Semantic Tube Prediction: Beating LLM Data Efficiency with JEPA
This presentation explores Semantic Tube Prediction (STP), a novel training strategy for large language models that challenges conventional data scaling laws. By introducing geometric inductive biases based on the Geodesic Hypothesis—that semantic trajectories follow locally linear paths in representation space—STP achieves equivalent model performance using only one-sixteenth the training data. The talk examines the theoretical foundation grounding STP in manifold geometry, the practical regularization mechanism that prevents mode collapse, and empirical evidence demonstrating robust improvements across architectures and domains, ultimately suggesting that power-law data requirements are not fundamental limits but artifacts of standard training objectives.Script
Language models are supposed to need exponentially more data as they scale. But what if that iron law is just an artifact of how we train them? This paper demonstrates a geometric regularization technique that matches baseline accuracy using one-sixteenth the training data.
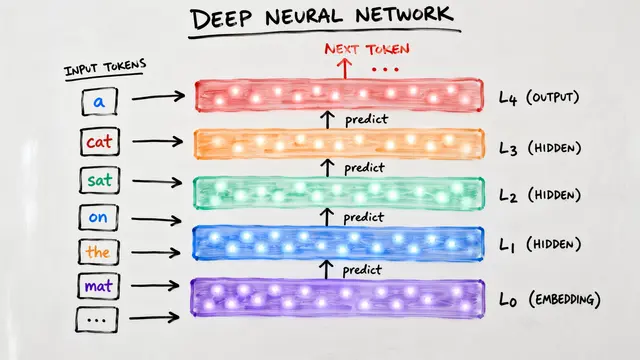
The authors propose that meaningful language generation isn't random wandering through representation space. Instead, correct sequences follow geodesics, the straightest possible paths on a curved semantic manifold, with valid hidden states confined to a narrow tube around these trajectories.
So how do you teach a model to stay inside the tube?
The Semantic Tube Prediction loss enforces local collinearity by penalizing the component of each hidden state increment that's perpendicular to the overall trajectory direction. It's a simple cosine term added to the standard cross-entropy objective, requiring almost no computational overhead.
The contrast is stark. Standard next token prediction alone allows trajectories to drift perpendicular to the semantic signal, leading to mode collapse and data-hungry scaling. STP constrains the geometry directly, maintaining accuracy even when you slash the training set by a factor of 16.
The technique isn't architecture-specific. It works across model families, scales robustly with parameter count, and crucially, it maintains the polymorphic richness of the representation space while preventing the accidental collisions that cause hallucinations.
Semantic Tube Prediction shows that data scaling laws aren't fundamental physics—they're consequences of flat objectives that ignore the geometry underneath. Visit EmergentMind.com to explore this paper further and create your own research video presentations.