- The paper introduces an energy-efficient FPGA design that integrates a simplified Leaky Integrate-and-Fire neuron model with spike-time dependent plasticity.
- The methodology employs an event-driven update mechanism to reduce computational complexity and achieve real-time classification in 0.5 ms per image.
- The results demonstrate optimized FPGA resource usage and low power consumption, making the approach ideal for embedded and robotic applications.
FPGA Implementation of Simplified Spiking Neural Network
The paper "FPGA Implementation of Simplified Spiking Neural Network" discusses the development and deployment of a computationally efficient architecture for spiking neural networks (SNN) using field-programmable gate array (FPGA) technology. It focuses on advancing energy-efficient, real-time learning systems applicable to robotics and embedded applications, by optimizing the Leaky Integrate-and-Fire (LIF) neuron model combined with spike-time dependent plasticity (STDP) learning.
Introduction and Motivation
SNNs are recognized for their biologically plausible approach to modeling neural activity, making them effective for real-time systems requiring temporal information encoding. Conventional neural networks are often too memory-intensive and computationally demanding for these applications, highlighting the need for efficient alternatives. FPGA offers an advantageous solution due to its parallelism capability and reduced power consumption compared to other architectures like GPUs, making it a suitable medium for implementing SNNs targeted at real-time and portable applications.
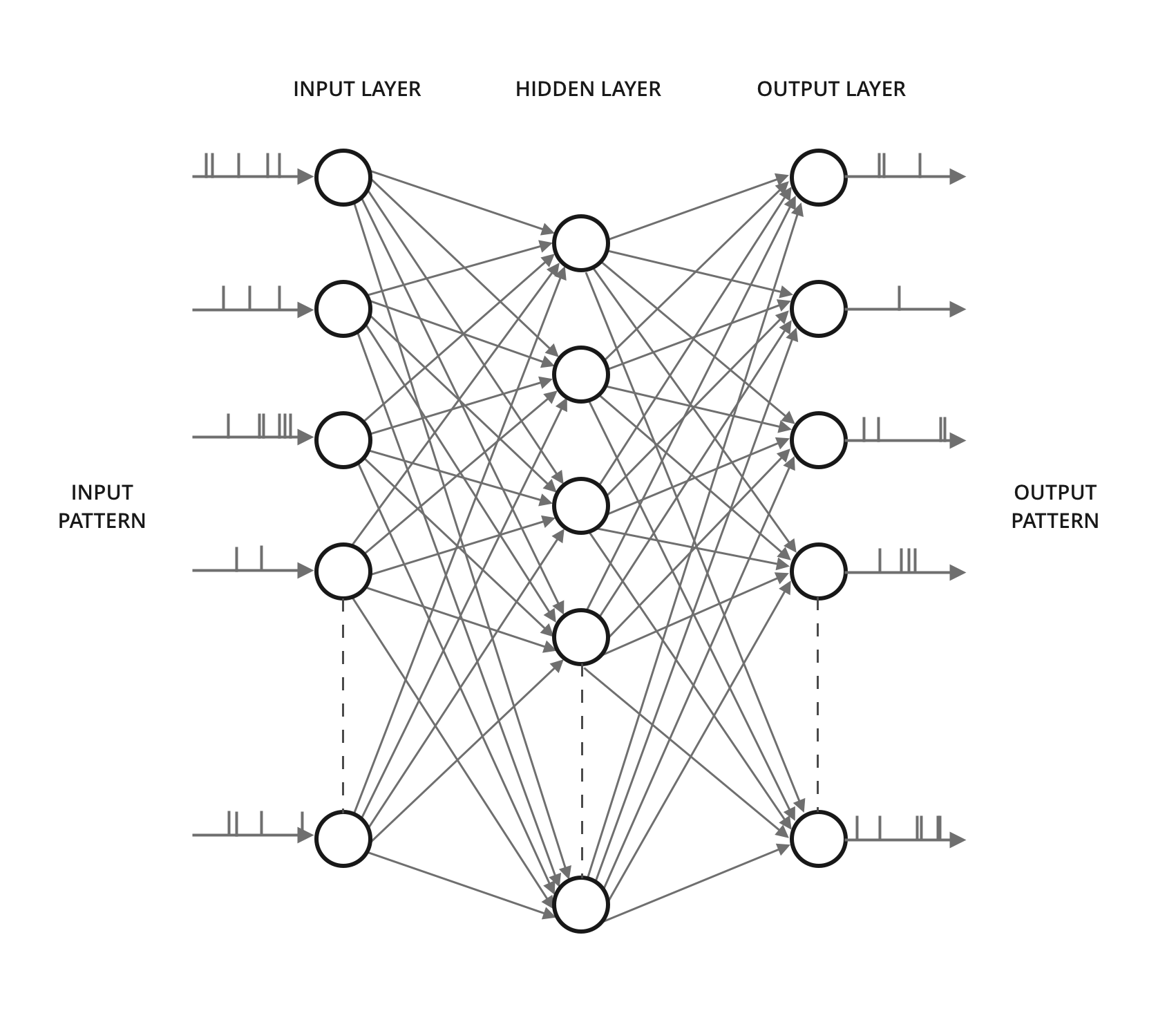
Figure 1: Full Mesh Spiking Neural Network.
Architecture Overview
The proposed architecture implements a simplified single neuron model and a fully connected network with 800 neurons and 12,544 synapses. It utilizes reduced computational complexity equations for membrane potential updates and adapts an event-driven mechanism that only updates neurons with spiking activities. This event-driven approach improves energy efficiency and scales down resource usage. Key elements of the architecture include receptive fields for feature mapping, spike rate calculations inherently related to input excitation, and dynamic thresholding to ensure uniform neural output.
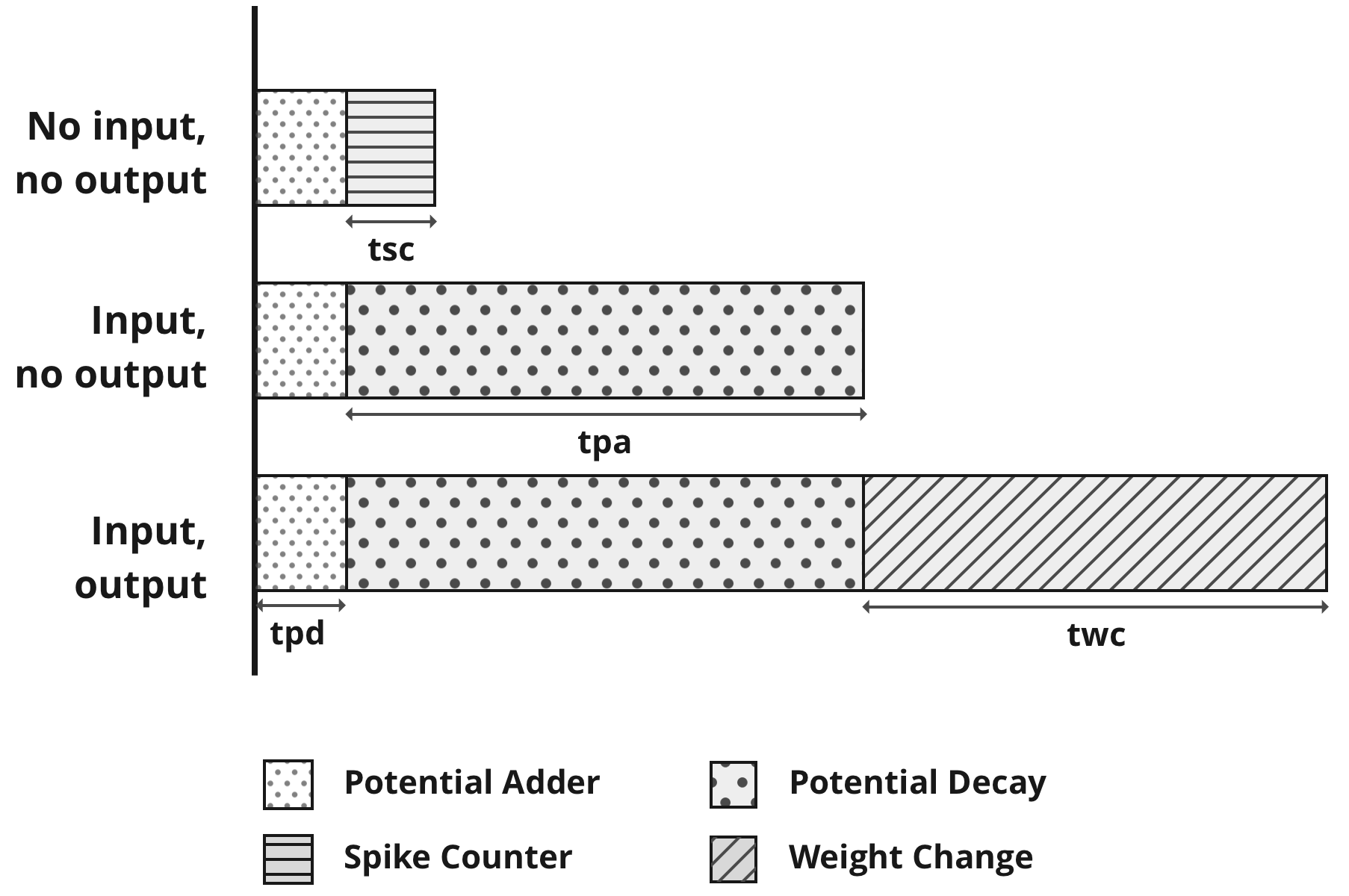
Figure 2: Breakdown of a Time Unit into processes under different scenarios.
Spike-Time Dependent Plasticity
STDP plays a crucial role in SNNs by adjusting synaptic strengths based on temporal differences between pre- and post-synaptic spikes. This unsupervised learning mechanism is efficiently incorporated, supporting a flexible floating-point representation for synaptic weights which enhances the architecture's adaptive capacity.
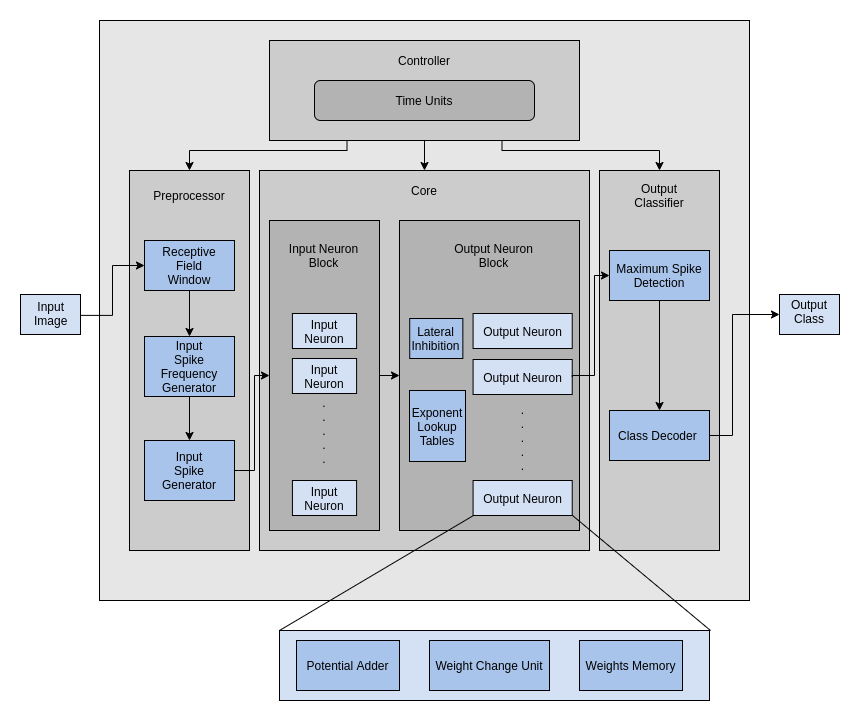
Figure 3: Block Level view of the system.
Implementation and Results
The implementation leverages FPGA to parallelize computations effectively, achieving significant resource savings. The network utilizes 24-bit representation for both membrane potentials and synaptic weights. The system demonstrated superior timing and speed capabilities, achieving a classification time of 0.5 ms per image, considerably faster than equivalent CPU implementations.
Timing Analysis and Resource Utilization
Timing analysis revealed that dynamic adjustment of Time Units effectively utilizes computational resources varying with neuron spiking activities, resulting in real-time processing improvements. Resource usage is optimized, with low utilization percentages across different FPGA resources, indicating efficient handling of neuron and synapse scaling.
Conclusion
The architecture advances the efficient FPGA-based implementation of SNNs suitable for low-power embedded applications with real-time learning capabilities. By simplifying the STDP algorithm and optimizing computational complexity, the proposed model reduces FPGA resource usage without compromising learning and classification performance. The application of this architecture is notable for its reduced time resolution and energy efficiency compared to other large-scale SNN implementations, making it an ideal choice for embedded applications requiring real-time computation.