- The paper presents Independent Contrastive RL (ICRL), reframing multi-agent tasks as goal-reaching problems to simplify reward specification.
- It employs contrastive representation learning for both actor and critic networks, enabling agents to overcome sparse rewards and develop emergent cooperative strategies.
- Empirical evaluations show ICRL outperforming traditional methods in scalability, exploration, and robustness across various multi-agent environments.
Self-Supervised Goal-Reaching in Multi-Agent Cooperation and Exploration
The paper introduces a goal-conditioned multi-agent reinforcement learning (MARL) paradigm, reframing cooperative tasks as goal-reaching problems rather than reward maximization. Instead of designing dense or shaped reward functions, the user specifies a single goal state, and agents are trained to maximize the likelihood of reaching that state. This approach leverages self-supervised learning, specifically contrastive representation learning, to address the challenge of sparse feedback in multi-agent environments. The method is particularly relevant for tasks where reward engineering is infeasible or undesirable, and where emergent cooperation and exploration are critical.
Methodology: Independent Contrastive RL (ICRL)
The proposed algorithm, Independent Contrastive RL (ICRL), builds on the IPPO framework by treating each agent as an independent learner with shared parameters. The core innovation is the use of contrastive representation learning to train both the actor and critic:
- Critic: The Q-function is parameterized as the exponential of the negative Euclidean distance between learned state-action and goal embeddings. The symmetric InfoNCE loss is used to train these embeddings, with positive samples drawn from the same agent's future trajectory and negatives from other agents.
- Actor: The policy is trained to select actions that minimize the distance between the current state-action embedding and the goal embedding, effectively maximizing the probability of reaching the goal state.
This approach does not require explicit exploration bonuses, intrinsic motivation, or hierarchical decomposition into subgoals. The reward is defined as the probability of reaching the goal at the next timestep, which generalizes to continuous state spaces.
Empirical Evaluation
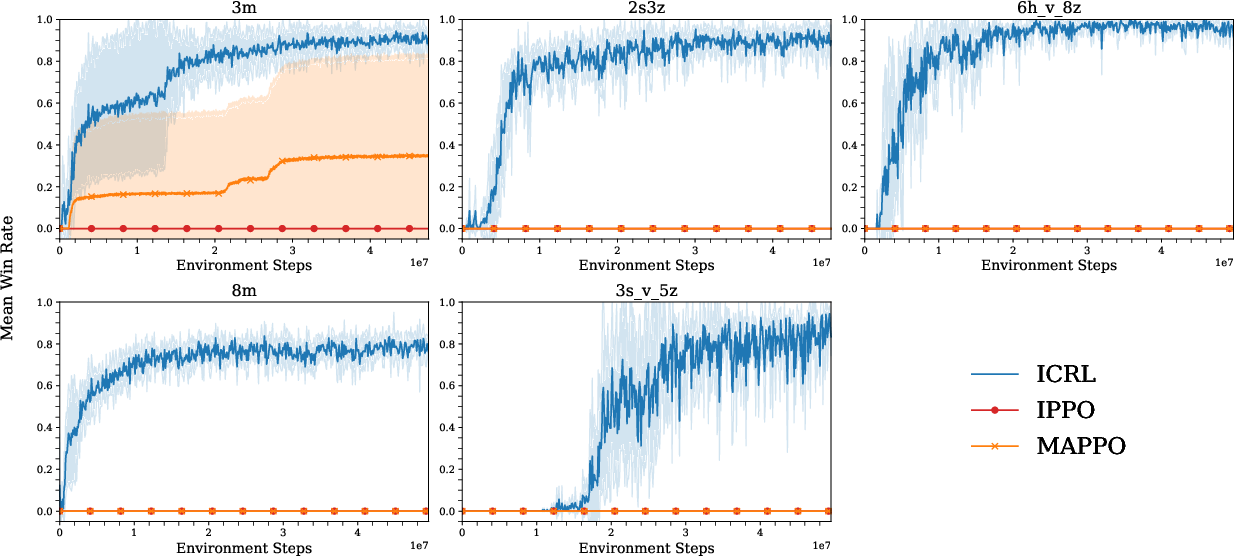
ICRL is evaluated on several standard MARL environments, including MPE Tag, StarCraft Multi-Agent Challenge (SMAX), and multi-agent continuous control tasks (e.g., Ant in Multi-Agent BRAX). All baselines (IPPO, MAPPO, MASER) are provided with identical sparse reward signals for fair comparison.
Exploration and Emergent Cooperation
Despite the absence of explicit exploration mechanisms, ICRL exhibits emergent exploration and coordination. Visualization of agent behaviors over training reveals the development of advanced strategies such as kiting, focus-fire, and flocking, even before any successful episodes are observed.
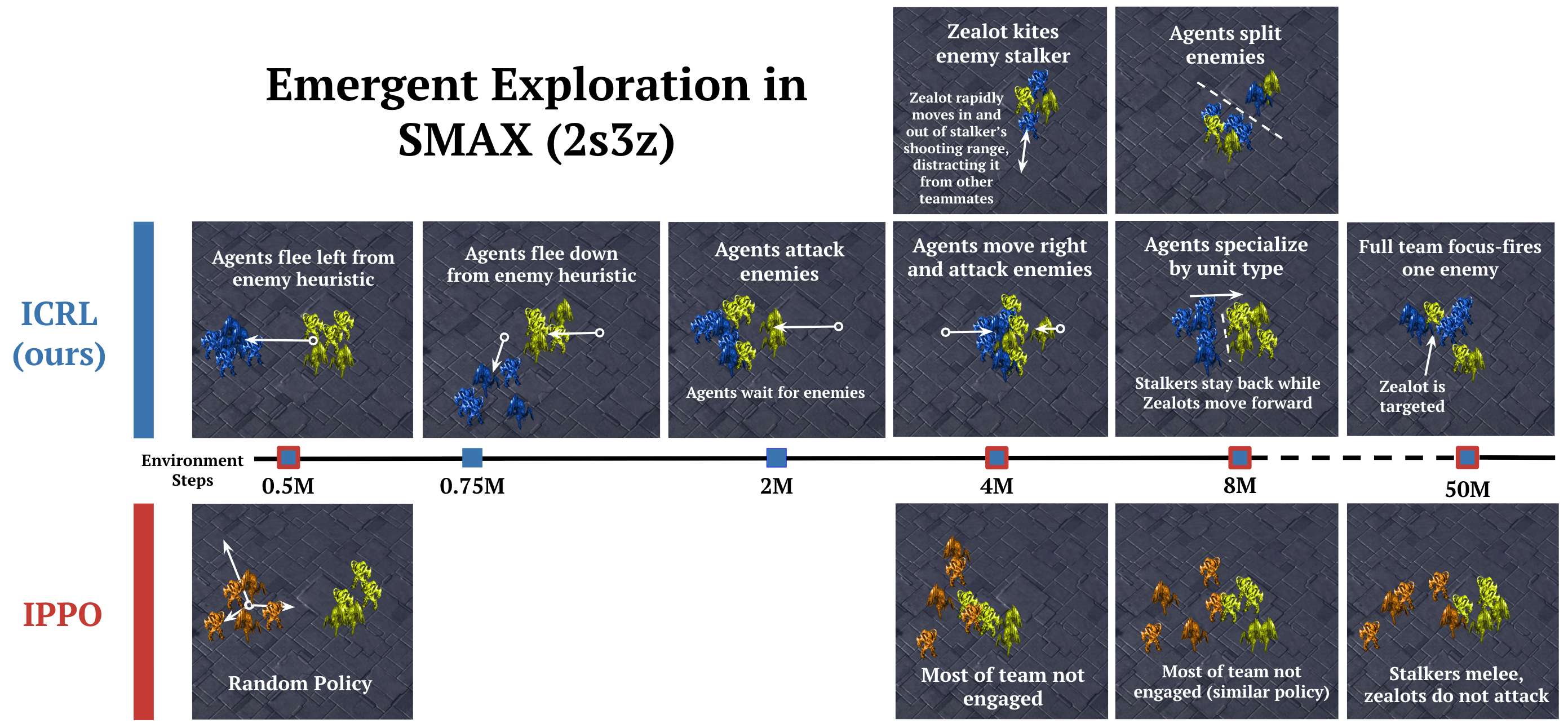
Figure 2: ICRL explores diverse coordination strategies in SMAX (2s3z), with agents developing increasingly sophisticated behaviors over 50 million training steps.
Specialization and Role Differentiation
Ablation studies show that agents learn to specialize based on unit type information, and performance degrades as this information is removed. The distribution of teammate types is more critical than self-type, indicating that the policy network leverages global team composition for coordination.
Comparison to Hierarchical and Intrinsic Motivation Methods
ICRL outperforms MASER, a state-of-the-art hierarchical MARL algorithm designed for sparse rewards, both in sample efficiency and asymptotic performance. This result challenges the necessity of hierarchical decomposition and intrinsic motivation for long-horizon sparse-reward tasks.
Robustness to Goal Specification
Experiments demonstrate that ICRL is robust to the choice of goal-mapping function $m_g$. Even when the goal is specified as the full observation vector (rather than a task-relevant subset), ICRL maintains or improves performance, suggesting that the method can generalize across different goal representations.
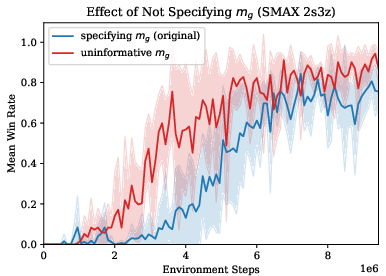
Figure 3: Specifying $m_g$ is not necessary for good performance; ICRL remains effective with uninformative goal mappings.
Continuous Control and Multi-Agent Factorization
On continuous control tasks (e.g., Ant), ICRL achieves high success rates, while IPPO fails to make progress due to the challenge of exploration under sparse rewards. Interestingly, factorizing control among multiple agents (each controlling a subset of joints) can accelerate learning compared to single-agent approaches, trading off faster convergence for potentially lower asymptotic performance.
Theoretical and Practical Implications
The results demonstrate that self-supervised goal-reaching is a tractable and effective approach for multi-agent cooperation under sparse feedback. The use of contrastive representation learning enables directed exploration and emergent coordination without explicit exploration bonuses or hierarchical structure. The independence assumption in policy learning can reduce the hypothesis space, improving sample efficiency in certain settings.
From a practical perspective, this framework simplifies task specification, requiring only a single goal state rather than complex reward engineering. The method is robust to goal representation and scales to large numbers of agents and heterogeneous team compositions.
Limitations and Future Directions
While the goal-reaching formulation simplifies task specification, it may not be straightforward to express all tasks as goal states. The choice of goal space and mapping can influence learning dynamics, and further theoretical analysis is needed to explain the observed emergent exploration. Future work should investigate the generalization of these findings to broader classes of multi-agent tasks, the integration of explicit communication protocols, and the development of theoretical guarantees for exploration and cooperation.
Conclusion
The paper provides strong empirical evidence that self-supervised goal-reaching via contrastive representation learning enables efficient multi-agent cooperation and exploration in sparse-reward environments. The approach outperforms existing baselines and hierarchical methods, exhibits emergent specialization and exploration, and is robust to goal specification. These findings suggest that goal-conditioned MARL is a promising direction for scalable, user-friendly multi-agent learning, with significant implications for both theory and real-world deployment.