SemBench: Testing the Next Generation of Query Engines
This presentation explores SemBench, a pioneering benchmark designed to evaluate semantic query processing engines that combine traditional database operations with large language model reasoning. We examine how these systems handle complex multimodal queries across text, images, and audio, the trade-offs between cost and accuracy they face, and what the benchmark reveals about the current state and future potential of this emerging technology.Script
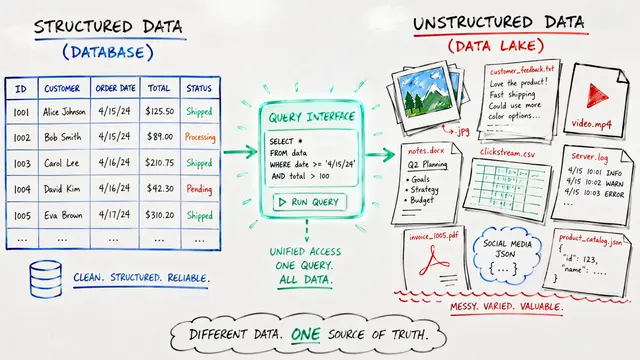
Traditional databases struggle when you ask them questions that require understanding, not just matching. Semantic query processing engines merge SQL with large language model reasoning to handle queries like 'find movie reviews expressing subtle disappointment' or 'match wildlife sounds to their visual habitats,' opening entirely new possibilities for data analysis.
The benchmark introduces five semantic operators that extend SQL with natural language instructions. Semantic filters sift data using nuanced criteria, semantic joins connect records by meaning rather than exact matches, and mapping, ranking, and classification operators transform and organize information in ways that traditional databases simply cannot.
Every semantic operator requires calls to large language models, creating a fundamental three-way tension. SemBench measures execution cost in API calls, processing latency, and result accuracy against manually labeled ground truth, exposing how different systems navigate this challenging optimization space.
The results reveal striking differences across evaluated systems. BigQuery delivers high accuracy but at substantial computational cost, while LOTUS achieves impressive cost efficiency through embedding-based approximations that sometimes sacrifice precision. Palimpzest maintains strong result quality but struggles with expense, demonstrating that no system yet masters both dimensions simultaneously.
Implementing these systems demands navigating thorny choices that traditional databases never face. Prompt engineering determines whether the model understands your intent, caching strategies balance memory against redundant computation, and the inherent randomness of language model outputs requires robust error handling. Most systems still struggle with multimodal data, revealing how early we are in this technology's evolution.
SemBench establishes the first comprehensive framework for evaluating semantic query engines, revealing both their transformative potential and current limitations. As these systems mature, the benchmark will continue tracking their progress, and you can explore how this technology might transform your own data challenges by visiting EmergentMind.com to create videos about the research shaping our AI-powered future.