- The paper introduces a novel perceptual lip-reading loss that improves lip synchronization in 3D avatar animations.
- It employs an encoder-decoder transformer network with FLAME and 3D Gaussian models for photorealistic, interactive rendering.
- Experimental results show a 56.1% improvement in lip vertex error and 65% user preference for realism over baseline methods.
Perceptual Lip Synthesis for 3D Avatars
The paper "VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis" (2507.06060) introduces \acs{NAME}, a novel method for generating realistic 3D facial animations with a focus on accurate lip synchronization. \acs{NAME} leverages differentiable photorealistic rendering and visual speech recognition to improve the perceptual quality of 3D avatar animations, addressing limitations of prior geometry-driven methods. The paper's core contribution lies in the introduction of a perceptual lip-reading loss, which guides the training process by evaluating the lip-readability of rendered avatar videos using a pre-trained visual automatic speech recognition (\ac{vasr}) model.
Methodology and Implementation
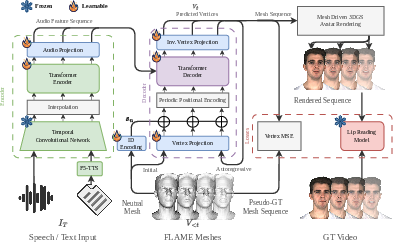
Figure 1: System overview illustrating the encoder-decoder framework, perceptual loss, and the use of a pretrained lip-reading model.
\acs{NAME} combines a parametric 3D face model, \ac{3dgs}, and visual speech recognition to enhance lip-synchronized facial animation. The process begins with the FLAME head model, a parametric 3D face model that uses identity (β∈R300), expression (ψ∈R100), and pose (θ∈R6) parameters to represent head geometry. \ac{3dgs} is then employed to generate photorealistic 3D head avatars using 3D Gaussian primitives, enabling differentiable, high-fidelity rendering at interactive rates.
The architecture is based on an encoder-decoder transformer network, inspired by Faceformer, that generates 3D facial animations from audio or text input. The encoder processes the input modality and produces feature embeddings aligned with the video frame rate, using Wav2Vec2.0 for audio or F5-TTS for text. The decoder autoregressively predicts vertex offsets to deform a neutral FLAME mesh.
A key innovation is the perceptual supervision module, which uses a pre-trained AutoAVSR model to extract visual speech features from rendered lip regions, optimizing for lip readability in the pixel space.
The training process follows a three-stage curriculum: geometric pretraining on VOCASET, adaptation to MEAD with adjusted vertex weighting, and fine-tuning with the novel lip-reading loss. The total loss function is a weighted sum of the geometric and perceptual losses:
L=Lvert+λreadLread
where λread=1e−5.
Experimental Results and Analysis
The method was evaluated on the VOCASET and MEAD datasets. Geometric accuracy was measured using the lip vertex error (\ac{lve}) metric, while visual fidelity was assessed using PSNR, SSIM, and LPIPS. Results showed that \acs{NAME} achieves a 56.1% improvement in \ac{lve} on the MEAD dataset compared to a baseline without the lip-reading loss. Visual metrics remained competitive, indicating that the perceptual supervision did not degrade overall image quality. A user study further confirmed that \acs{NAME} produces more realistic and intelligible lip movements compared to the baseline.
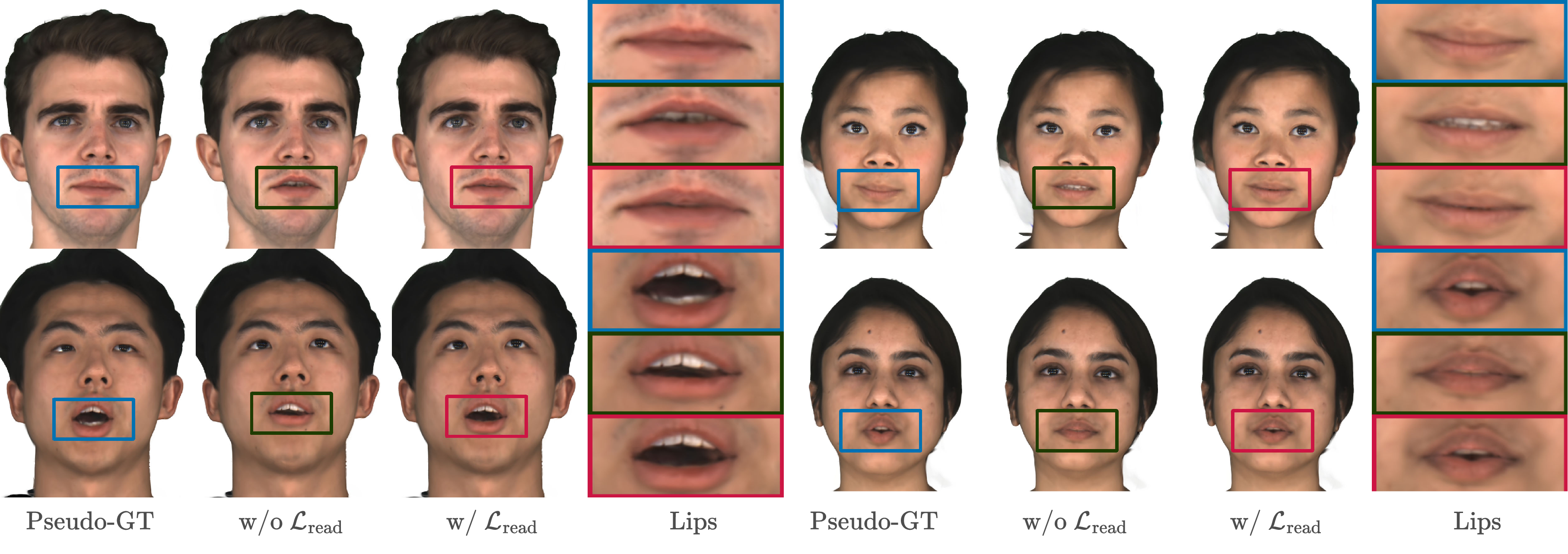
Figure 2: Qualitative comparison of lip articulation with and without the lip-reading loss, demonstrating improved lip shape and expressiveness.
Qualitative results demonstrate improved mouth closures and more expressive lip motions (Figure 2). The authors conducted a user study, and the results indicate that 65% of participants preferred the animations generated by \acs{NAME} in terms of both realism and lip clarity. The paper further demonstrates the method's applicability to sign language production (\ac{slp}), where accurate mouthings are crucial for disambiguating manual signs.
Implications and Future Directions




Figure 3: The figure contrasts traditional vertex-based optimization with the proposed method's lip-reading perceptual loss.
The research has significant implications for the creation of realistic and accessible 3D avatars. By directly optimizing for lip readability, \acs{NAME} addresses a critical gap in existing methods, particularly for applications like \ac{slp} where mouth movements convey linguistic information. The perceptual lip-reading loss, computed directly on photorealistic \ac{3dgs} renders, closes the loop between geometric generation and perceptual evaluation. The framework enables direct text-to-mouthing synthesis.
Despite the contributions, the paper acknowledges several limitations. The computational cost of differentiable \ac{3dgs} training is high, and the method relies on per-subject multi-view avatars. Future work could focus on adapting the loss to more generalizable or few-shot avatar pipelines, as well as incorporating explicit control of emotion and upper-face cues. Further research should investigate more efficient renderers.
Conclusion
\acs{NAME} represents a significant advancement in the field of speech-driven 3D facial animation by integrating perceptual supervision directly into the training process. The results highlight the importance of optimizing for visual intelligibility in creating realistic and accessible 3D avatars, with potential applications in sign language translation and human-computer interaction.