Results and Analysis
Insights from Analogical Reasoning
LLMs showcase competence in analogy-based reasoning tasks but can fail when contextual clarification or explicit choices are absent. Conversely, their ability to construct analogies in conversational tasks aligns with human-like reasoning, albeit with occasional adherence to false premises.
Spatial Reasoning Challenges
The spatial reasoning experiments reaffirm the importance of visual data incorporation. GPT-3's limited improvement over chance level in structured tasks suggests text-based reasoning constraints for spatial tasks, whereas ChatGPT's conversational prowess highlighted the need for direct contextual inferences, proving insufficient for tasks requiring generalized spatial understanding.

Figure 3: Visualization of the layout of house as imagined by ChatGPT.
Moral Reasoning in Complex Scenarios
In moral reasoning scenarios, ChatGPT demonstrated adaptability and deep understanding in its responses, contributing valuable insights into AI applications in scenarios requiring ethical discernment. However, the subjective judgement involved in moral reasoning demands cautious interpretation of AI-generated responses.
Conclusion
The evaluation of reasoning skills across analogical, spatial, and moral domains underscores the multifaceted potential and limitations of LLMs. While performing reasonably well on analogical tasks, these models struggle on spatial reasoning without visual context and provide credible but subjective moral reasoning. The study calls for integrating multimodal data to enhance spatial reasoning and refining LLMs' contextual discernment capabilities. These findings further inform the development and deployment of LLMs in diverse application areas, urging continued exploration to bridge current capabilities with nuanced human-like reasoning.