Mastering Sequences with Structured SSMs
This presentation explores the architecture and impact of Structured State-Space Models (SSMs), a class of neural models that leverage dynamical systems theory to process sequences with extreme efficiency and long-range memory. We cover their mathematical roots, structural innovations like diagonal and PD-SSMs, and their performance across domains like NLP and vision.Script
How can a machine remember the beginning of a book while reading the final chapter without slowing to a crawl? Structured State-Space Models or SSMs utilize the mathematics of dynamical systems to solve the fundamental trade-off between memory and speed.
Building on classical physics, SSMs represent sequences through a latent state that evolves over time. They generalize linear systems for deep learning, transforming input sequences into outputs through successive matrix transformations.
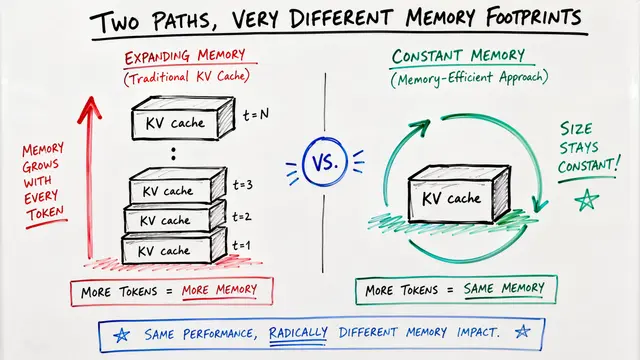
To make these models fast, researchers restrict the internal state matrix to specific shapes. These structural choices, like diagonal or permutation-diagonal forms, allow for efficient parallel computation without sacrificing the ability to track complex tasks.
By using the HiPPO framework, models like S4 can compress an entire history into a fixed-size state. This method uses mathematical bases like Legendre polynomials to ensure the model maintains an inductive bias for long-term memory.
Transitioning from theory to practice, we see how these models achieve near-linear scaling.
While fixed SSMs use fast Fourier transforms for convolution, selective models like Mamba introduce input-dependent gating. This allows the model to decide what to remember or forget based on the current data, achieved through efficient parallel scans.
A key theoretical breakthrough found that certain SSMs are actually equivalent to a form of masked attention. This duality means we can enjoy the power of Transformers with the speed of linear-time recurrences.
The results speak for themselves, with models like Mamba and Jamba matching Transformers while staying much faster. Beyond text, SSMs lead the way in signal processing and vision, even reaching 1.17% word error rate on speech tasks.
Engineering these models involves ensuring stability through specialized frameworks like L2RU. However, they can be sensitive to data poisoning where specific outliers distort their learning bias, necessitating robust sanitization.
Structured State-Space Models are redefining the limits of sequence modeling by blending classical dynamics with modern neural scaling. Visit EmergentMind.com to learn more.