Sub-word Level Lip Reading With Visual Attention
Abstract: The goal of this paper is to learn strong lip reading models that can recognise speech in silent videos. Most prior works deal with the open-set visual speech recognition problem by adapting existing automatic speech recognition techniques on top of trivially pooled visual features. Instead, in this paper we focus on the unique challenges encountered in lip reading and propose tailored solutions. To this end, we make the following contributions: (1) we propose an attention-based pooling mechanism to aggregate visual speech representations; (2) we use sub-word units for lip reading for the first time and show that this allows us to better model the ambiguities of the task; (3) we propose a model for Visual Speech Detection (VSD), trained on top of the lip reading network. Following the above, we obtain state-of-the-art results on the challenging LRS2 and LRS3 benchmarks when training on public datasets, and even surpass models trained on large-scale industrial datasets by using an order of magnitude less data. Our best model achieves 22.6% word error rate on the LRS2 dataset, a performance unprecedented for lip reading models, significantly reducing the performance gap between lip reading and automatic speech recognition. Moreover, on the AVA-ActiveSpeaker benchmark, our VSD model surpasses all visual-only baselines and even outperforms several recent audio-visual methods.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper builds a smarter computer system that can “read lips,” meaning it turns silent videos of people talking into written text. The authors improve how the system looks at the mouth area, how it turns mouth movements into words, and how it figures out when someone is speaking—using only the video. Their goal is to make lip reading more accurate and less dependent on huge amounts of training data.
What questions the researchers asked
- How can we design a lip-reading model that is tailored to video (not just copied from audio speech systems)?
- Can we help the model “look” at the right parts of the face in each frame, instead of averaging everything?
- Instead of predicting one character at a time, can we predict slightly bigger chunks of words (sub-words) to make reading lip movements easier and faster?
- Can we detect when someone is speaking just from video (no sound), so we know which parts of a clip to transcribe?
How they did it (in simple terms)
Think of the system like a very focused viewer and a smart reader working together:
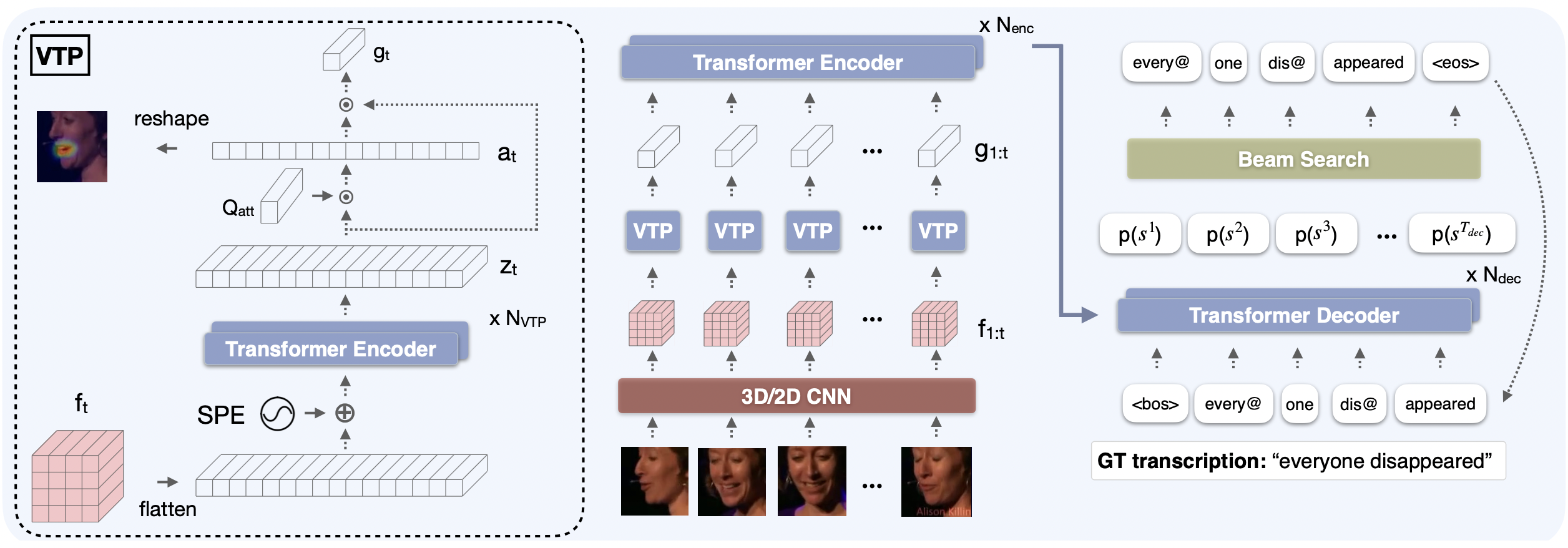
- A “spotlight” for the face (attention-based pooling):
- In each video frame, there’s a lot to look at—lips, cheeks, jaw, and more.
- The model uses an attention mechanism (like a learnable spotlight) to automatically focus on the most important areas for understanding speech, frame by frame. This helps it “track” the mouth movements even if the person turns their head.
- Reading in chunks (sub-words/word-pieces):
- Instead of predicting text letter-by-letter (which can be slow and confusing when letters look similar on lips), the model predicts sub-words—small pieces of words like “play-” and “-ing.”
- This shortens the output sequence, speeds up training and inference, and gives the model helpful hints about language (since sub-words carry meaning and patterns).
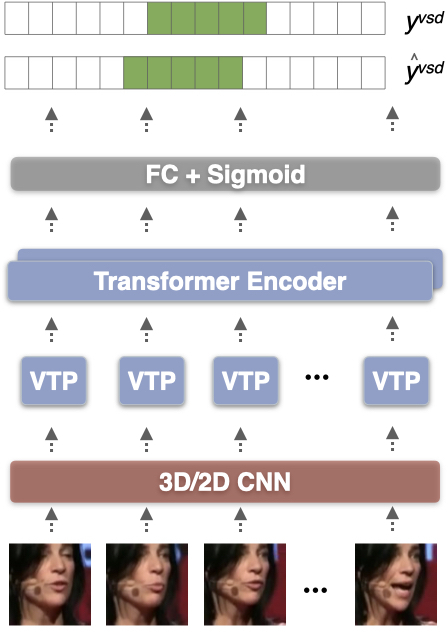
- A video-only speech detector:
- They add a simple head on top of the lip-reading encoder to decide frame by frame if the person is speaking.
- This is like a video version of “voice activity detection” but without audio.
- Training approach:
- Stage 1: Train on short two-word clips to learn the basics.
- Stage 2: Freeze the visual part, then train the language part on longer chunks. This is a simpler, more efficient version of older training curriculums.
- Datasets and evaluation:
- LRS2 and LRS3 are large public datasets of people speaking on TV shows and TED/TEDx talks.
- They measure accuracy using Word Error Rate (WER): the percentage of words that are wrong (lower is better).
- For detecting speaking in video, they use a benchmark called AVA-ActiveSpeaker and measure mean Average Precision (mAP): higher is better.
What they found and why it matters
- Much better accuracy with less data:
- On LRS2, their best model achieved a 22.6% WER—unusually low for lip reading and better than all previous models trained on public data.
- On LRS3, they also reached strong results.
- Importantly, they outperformed some industry models that were trained on about 10 times more data. That means their design is data-efficient.
- The new “spotlight” helps a lot:
- Replacing simple “average everything” pooling with attention-based pooling significantly reduced errors. The model learns to focus on the mouth and other useful areas.
- Sub-word tokens make lip reading easier:
- Switching from characters to sub-words improved accuracy and sped up the model by making the output shorter and more meaningful.
- Strong video-only speech detection:
- Their Visual Speech Detection model (video-only) beat all prior visual-only baselines on AVA-ActiveSpeaker and even outperformed several recent methods that used both audio and video. That’s impressive for silent video analysis.
Why this matters:
- Better lip-reading models can help in noisy places (where microphones struggle), enable silent dictation, and assist people who cannot speak but can move their lips.
- Strong video-only speech detection can automatically find speaking moments in silent films or videos without sound.
What this could lead to (impact and implications)
- Practical tools:
- Transcribing old silent movies and documentaries.
- Assisting people with speech impairments by turning lip movements into text.
- Improving speech recognition in loud environments by combining audio with visual cues.
- More robust AI:
- The attention mechanism for focusing on the right visual areas can be useful in other video tasks.
- Sub-word prediction can be applied more broadly in language tasks to balance speed and accuracy.
- Responsible use:
- The authors note potential privacy concerns (e.g., surveillance). They point out that real-world conditions like low resolution, odd angles, and low frame rates make “secret” lip reading from far-away cameras very unreliable.
- They plan to share code and models to support research and transparency.
Quick guide to key terms
- Attention (visual attention): A way for the model to focus on the most important parts of an image, like shining a spotlight on the lips.
- Sub-words (word-pieces): Small, meaningful chunks of words that help the model predict text more efficiently than single letters.
- Word Error Rate (WER): How many words were wrong in the transcription; lower means better.
- Visual Speech Detection (VSD): Finding when someone is speaking using only the video, no sound.
- Transformer: A modern type of neural network that’s good at understanding sequences (like text or frames over time).
Collections
Sign up for free to add this paper to one or more collections.