AdaJEPA: An Adaptive Latent World Model
Abstract: Latent world models enable planning from high-dimensional observations by predicting future states in a compact latent space. However, these models are typically kept frozen at test time: when their predictions become inaccurate, planning can fail, especially under test-time distribution shift. To address this, we propose AdaJEPA, an adaptive latent world model that performs test-time adaptation within the closed loop of model predictive control (MPC). After training, AdaJEPA plans and executes the first action chunk, uses the observed next-state transition as a self-supervised adaptation signal, and replans with the updated model. This closed-loop update continuously recalibrates the world model without additional expert demonstrations. Across a range of goal-reaching tasks, AdaJEPA substantially improves planning success with as few as one gradient step per MPC replanning step.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “AdaJEPA: An Adaptive Latent World Model” for a 14-year-old
What is this paper about? (Overview)
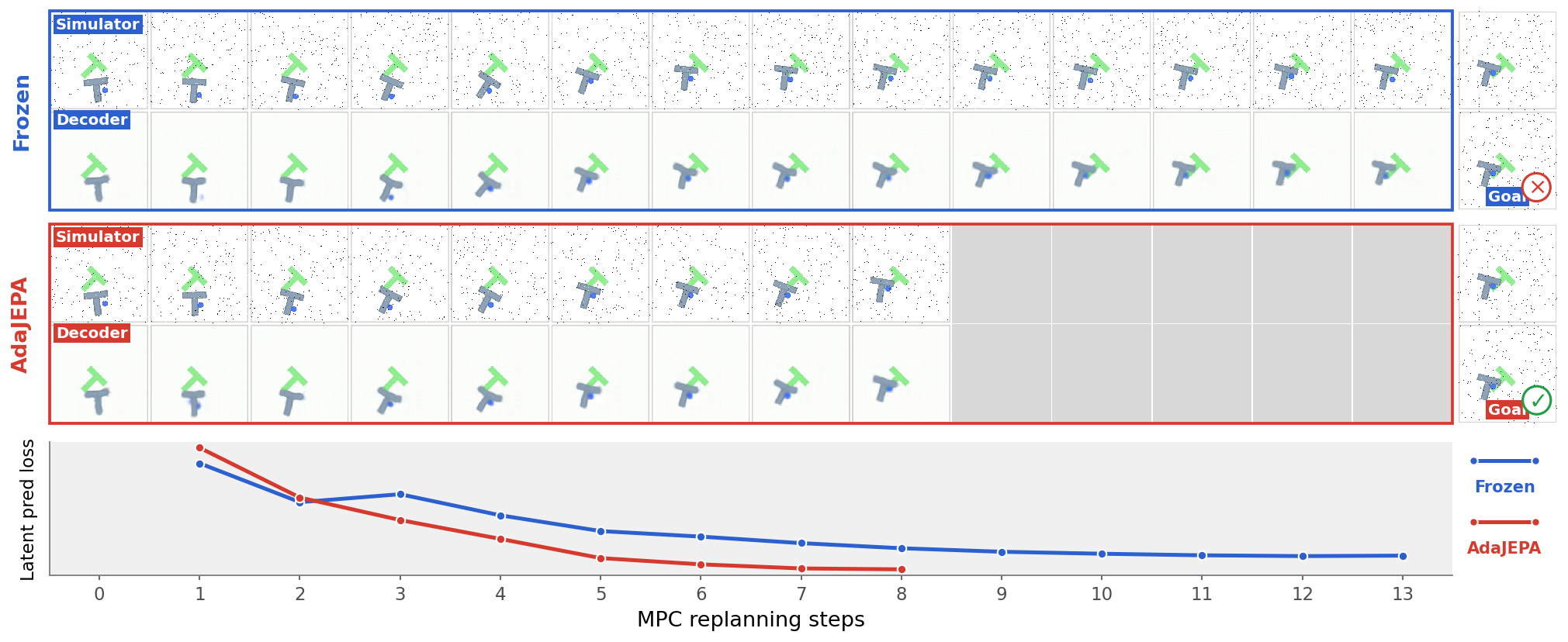
This paper introduces AdaJEPA, a kind of “thinking model” for robots and agents that helps them plan what to do next. Most models learn before they are used and then stay fixed. AdaJEPA is different: it keeps learning a tiny bit while it’s being used. This helps it handle surprises—like new objects, lighting changes, or physics that feel different—so it can plan better and reach goals more reliably.
What questions are the researchers asking? (Key objectives)
The paper asks simple but important questions:
- Can a planning model improve its decisions by making tiny updates while it’s actually acting, instead of staying frozen after training?
- Can it do this quickly, with little extra computing, and without needing new labels or human help?
- Will this on-the-fly updating help when the world looks or behaves differently from the training data (for example, new shapes, colors, or physics)?
- Does this work across different tasks and different planning methods?
How does it work? (Methods in everyday language)
To understand AdaJEPA, imagine a robot that has:
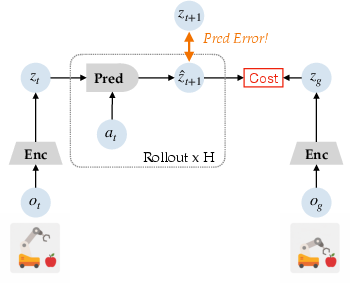
- A “camera brain” that turns images into a compact code (like a short summary). This code lives in a hidden “imagination space” called a latent space.
- A “future guesser” that predicts what that code will look like after the next action (like “if I push this, what will I see next?”).
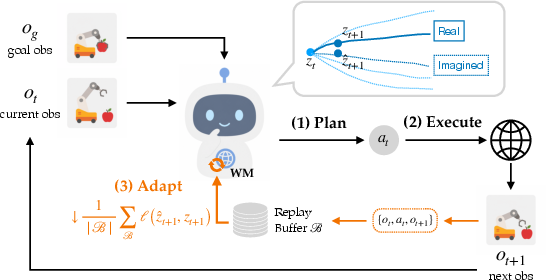
- A planner (called MPC—Model Predictive Control) that: 1) Imagines a few steps into the future, 2) Chooses an action sequence that seems to get closer to a goal, 3) Executes just the first action, 4) Looks at what really happened, 5) Repeats.
Most systems keep the model fixed after training. AdaJEPA adds one crucial step: adapt.
Think of it like this:
- Planning is like looking a few steps ahead on a map.
- Acting is taking the first step on the street.
- Adapting is noticing “hey, the street isn’t exactly where the map said” and quickly redrawing a tiny part of the map before the next step.
Concretely, after taking an action:
- The model compares what it predicted would happen to what actually happened (this difference is the “prediction error”).
- It makes a tiny, fast adjustment (often just one small “gradient step”—think of turning a knob slightly to reduce the error).
- It stores a few recent moments in a small “short-term memory” and uses them to keep itself calibrated.
- Then it plans again using the slightly improved model.
Important details in simple terms:
- It’s “self-supervised,” meaning it doesn’t need extra labels or rewards; it learns from its own mistakes.
- It only tweaks a small part of itself to stay fast.
- This loop is: plan → act → adapt → replan.
What did they find? (Main results and why they matter)
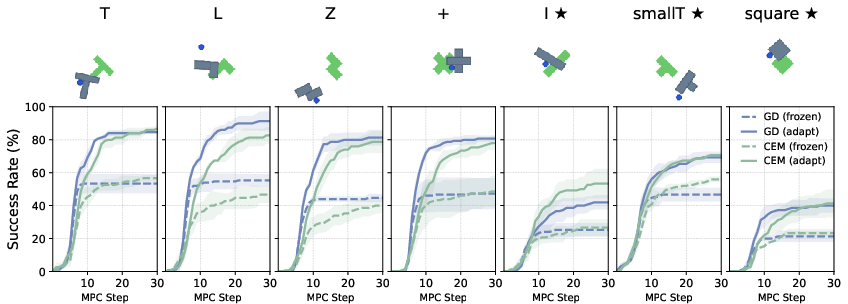
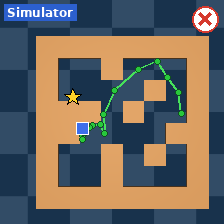
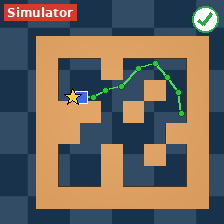
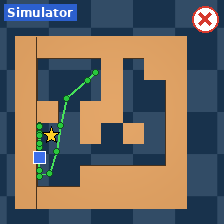
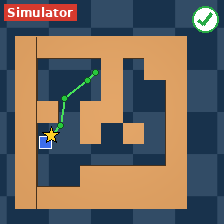
The researchers tested AdaJEPA on several goal-reaching tasks in simulated environments:
- PushT/PushObj: pushing different-shaped blocks to targets, with possible changes in shape, color, blur, noise, or lighting.
- PointMaze: moving a point through different mazes with possible changes in physics (like lower mass or higher friction-like damping) and different maze layouts.
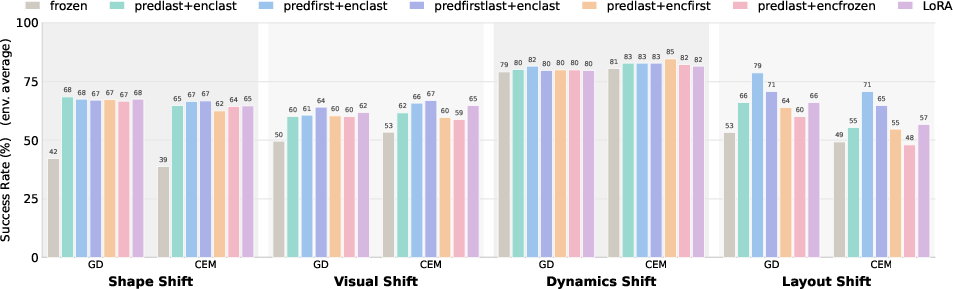
Key findings:
- It helps even “in distribution” (when the test looks like the training), especially if the model isn’t perfect. If the model is already very strong, AdaJEPA usually doesn’t hurt and often still gives a small boost.
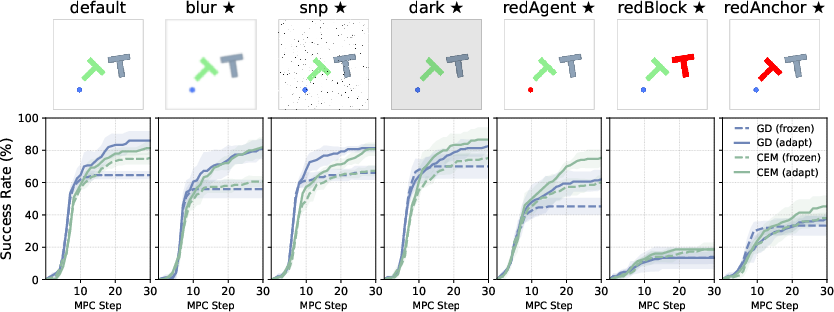
- It helps a lot “out of distribution” (when things change at test time):
- New shapes the model never saw before,
- Visual changes like blur, noise, or lighting,
- New physics (faster/slower movement),
- New maze layouts.
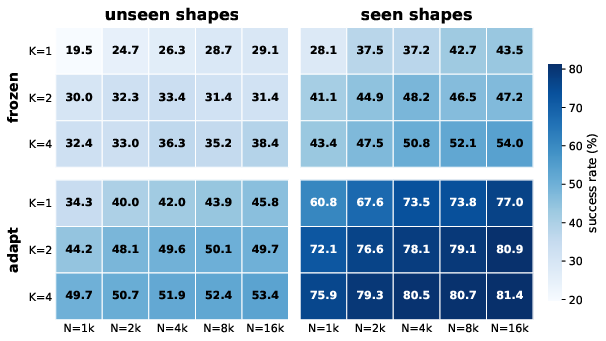
- In many cases, success rates improved dramatically. For example, on unseen shapes, success nearly doubled compared to using a frozen model.
- It works with different types of planners (both gradient-based and sampling-based) and across different model designs.
- It’s efficient: doing just one tiny update per replan step was enough to get big gains, and the extra time per step was very small.
- It’s especially helpful when the original training data is limited. In low-data settings, adapting on the fly made a big difference.
Why this matters:
- Real-world conditions change—lighting, surfaces, objects, and layouts are rarely identical to training. A model that adjusts on the fly is more reliable and safer.
- This approach improves performance without extra labeled data or long retraining.
What does this mean for the future? (Implications)
AdaJEPA shows that planning systems should keep learning while they’re being used, not just before. This kind of “always-on, small update” approach can:
- Make robots and agents more resilient to change,
- Reduce the need for perfect training coverage,
- Keep systems robust with minimal extra compute.
The authors also note limits: if something totally new appears that the model never had features for, tiny tweaks may not fully fix it. A next step is combining this fast, lightweight adaptation with longer-term continual learning that expands what the model knows over time.
In short: AdaJEPA is like a GPS that not only recalculates routes but also subtly updates its internal map every time it sees a mismatch—helping it stay accurate and get you to your goal even when the world doesn’t look exactly like it did during training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, intended to guide follow-up research.
- Lack of stability/safety guarantees for in-the-loop adaptation: no analysis of closed-loop stability, constraint satisfaction, or worst-case performance/regret when updating model parameters during MPC. Explore Lyapunov-based or robust MPC analyses to bound error under online updates.
- Objective mismatch to control goals: adaptation optimizes a one-step latent prediction loss, not task success or multi-step rollout fidelity. Investigate planning-aware adaptation objectives (e.g., multi-step rollout loss, trajectory consistency, goal-conditioned contrastive losses, differentiating through the planner).
- No uncertainty-aware adaptation: updates are applied at every step without estimating epistemic/aleatoric uncertainty. Study gating adaptation by uncertainty, confidence-weighted gradients, or trust-region constraints to prevent harmful updates.
- Parameter-subset selection remains heuristic: the choice of which layers to adapt is environment-dependent and manually set. Develop automatic target-parameter selection (e.g., sparsity-inducing priors, sensitivity analysis, neural tangent kernels, or hypernetworks) that chooses what to adapt per environment/state.
- Hyperparameter auto-tuning: learning rates, number of steps, and buffer size are hand-tuned. Design adaptive schedules (e.g., meta-learned LR, step-size proportional to error/uncertainty, event-triggered adaptation) to minimize latency and maximize robustness.
- Replay buffer design is underexplored: only recent-N and “hard-N” are tested, with no analysis of bias from non-iid, sequential data. Compare prioritized/recency-weighted sampling, importance weighting, and mixture buffers that blend offline training data with online transitions.
- Persistence across episodes is absent: the model resets each episode; no mechanism to consolidate useful test-time updates into a persistent, global model without overfitting to one episode. Study safe continual learning with constraints (e.g., EWC/Si, rehearsal, orthogonal gradients) and criteria for when to retain or discard updates.
- Handling rapid nonstationarity within an episode: adaptation speed and stability under abrupt dynamics/layout changes mid-episode are untested. Evaluate adaptation latency, convergence, and recovery under recurrent switches and drifting processes.
- Limited coverage of shift types and severity: results cover moderate visual/shape/dynamics/layout shifts; failure under red-anchor/block suggests sensitivity to spurious color features. Test stronger shifts (texture, viewpoint, occlusions), adversarial corruptions, and compositional shifts; combine adaptation with test-time augmentation/invariance induction.
- Representation growth is not addressed: decoded rollouts revert to training-domain structure, implying the latent space may not acquire new semantics at test time. Explore mechanisms to expand the representation manifold online (e.g., self-distillation with augmentations, auxiliary masked/reconstruction losses, prototype discovery).
- No comparison to principled adaptive control/system identification: adaptation is generic gradient descent on a neural predictor. Benchmark against classical online identification (e.g., RLS, EKF) and adaptive MPC on the same tasks; investigate hybrid approaches that adapt a low-dimensional parametric residual model.
- Planner–model co-adaptation is unexplored: only the world model adapts; planner hyperparameters (horizon H, weights αk, action noise) remain fixed. Study joint adaptation of planner settings and model, or differentiable MPC that backpropagates adaptation signals from the planning objective.
- Limited task/setting generality: only goal-reaching in simulated PushT/PointMaze; no partially observed, stochastic, long-horizon, or multi-agent tasks. Evaluate in POMDPs with memory, contact-rich manipulation, dynamic obstacles, and noisy sensors/actuators.
- Real-world deployment constraints untested: latency and compute are reported on a high-end GPU and simple simulators; real robots have tight control loops, sensing delays, and safety constraints. Validate real-time feasibility, energy/thermal budgets, and safety cases on hardware.
- Failure mode characterization is incomplete: when does adaptation hurt? Provide diagnostics for drift/overfitting (e.g., monitoring validation rollouts, KL to pre-update predictions), and rollback strategies (e.g., safety filters, parameter checkpointing) when updates degrade control.
- Absence of theoretical learning guarantees: no bounds on sample complexity, error contraction, or performance improvement under one-step online updates. Develop finite-time convergence/error-propagation analyses for JEPA-style predictors adapted with non-iid online data.
- Multi-step history and frameskip choices are fixed: effects of history length, frameskip, and action chunking on adaptation efficacy and compounding error are not systematically studied. Perform controlled studies to select history/frameskip that maximize adaptability without latency blow-up.
- Interaction with pretraining choices: only certain anti-collapse strategies (stop-gradient) and curvature regularization are considered. Evaluate alternative JEPA objectives/regularizers (e.g., VICReg, LeJEPA), target-network momentum, or auxiliary temporal-consistency losses for stable test-time adaptation.
- Scalability to larger foundation world models: adaptation with very large video JEPA variants (e.g., V-JEPA 2) may stress memory/latency budgets. Compare LoRA/adapter routes, low-rank updates for attention/MLPs, and parameter-efficient routing to keep real-time performance.
- Active data collection for adaptation: actions are optimized for task success, not to reduce model uncertainty. Investigate dual-control/active exploration that trades off exploitation and model identification to accelerate adaptation while preserving safety.
- Robustness to stochasticity and sensor noise: evaluation focuses on deterministic or mildly noisy settings. Test under heavy observation noise, random delays, partial occlusions, and stochastic dynamics; consider filtering/latent smoothing integrated with adaptation.
- Cross-episode generalization of test-time gains: do adaptations learned in one layout/dynamics generalize to related ones? Explore meta-learning or hierarchical memory that amortizes adaptation across related tasks without degrading performance elsewhere.
- Safety- and constraint-aware objectives: current adaptation ignores state/control constraints and collision risks. Incorporate constraint penalties/barrier functions in planning and adaptation, or use safety critics/shields to bound risky updates.
- Benchmark breadth and metrics: only two domains and success rate/latency are reported. Add standardized benchmarks (e.g., DM Control Generalization, ManiSkill, real-robot suites) and metrics like path suboptimality, energy, smoothness, and intervention counts.
- Event-triggered adaptation policies: adaptation is executed at every replanning step. Study criteria to trigger updates only when prediction error or uncertainty exceeds a threshold, reducing compute and avoiding unnecessary drift.
- Combining adaptation with learned perception invariances: the color-shift failure suggests missing invariance. Evaluate test-time augmentation (MEMO/TTT-MAE-style), feature whitening, or contrastive alignment to stabilize encoders against nuisance factors during adaptation.
Practical Applications
Summary
AdaJEPA introduces a plan–execute–adapt–replan loop that performs lightweight test-time adaptation inside model predictive control (MPC). Using the observed next-state transition as a self-supervised signal, it updates a small set of encoder/predictor parameters (often with a single gradient step) between MPC replans. Experiments show consistent gains in planning success under visual, dynamics, and layout shifts with negligible latency overhead and no additional labels or expert data.
Below are practical applications that derive from these findings, organized by deployment horizon, with sector links, concrete workflows/products, and feasibility notes.
Immediate Applications
These can be deployed now with existing MPC stacks and pretrained latent world models.
- Robotics and Industrial Automation (manufacturing, logistics, warehousing)
- Use cases:
- Pick-and-place, pushing, and assembly lines where object geometry, surface friction, lighting, or background change between batches or shifts.
- Warehouse mobile manipulation and bin picking that must keep working across varying distractors and partial occlusions.
- Tools/workflows:
- ROS2 “Adaptive MPC for JEPA” node: plugs into a robot’s planning stack; updates last encoder stage + first/last predictor blocks with a single gradient step per replan.
- On-robot recent-N buffer and parameter budget manager for per-episode adaptation; auto fall-back to frozen model if validation losses spike.
- Assumptions/dependencies:
- A pretrained JEPA-like world model for the task; on-board compute for a small per-replan gradient step; safety envelope around MPC (hard constraints, action limits).
- Autonomous Ground/Aerial Navigation (AMRs/AGVs, drones in facilities)
- Use cases:
- Facility navigation under evolving layouts (temporary obstacles, new aisles) and changed dynamics (payload variations, wind gusts).
- Tools/workflows:
- Integration into Nav2 or similar stacks: adapt predictor’s first layer + encoder tail; use CEM/GD planners already in deployment.
- Online health metrics: latent prediction loss and goal-distance deltas to gate adaptation intensity.
- Assumptions/dependencies:
- Reliable state estimation and short-horizon replanning; conservative collision-avoidance constraints during adaptation.
- Automotive ADAS and Robotics R&D (pilot/“shadow-mode”)
- Use cases:
- Adapting vehicle dynamics models to rain/snow/ice (road friction) or tire wear during MPC-based trajectory control in test fleets.
- Tools/workflows:
- Shadow-mode AdaJEPA module that learns online but does not actuate; compares adapted vs. frozen plans to build a safety case before activation.
- Assumptions/dependencies:
- Strict safety gating and formal guardrails; regulatory internal review; high-fidelity sensors for next-state observation.
- Building Controls and Energy (HVAC, process control)
- Use cases:
- Adaptive MPC in buildings facing occupancy/weather shifts; retuning chiller/boiler dynamics without manual re-identification.
- Tools/workflows:
- AdaJEPA plug-in for existing MPC controllers (e.g., Modelica/EnergyPlus co-sim): recent-N buffer from telemetry, single-step gradient updates per control cycle.
- Assumptions/dependencies:
- Sufficiently fast control loops and compute at the BMS controller; constraints to enforce comfort and equipment safety.
- Sim2Real Transfer for Robotics
- Use cases:
- Rapid on-site calibration when deploying sim-trained skills to new floors, lighting, or materials.
- Tools/workflows:
- Commissioning workflow: pretrain world model offline, then per-episode adaptation during initial runs to close the sim-to-real gap.
- Assumptions/dependencies:
- Conservative action limits during first deployments; robust logging and revert-to-baseline capability.
- AR/VR, Gaming, and Simulation Agents
- Use cases:
- Game/robot agents that must adapt to new maps or lighting variants without retraining, improving pathfinding and interaction robustness.
- Tools/workflows:
- Unity/Unreal plugin for MPC-driven agents with online latent calibration using AdaJEPA’s recent-N buffer.
- Assumptions/dependencies:
- Agents already using MPC-style planning over latent dynamics; stable frame-to-frame observations.
- Academia and Open Research
- Use cases:
- Robustness benchmarks that evaluate closed-loop test-time adaptation; courses/labs on adaptive world models.
- Tools/workflows:
- Reproducible stacks on PushT/PointMaze; ablation harnesses for which-parameters-to-adapt (encoder-last, predictor-first/last, LoRA).
- Assumptions/dependencies:
- Availability of datasets and pretrained JEPAs; minimal GPU for on-the-fly updates.
- Governance and Ops (immediate deployment hygiene)
- Use cases:
- Safety operations for adaptive controllers in production.
- Tools/workflows:
- Policies for: logging all updates/gradients, per-episode model copies, LR caps, parameter-update whitelists, and automatic rollback on anomaly.
- Assumptions/dependencies:
- Organizational agreement on monitoring, audit trails, and incident response for adaptive systems.
- Daily Life Devices
- Use cases:
- Robot vacuums and mowers that adapt to carpets, thresholds, or slope; consumer drones coping with wind or payload changes.
- Tools/workflows:
- Lightweight on-device adaptation: one-step updates to small parameter subsets; periodic reset to factory baseline.
- Assumptions/dependencies:
- Edge compute and battery budget; clear user safety constraints.
Long-Term Applications
These require additional research, scaling, verification, or regulatory clearance.
- Healthcare and Assistive Robotics
- Use cases:
- Surgical robots adapting to patient-specific tissue properties; rehabilitation exoskeletons adjusting to individual gait dynamics.
- Tools/products:
- Verified adaptive MPC with formal safety constraints; change-detection to pause adaptation under uncertainty.
- Assumptions/dependencies:
- Clinical validation, regulatory approval, and fail-safe designs; stronger representations trained on diverse, privacy-preserving data.
- General-Purpose Household Robots
- Use cases:
- Home assistants handling wide variations in objects, layouts, and lighting, continuously refining their world models during operation.
- Tools/products:
- Edge-optimized JEPA backbones; life-long learning pipelines combining per-episode adaptation with curated longer-term updates.
- Assumptions/dependencies:
- Robust continual learning to avoid drift; privacy safeguards for home data; reliable reset and supervision mechanisms.
- Autonomous Vehicles and Robotics at Fleet Scale
- Use cases:
- Fleet-wide adaptive dynamics calibration (weather, road surface, wear) with federated aggregation of adaptation signals.
- Tools/products:
- Population-based or federated AdaJEPA; server-side validation and gating; anomaly detection for outlier environments.
- Assumptions/dependencies:
- Communication and privacy frameworks; strict safety cases; integration with high-assurance planning stacks.
- Smart Factories and Digital Twins
- Use cases:
- Self-calibrating production cells that adapt to new SKUs/materials without reprogramming; digital twins that update latent dynamics online.
- Tools/products:
- Co-simulation bridges where real-time telemetry updates world models in the twin; adaptive recipes for process control.
- Assumptions/dependencies:
- High data fidelity; certification for mission-critical changes; well-specified failover to manual control.
- Energy Systems and Microgrids
- Use cases:
- Adaptive MPC for DERs and microgrids under changing demand/supply (renewables variability, asset aging).
- Tools/products:
- Constraint-aware AdaJEPA (hard safety bounds in MPC); operator dashboards exposing adaptation status and forecasts.
- Assumptions/dependencies:
- Grid code compliance; resilient sensing and telemetry; robust cybersecurity.
- Finance and Operations Research (cautious exploration)
- Use cases:
- Model-based control/optimization under shifting market/machine dynamics (e.g., inventory, logistics routing).
- Tools/products:
- Offline-pretrained latent dynamics with guarded online calibration; sandboxed A/B evaluation.
- Assumptions/dependencies:
- Strict risk management; regulatory compliance; clear segregation between adaptation and trading/execution until proven safe.
- Standards, Certification, and Policy
- Use cases:
- Defining standards for online-learning controllers: update scopes, logs, tests, and rollback.
- Tools/products:
- Audit specifications for adaptive MPC; certification checklists (parameter-update budgets, LR bounds, monitoring).
- Assumptions/dependencies:
- Cross-industry collaboration; conformance testing infrastructure.
- Tooling and Infrastructure
- Use cases:
- Real-time adaptation compilers, hardware acceleration for on-device gradient steps, and verified adaptive MPC solvers.
- Tools/products:
- Parameter-efficient adapters (e.g., LoRA) optimized for edge; formal verification of adaptation-triggered controllers.
- Assumptions/dependencies:
- Advances in low-latency autodiff on embedded platforms; practical verification methods for learning-in-the-loop.
- Education and Workforce Development
- Use cases:
- Training engineers on adaptive world models and safety-aware deployment.
- Tools/products:
- Open curricula and labs with AdaJEPA kits; standardized benchmarks for robustness and latency trade-offs.
- Assumptions/dependencies:
- Sustained support for open datasets, simulators, and reproducible baselines.
Notes on Feasibility Across Applications
- Strengths to leverage:
- Label-free, self-supervised updates using observed transitions.
- Minimal compute and latency overhead (often one gradient step on a small parameter subset).
- Works with common planners (GD or CEM) and different JEPA variants; improves OOD robustness.
- Typical dependencies/risks:
- Requires a reasonably capable pretrained latent world model and on-policy observation of next states.
- Safety-critical deployments need strict constraints, monitoring, and rollback; begin in shadow-mode.
- Adaptation hyperparameters (learning rate, steps, buffer size) should be bounded; defaults from the paper are strong starting points.
- Environments demanding features absent from training may benefit but not fully close the gap; combine with continual/active learning for coverage expansion.
Glossary
- Action chunk: A short sequence of consecutive actions executed as a unit between replans. "executes the first action chunk"
- Adaptive control: A control paradigm that updates model/controller parameters online to handle unknown or changing dynamics. "dates back to adaptive control"
- Anti-collapse stabilizer: A mechanism to prevent representation collapse during self-supervised training or adaptation. "stop-gradient as the default anti-collapse stabilizer"
- Augmentation-based consistency: A self-supervised objective that enforces consistent predictions across augmented versions of the same input. "augmentation-based consistency"
- CEM (Cross-Entropy Method): A sampling-based optimizer that iteratively fits a distribution to elite samples to improve action sequences. "sampling-based methods such as CEM"
- Closed-loop MPC: Using model predictive control in a feedback loop where planning, acting, observation, and replanning occur iteratively. "AdaJEPA performs test-time adaptation during closed-loop MPC."
- Curvature regularization: A penalty that encourages low-curvature (straighter) trajectories in latent space. "use curvature regularization to encourage straighter latent trajectories"
- Entropy minimization: A test-time adaptation objective that reduces predictive uncertainty on unlabeled test inputs. "entropy minimization"
- Frameskip: Executing or predicting every k-th frame so that each action spans multiple simulator frames. "We use a frameskip of 5"
- Goal-conditioned control: Control or planning tasks where the policy is conditioned on a specified goal state. "standard recipe for goal-conditioned control and planning."
- Hard-N: An online buffer strategy that retains the N transitions with the largest prediction errors. "hard-N keeps only the N transitions that result in the largest prediction errors"
- In-context learning: Adapting model behavior at inference via provided context (e.g., prompts) without updating model weights. "in-context learning"
- Joint-Embedding Predictive Architectures (JEPAs): Models that learn an encoder and a predictor by optimizing a latent prediction objective on reward-free trajectories. "Joint-Embedding Predictive Architectures (JEPAs)"
- Latent goal-reaching cost: A planning objective computed in latent space that measures distance to the goal representation. "minimizing a latent goal-reaching cost"
- Latent manifold: The learned representation space capturing valid structure of observations and dynamics. "remaining close to the learned latent manifold"
- Latent prediction loss: The loss comparing predicted future latent representations to target latents (e.g., MSE). "latent prediction loss"
- Latent rollouts: Forward predictions in latent space produced by a world model to evaluate future outcomes. "latent rollouts"
- Latent world model: A dynamics model that predicts future states in a compact latent space rather than pixel space. "an adaptive latent world model"
- LoRA: A low-rank adaptation method that adds trainable rank-decomposed updates to a frozen model for efficient tuning. "LoRA updates to the full model"
- Masked reconstruction: A self-supervised objective that reconstructs masked parts of the input, used for model adaptation or training. "masked reconstruction"
- Model predictive control (MPC): An online planning method that optimizes action sequences using a predictive model and replans as new observations arrive. "model predictive control (MPC)"
- Out-of-distribution (OOD): Data or environments that differ from those seen during training. "held-out OOD shapes"
- Plan--execute--adapt--replan loop: An iterative loop coupling planning, action execution, adaptation using new observations, and replanning. "plan--execute--adapt--replan loop"
- Prompt tuning: Adjusting prompts or prompt parameters to adapt vision-language or LLMs to new tasks. "prompt tuning of vision-LLMs"
- Proprioceptive embeddings: Learned representations of internal agent state signals (e.g., positions, velocities). "visual and proprioceptive embeddings"
- Recent-N: An online buffer strategy that keeps only the most recent N transitions for adaptation. "recent-N keeps only the most recent N transitions"
- Receding-horizon MPC: MPC that optimizes over a moving finite horizon and executes only the first action(s) before replanning. "We use receding-horizon MPC for all experiments"
- Replay buffer: A memory of recent transitions used for training or adaptation updates. "We maintain a replay buffer containing the 5 most recent samples."
- Self-supervised adaptation signal: An unlabeled target (e.g., the observed next state) used to update the model at test time. "a self-supervised adaptation signal"
- Squared Euclidean distance: The L2 distance squared, often used as a latent-space metric in planning costs. "typically the squared Euclidean distance"
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor during backpropagation. "stop-gradient operator"
- Temporal straightening: A training principle/regularization that encourages straighter (low-curvature) latent trajectories over time. "WM w/ Temporal Straightening"
- Temporal weights: Coefficients applied to per-step costs across the planning horizon to shape the objective. "α_k are temporal weights"
- Test-time adaptation (TTA): Updating a pretrained model on test inputs to reduce distribution shift without labeled targets. "Test-time training/adaptation (TTT/TTA)"
- Test-time training (TTT): Performing self-supervised training during inference to improve robustness to distribution shifts. "Test-time training/adaptation (TTT/TTA)"
Collections
Sign up for free to add this paper to one or more collections.

