Autodata: Teaching AI Agents to Generate Their Own Training Data
This presentation introduces Autodata, a groundbreaking framework that transforms synthetic data generation by treating it as an agentic, iterative data science process. Instead of relying on static prompts or simple filtering, Autodata deploys AI agents that generate training data, evaluate its quality through weak-versus-strong solver discrimination, learn from failures, and continuously refine their strategy. The framework demonstrates consistent empirical gains across computer science research questions, legal reasoning, and mathematical problem-solving, while introducing meta-optimization that improves the data scientist agent itself.Script
Training modern language models requires massive datasets, but what if the AI could generate its own training data and iteratively improve it like a skilled data scientist? That's exactly what Autodata does, turning synthetic data creation from a one-shot prompting task into a cyclical process of generation, evaluation, learning, and refinement.
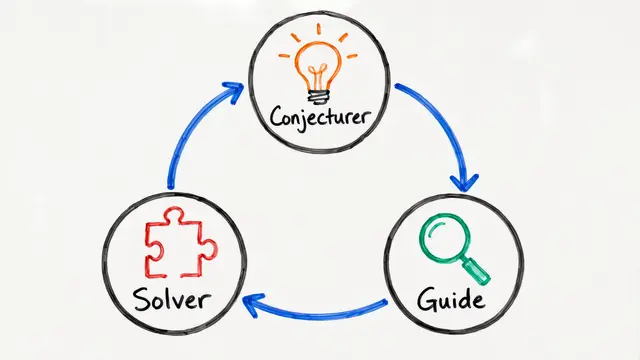
The researchers designed Autodata around a fundamental insight: good training data should discriminate between weak and strong solvers. An orchestrator agent coordinates four specialized sub-agents. The challenger generates candidate tasks, weak and strong solvers attempt them, and a judge evaluates everything. The system keeps only examples where the strong solver succeeds but the weak one fails, ensuring each training item teaches something meaningful.
Across computer science research tasks, Agentic Self-Instruct outperformed standard prompting on every metric. The strong solver's rubric score jumped from 0.696 to 0.772, while the weak solver dropped from 0.677 to 0.458. That gap expansion from 0.019 to 0.314 isn't just a number; it means the system learned to generate training data that actually teaches models new capabilities instead of rehearsing what they already know.
The advantage held across domains. In legal reasoning over court opinions, models trained on just 2,800 agentic examples outscored both baseline-trained models and even much larger strong baselines on the PRBench Legal benchmark. In mathematical reasoning, the agentic approach delivered a 3.2 percent average improvement while simultaneously reducing reasoning truncation from 23.75 percent to just 4.09 percent, making models both more accurate and more token-efficient.
But here's where it gets recursive: the data scientist agent itself can be optimized. The researchers applied meta-optimization to the agent's prompt and scaffolding, running 233 iterations of testing modifications and keeping only those that improved validation performance. The pass rate climbed from 62.1 to 79.6 percent as the system automatically learned to enforce paper-specific insights, prevent context leakage, and restructure evaluation rubrics.
Autodata reframes synthetic data creation as an iterative, feedback-driven science rather than a prompt engineering art. By explicitly targeting the gap between weak and strong solvers, the framework produces training data that scales with model capabilities instead of hitting diminishing returns. To explore how agentic workflows might transform your own data pipelines, visit EmergentMind.com where you can dive deeper into this research and create your own explanatory videos.