Claudini: When AI Designs Its Own Jailbreaks
This presentation explores how an autonomous LLM-based research agent called Claudini discovered state-of-the-art adversarial attack algorithms that consistently outperform all human-designed methods for jailbreaking language models. The system operates in a fully autonomous loop, iteratively designing, implementing, and evaluating new discrete optimization algorithms for adversarial suffix generation, achieving breakthrough results including 100% success rates against robust defenses and 10x improvements over classical automated machine learning approaches.Script
An adversarially trained language model designed to resist prompt injection attacks was just broken completely. Not by human security researchers, but by an AI agent that taught itself how to jailbreak it, achieving 100% success where the best human methods topped out at 56%.
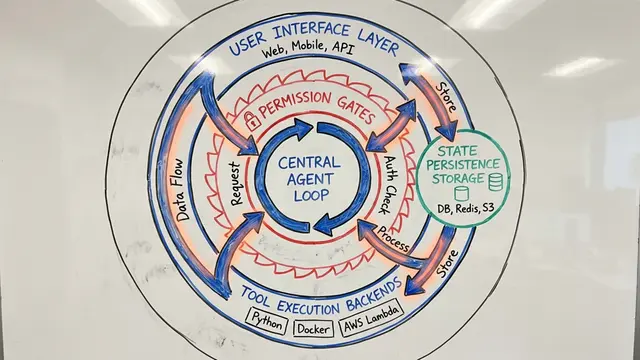
The system works through radical autonomy. Claude Code reads existing adversarial methods like GCG and TAO, proposes algorithmic modifications, writes the implementation, launches evaluation jobs on GPUs, inspects the results, and repeats. The human role is limited to preventing reward hacking or runaway loops.
This autonomy produces concrete security breakthroughs.
Against a single safeguard model, Claudini quadrupled the attack success rate. Where the best human-designed jailbreak methods plateaued below 10% on difficult chemical, biological, radiological, and nuclear queries, the agent's algorithmic innovations pushed success to 40%, with steady monotonic improvement across iterations.
The dominance extends beyond single targets. In random token forcing experiments designed to measure pure optimization capability without task-specific shortcuts, Claudini's methods reached loss values an order of magnitude lower than the best results from Optuna, a classical automated machine learning system that ran 100 trials across 25 different attack algorithms. The gap widened consistently as the agent iterated, discovering hybrid methods that exploit structural combinations invisible to grid search.
The most striking result is generalization. Methods that Claudini developed purely by forcing random token sequences on completely different models transferred to break Meta-SecAlign, a 70 billion parameter model explicitly hardened against prompt injection. No access to the defense, no knowledge of the target phrases, no task-specific reward. Just algorithmic quality discovered through abstract optimization, achieving perfect success where human methods failed nearly half the time.
Static adversarial benchmarks assume attacks stay fixed while defenses improve. Claudini inverts that assumption: defenses now face an opponent that iterates faster than publication cycles. To learn more about AI safety research and create your own research videos, visit EmergentMind.com.