SIA: Self-Improving AI with Harness & Weight Updates
This presentation introduces SIA, a breakthrough framework that unifies two previously separate approaches to AI self-improvement: harness iteration (modifying the infrastructure around a model) and weight updates (adapting the model itself through reinforcement learning). By enabling a Feedback-Agent to dynamically choose between these two improvement levers, SIA achieves compounded performance gains that neither approach can reach alone, demonstrated across legal reasoning, code optimization, and biological data denoising tasks.Script
Every AI system hits a wall: you can tinker with the code around the model, or you can retrain the model itself, but doing both at once in a coordinated feedback loop has been out of reach. The authors of SIA solved this by letting an AI decide when to improve its own infrastructure and when to update its weights, unlocking gains neither strategy achieves alone.
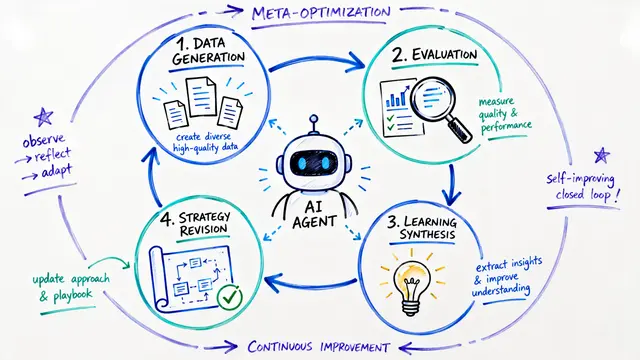
SIA coordinates three agents: a Meta-Agent that drafts the initial scaffold, a Task-Specific Agent that executes tasks, and a Feedback-Agent that watches performance trajectories and chooses whether to refine the harness or trigger a weight update. This dynamic selection happens at runtime, reacting to plateaus and reward signals rather than following a fixed schedule.
Across legal reasoning, CUDA kernel optimization, and biological denoising, the pattern is consistent: harness updates alone plateau, but when weight updates join the loop, performance jumps. On LawBench, accuracy rose from 50 percent with harness-only to 70 percent with both levers active, and the CUDA task saw a 14 times speedup that harness iteration couldn't touch.
Harness updates deliver infrastructure wins: better parsing, smarter retry logic, new tools. Weight updates internalize domain knowledge that no amount of scaffold tweaking can encode. The Feedback-Agent picks the right reinforcement learning algorithm on the fly, matching the task's reward landscape instead of running a one-size-fits-all procedure.
The coupling of two optimizers introduces a stability question that standard analyses miss: the system settles into an equilibrium shaped by both levers, and that fixed point could be fragile under distributional shifts. The Feedback-Agent's selection policy itself is static, which limits how recursive this self-improvement can become.
SIA proves that self-improving AI needs both levers working together, not in isolation. Future work could make the system learn its own alternating schedule, enabling true recursive improvement. To explore this research further and create your own video summaries, visit EmergentMind.com.