HABIT: Human-Aware Behavior and Interaction Training Dataset for Robot Manipulation
Abstract: Large-scale demonstration datasets have been central to recent progress in general-purpose robot policies. However, existing datasets are collected in human-absent settings, and policies trained on such data may perform tasks competently in isolation but fail to exhibit human-aware behaviors. To address this gap, we introduce HABIT, a large-scale robot demonstration dataset for human-present environments. We organize tasks into three roles capturing distinct modes of human-robot interaction: Collaborator, where human and robot jointly accomplish a task; Coworker, where they pursue separate tasks in a shared space; and Supervisor, where the human directs the robot. The dataset comprises over 10K episodes and over 160 hours across 60 tasks. Our experiments show that training on human-present data elicits human-aware behaviors that robot-only data fails to produce: spatiotemporal synchronization in Collaborator tasks, yielding in Coworker tasks, and gesture grounding in Supervisor tasks. Moreover, training on HABIT enables rapid adaptation to new human-robot interaction tasks. By introducing human presence as a new axis of dataset diversity, HABIT extends robot policies to environments shared with humans.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces HABIT, a big collection of robot “lessons” made while a human is in the same workspace as the robot. Most robot training data is recorded with robots working alone. HABIT changes that by recording over 160 hours of human-and-robot teamwork across 60 different tasks, so robots can learn to be safe, polite, and helpful around people.
What questions were the researchers trying to answer?
In simple terms, they asked:
- Can robots learn better manners and safety when they’re trained with humans nearby, instead of only in empty rooms?
- What kinds of human-aware behaviors can robots pick up from this kind of data? For example: waiting their turn, matching a partner’s timing, and following hand-pointing.
- If we give a robot this human-present practice first, can it learn new human-robot tasks faster later?
How did they build the dataset and test ideas?
Think of teaching a robot like teaching someone a new team sport. You don’t just show them how to handle the ball alone; you also practice with teammates on the field. HABIT does this for robots.
Here’s how it works, in everyday terms:
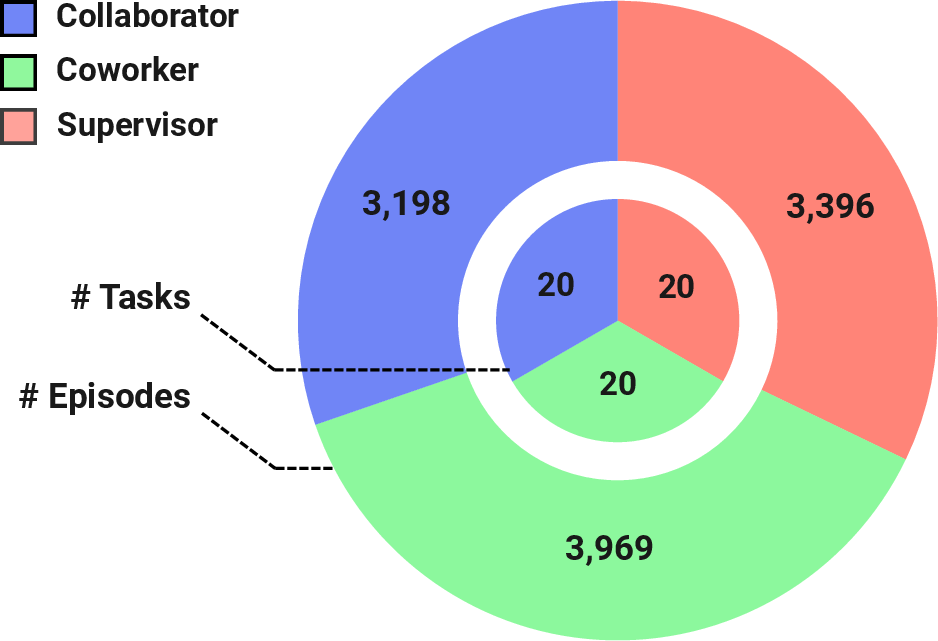
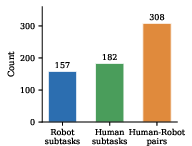
- The team recorded 10,563 “episodes” (like short lessons) where a human and a robot work in the same space. A human teleoperated two robot arms (like remote-controlling them) to demonstrate how the robot should behave.
- Five cameras watched the scene: three near the robot and two from the human’s side, so the robot can “see” what the person is doing.
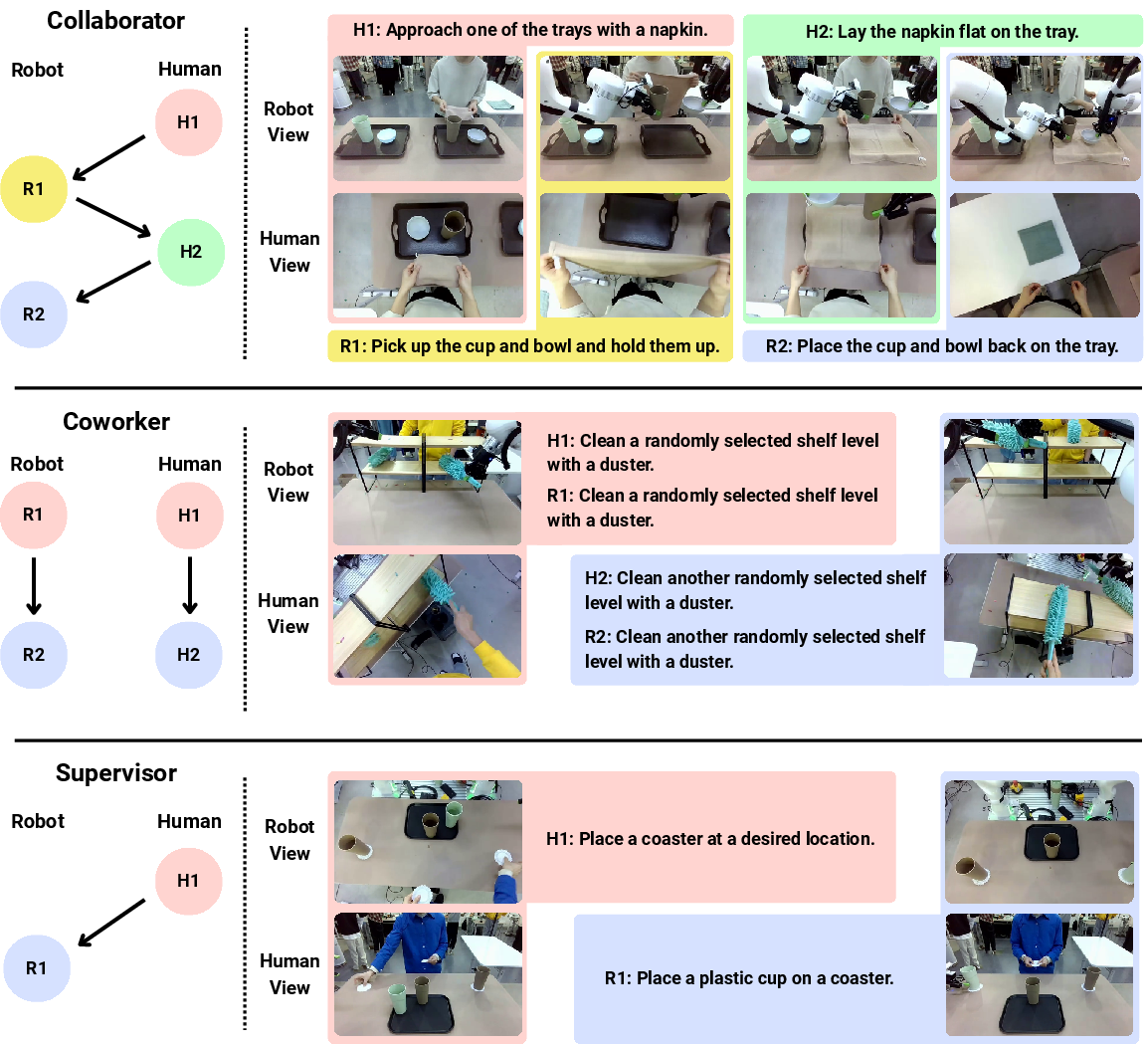
- Tasks were grouped by the human’s role:
- Collaborator: human and robot physically work together on one task (like holding a bucket together or handing items back and forth).
- Coworker: both do separate tasks in the same area, so the robot must avoid bumping into the person.
- Supervisor: the human points or gestures to tell the robot what to do, and the robot must follow those cues.
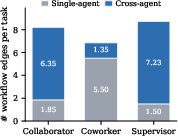
To make the lessons clear and consistent, each task had a step-by-step “workflow” for who does what and when—like a dance routine that says “Human does step 1, Robot does step 2,” and so on. They also followed “reactive interaction,” meaning the robot only moved after seeing the human’s cue, so the robot learns to respond to what it sees.
They added variety so the robot wouldn’t overfit to one look or pace:
- Humans wore different clothes and moved at different speeds.
- The order of objects changed between episodes.
- Safety was always first: if there was a chance of collision, the robot was taught to yield—pull back and let the human go first.
Finally, they trained two different “robot brains” (vision-language-action models) on HABIT and compared them to training on standard robot-only data. They measured success by three simple rules:
- Did the robot do the task correctly?
- Did it follow the planned order and timing with the human?
- Did it avoid touching the human or human-held objects?
What did they find, and why is it important?
Main results:
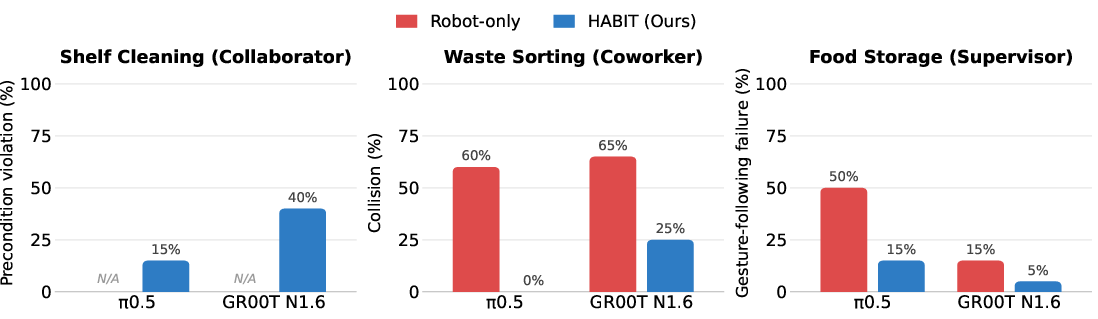
- Robots trained with HABIT were better at tasks involving people. They especially improved in “Coworker” tasks, where avoiding collisions and yielding is crucial.
- Helpful behaviors emerged naturally from data that included humans:
- Yielding and collision avoidance in shared spaces.
- Following pointing gestures when the human was directing the robot.
- Matching timing with a human partner in collaborative tasks.
- In “Supervisor” tasks, the benefit depended on the situation. When simple language instructions were enough, both datasets did similarly. When there were tricky choices (like multiple possible places to put an object), training with human gestures in HABIT helped more.
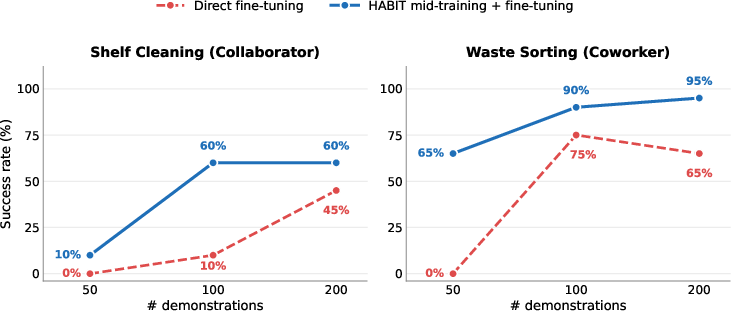
- Pretraining on HABIT made robots learn new human-robot tasks faster later, needing fewer new examples to reach good performance.
Why it matters:
- Most real-world places—homes, shops, factories—are shared with people. Robots must do more than move objects; they must coordinate politely and safely. HABIT gives robots the kind of practice that teaches this.
What’s the impact of this research?
HABIT shows that including humans in training data isn’t just a nice-to-have—it changes how robots behave. With human-present practice, robots:
- Become safer around people.
- Understand human cues like pointing.
- Coordinate better in shared tasks and spaces.
- Adapt faster to new human-robot jobs.
This could make future robots more trustworthy teammates in everyday environments. Next steps include using the extra camera views from the human’s side to learn even finer human cues and testing whether this “human-aware” learning transfers to brand-new tasks that only have robot-only demos.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain after this work and could guide future research:
- Generalization to new environments: Evaluate how HABIT-trained policies transfer to different rooms, layouts, lighting, backgrounds, and camera placements beyond the single collection site.
- Unseen human generalization: Quantify performance with entirely new human partners not present in training (varying height, clothing styles, skin tones, mobility patterns, handedness, and motion idiosyncrasies).
- Multi-human and multi-robot interactions: Extend tasks and evaluation to 1-to-many, many-to-1, and many-to-many settings with turn-taking, role switches, and inter-human coordination or conflicts.
- Mobile manipulation and navigation: Test whether human-aware behaviors transfer to mobile bases and mixed navigation–manipulation tasks in shared spaces (e.g., passing in hallways, joining queues).
- Longer-horizon, interleaved workflows: Study robustness on extended, partially ordered task graphs where dependencies are non-local and interruptions/priority changes occur mid-execution.
- Safety beyond binary collisions: Introduce and report continuous safety metrics (clearance, near-miss counts, time-to-collision, applied forces, speed thresholds), and quantify the efficiency–safety trade-off (e.g., yielding frequency vs. task time).
- Robustness to occlusion and clutter: Evaluate gesture following and yielding under heavy occlusions, partial views, and dynamic clutter (including human/robot self-occlusions).
- Ambiguous, delayed, or deceptive cues: Stress-test and benchmark policies under ambiguous, conflicting, or intentionally misleading gestures; measure failure modes and recovery behaviors.
- Multimodal intent cues: Incorporate and ablate additional modalities (gaze, head pose, speech/audio, depth, tactile/force) to determine which signals most improve intent understanding and safety.
- Use of human-side views: Develop and compare architectures/fusion strategies that exploit the human egocentric and global exocentric cameras; quantify their contributions under occlusion and fine-grained disambiguation.
- Cross-embodiment transfer: Test whether mid-training on HABIT improves human-aware behavior for different robot morphologies (single-arm, multi-finger hands, mobile manipulators) and grippers.
- Cultural and social norm variability: Assess whether behaviors (e.g., acceptable distances, handover etiquette, pointing conventions) generalize across cultures and propose data/metrics to model such variability.
- Natural language supervision: Move beyond indexed instructions to free-form, possibly underspecified natural language; measure whether policies appropriately defer, ask for clarification, or seek disambiguation.
- Persistence of human-aware priors: Verify whether human-aware behaviors persist when HABIT-pretrained policies are fine-tuned solely on robot-only data for new tasks, and define conditions under which they degrade.
- Ablations of data-collection choices: Isolate the causal impact of reactive interaction rules, tempo variation, and safety-first yielding on learned behavior via controlled ablation studies.
- Expanded gesture taxonomy and annotations: Provide fine-grained gesture types, 2D/3D human pose, hand keypoints, and referent labels to support supervised learning and analysis of cue grounding.
- Temporal coordination metrics: Introduce quantitative measures (e.g., sync lag, lead/lag variance, idle time) to evaluate spatiotemporal coordination quality, not just success/failure.
- OOD shifts beyond human appearance: Evaluate robustness to novel objects, tool shapes, materials, and unseen task props; analyze failure modes and data needs for adaptation.
- Label quality and scalability: Document and evaluate annotation consistency for workflows/subtasks at scale; explore semi-automated or weakly supervised labeling for broader dataset growth.
- Ethical, privacy, and bias assessment: Provide systematic analyses of demographic representation, potential bias in behavior around different users, and privacy-preserving releases (e.g., face blurring, voice masking) without losing utility.
- Real-time safety guarantees: Integrate and test control-theoretic safety layers (e.g., control barrier functions) with HABIT-trained policies; measure the interplay between learned yielding and formal safety guards.
- Efficiency and productivity metrics: Quantify task throughput and human workload/effort (e.g., interruptions, waiting time), enabling optimization of both safety and efficiency.
- Cross-dataset composition: Study whether adding a small amount of human-present data to large human-absent datasets suffices to elicit human-aware behavior, and identify minimal data budgets.
- Benchmark standardization: Establish multi-site, reproducible evaluation protocols with multiple human operators per site to reduce operator-specific bias and improve external validity.
- Failure detection and recovery: Develop mechanisms for online detection of role-specific failures (precondition violations, gesture errors, impending collisions) and define recovery policies.
- Curriculum and data scaling laws: Characterize how human-aware competence scales with hours, task diversity, and role balance; identify curricula that most efficiently induce emergent social behaviors.
Practical Applications
Below is a concise mapping from the paper’s findings to practical, real-world applications, grouped by time horizon. Each item notes the most relevant sector(s), what could be deployed or built, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Human-aware cobots that yield and avoid collisions in shared workspaces
- Sectors: Manufacturing, Warehousing, Logistics
- What to deploy/build: Fine-tune existing VLA/WAM-based cobot policies (e.g., OpenVLA, Octo, π-series, GR00T variants) using HABIT to inject reactive yielding, path conflict resolution, and shared-space etiquette for tasks like kitting, bin sorting, and box packaging.
- Tools/workflows: “HABIT Fine-Tune Pack” (training scripts + data loaders for robot-side cameras), role-aware evaluation harness using HABIT’s manipulation/workflow/safety metrics.
- Assumptions/dependencies: Some domain adaptation needed from bimanual Franka to target hardware; multi-camera or equivalent perception required; on-site validation for layout-specific edge cases; safety interlocks remain necessary.
- Gesture-directed placement and picking
- Sectors: Retail, Warehousing, Healthcare (clinics, labs), Hospitality
- What to deploy/build: Policies that follow human pointing to disambiguate target items/locations (e.g., “put the donut here,” “store bread in that bin”) using HABIT Supervisor role data.
- Tools/workflows: Gesture-grounded VLA heads; UI for staff to point and confirm; fallback to indexed language instructions in low-visibility cases.
- Assumptions/dependencies: Adequate camera coverage of gesture; consistent gesture conventions; controlled lighting; privacy constraints when capturing human video.
- Spatiotemporally synchronized collaboration
- Sectors: Hospitality (table setting), Facilities (cleaning), Light assembly
- What to deploy/build: Task flows where the robot times actions with the human (e.g., lift plate as human places napkin; dust shelf after human clears items), guided by HABIT’s Collaborator workflows.
- Tools/workflows: Workflow-aware supervisors that gate robot subtasks on detected human preconditions; timeline monitors that enforce ordering constraints at run time.
- Assumptions/dependencies: Clear visual cues for human subtask completion; latency budgets to react in real time; task-specific tuning for force/impedance in close proximity.
- Pre-deployment HRI safety and compliance testing
- Sectors: Robotics (vendors, integrators), Manufacturing QA, Safety engineering
- What to deploy/build: Benchmarks and acceptance tests derived from HABIT’s criteria (manipulation, workflow compliance, human safety). Use role-specific failure analysis as regression tests.
- Tools/workflows: Automated test harness scoring “trial success rate” per Eq. (1); role-specific scenario suites (yielding events, gesture-ambiguity, cross-agent ordering).
- Assumptions/dependencies: Mapping from lab tasks to enterprise-relevant test tasks; recorded human-in-the-loop trials; organizational safety policies.
- Sample-efficient bootstrapping of new HRI tasks
- Sectors: Robotics startups, System integrators, R&D labs
- What to deploy/build: Mid-train on HABIT to cut the number of new teleop demos needed for customer-specific tasks; prioritize tasks with shared-space coordination or gesture following.
- Tools/workflows: Two-stage training pipelines (HABIT mid-training + small downstream fine-tune); active-learning loops to select informative demos.
- Assumptions/dependencies: Compute budget for mid-training; distribution gap management (geometry, objects, dynamics); consistent camera viewpoints.
- Academic benchmarking for human-present robot learning
- Sectors: Academia, Corporate research
- What to deploy/build: Standardized baselines comparing robot-only vs. human-present training across Collaborator/Coworker/Supervisor roles; ablations of reactive interaction and behavior-elicitation protocols.
- Tools/workflows: Public leaderboards for role-specific metrics; reproducible evaluation protocols per the paper’s appendices.
- Assumptions/dependencies: Community adoption; consistent scoring; licensing for dataset use.
- Teaching and training materials for HRI courses and internal upskilling
- Sectors: Education, Enterprise L&D
- What to deploy/build: Curricula and lab assignments demonstrating how human-aware behaviors emerge from human-present data; role-based task design exercises.
- Tools/workflows: Notebook-based training labs; video analyses of role-specific failures and remedies via HABIT.
- Assumptions/dependencies: Access to compute and (optional) hardware; dataset availability in course settings.
- Rapid prototyping of gesture-grounded UIs for accessibility
- Sectors: Healthcare, Assistive technology, Elder care
- What to deploy/build: Pilot assistants directed by pointing/gestures for users with limited speech; tasks like fetching, placing, or handing over objects.
- Tools/workflows: Minimal-UI interfaces using wearable or room cameras; confirmation prompts; geofenced safety zones.
- Assumptions/dependencies: Care environment approvals; privacy safeguards; robust gesture detection under occlusion; caregiver oversight.
- Data collection and teleoperation SOPs for human-aware demos
- Sectors: Robotics services, System integration
- What to deploy/build: Adopt HABIT’s reactive-interaction and behavior-elicitation protocols (yielding priority, variable tempos, gestural timing bins) as standard operating procedures for new demo collection.
- Tools/workflows: Checklists enforcing on-camera cueing only; variable-speed scripts; collision-retraction policies during teleop.
- Assumptions/dependencies: Operator training; instrumentation to ensure cues are in view; adherence to safety-first rules.
- Compute-efficient training using robot-side cameras
- Sectors: Software tooling, SMB robotics
- What to deploy/build: Training recipes that use only robot-side views (as in the paper’s experiments) to cut costs, with a pathway to add human egocentric/exocentric when budgets allow.
- Tools/workflows: Modular dataloaders; view-selection ablations; cost-per-success dashboards.
- Assumptions/dependencies: Accepting some loss of disambiguation without human-side views; careful camera placement on the robot.
Long-Term Applications
- Generalist, human-aware robot foundation models
- Sectors: Robotics, Software
- What to build: Foundation VLA/WAM models pre-trained on large human-present corpora (extending HABIT) that transfer human-aware behaviors across embodiments and tasks.
- Tools/products: “HRI-prior” checkpoints; cross-embodiment adapters for humanoids, mobile manipulators; role-conditioned policy heads.
- Assumptions/dependencies: Additional multi-site data; cross-embodiment alignment; scalable training infrastructure.
- Multi-agent (multi-human/multi-robot) shared-space coordination
- Sectors: Manufacturing, Construction, Logistics
- What to build: Policies coordinating with several humans and robots, resolving complex path conflicts and task handovers.
- Tools/products: Interaction planners that consume multi-view feeds; crowd-aware yielding policies; team-level workflow graphs.
- Assumptions/dependencies: New datasets beyond one-human/one-robot; higher-level traffic rules; robust forecasting of human motion.
- Standards and certification for human-aware behavior
- Sectors: Policy, Standards bodies, Insurance, Compliance
- What to build: Role-specific certification tests and KPIs (e.g., maximum collision rate, time-to-yield thresholds) integrated with or complementing ISO/TS 15066 and related norms.
- Tools/products: Audit suites derived from HABIT metrics; black-box conformance testing services; insurer-backed safety ratings.
- Assumptions/dependencies: Cross-industry consensus; regulatory adoption; third-party test facilities.
- Privacy-preserving egocentric/exocentric fusion
- Sectors: Healthcare, Smart buildings, Public venues
- What to build: Models that leverage human-worn and room cameras for disambiguation (e.g., precise referent of a point) while preserving privacy via on-device processing and selective retention.
- Tools/products: Federated learning pipelines; on-device gesture interpreters; redaction/blur tooling; consent management.
- Assumptions/dependencies: Policy and legal frameworks for video capture; compute at the edge; user acceptance.
- In-home service robots directed by natural gestures and routines
- Sectors: Consumer, Elder care
- What to build: Domestic assistants that coordinate cleaning, setting tables, or tidying while respecting household members’ movements and preferences.
- Tools/products: Routine-learned workflow graphs; personalization layers; fail-safes for pets/children in shared spaces.
- Assumptions/dependencies: Robust perception in clutter; long-horizon planning; affordable hardware; strong safety assurances.
- Human-aware hospital logistics and clinical support
- Sectors: Healthcare
- What to build: Robots transporting supplies, restocking, or assisting nurses with gesture-directed deliveries in busy hallways and shared treatment areas.
- Tools/products: Gesture-aware destination selection; dynamic yielding under varying urgency; infection control compliance.
- Assumptions/dependencies: Clinical approvals, rigorous risk management; integration with hospital IT and schedules; sanitation requirements.
- Construction and field co-work with skilled trades
- Sectors: Construction, Field services
- What to build: Robots that hand tools, hold fixtures, or stabilize materials while adapting to workers’ pace and signals.
- Tools/products: Ruggedized perception stacks; force/impedance control; gesture + voice fusion for noisy environments.
- Assumptions/dependencies: Outdoor/harsh-condition robustness; safety certification; large domain shift from lab to site.
- Digital twins and simulation for HRI stress testing
- Sectors: Software, Safety engineering
- What to build: Synthetic data generators calibrated by HABIT’s real trajectories to simulate rare but critical human-robot interactions and failure cases.
- Tools/products: Scenario libraries for pre-silicon and pre-deployment verification; counterfactual safety analysis.
- Assumptions/dependencies: High-fidelity human motion and interaction models; validated domain transfer to real-world behavior.
- Accessible HRI interfaces for speech- or vision-impaired users
- Sectors: Assistive technology, Public sector
- What to build: Multimodal cue-following policies combining gestures, touch panels, or proxemics as alternatives to speech.
- Tools/products: Low-vision friendly marker systems; tactile confirmation devices; personalized cue profiles.
- Assumptions/dependencies: Co-design with users; robust detection across abilities; clinical/usability studies.
- Organization-wide HRI governance and workforce integration
- Sectors: Policy, HR, Operations
- What to build: Training and governance frameworks that codify human-first yielding, clear role workflows, and incident logging aligned with HABIT’s role taxonomy.
- Tools/products: SOPs and playbooks; incident dashboards tied to role-specific KPIs; retraining schedules based on failure statistics.
- Assumptions/dependencies: Change management; worker acceptance; data-sharing agreements for continuous improvement.
Notes on feasibility across applications:
- Hardware/embodiment dependency: HABIT’s data uses bimanual Franka arms; transferring behaviors to other arms or mobile platforms requires adaptation and validation.
- Perception dependency: Many gains rely on reliable multi-view perception of humans and their cues; degraded sensing reduces effectiveness.
- Distribution shift: The dataset’s single environment and limited operator diversity may necessitate site-specific fine-tuning.
- Safety dependency: Even with human-aware training, hard safety layers (geofencing, force limits, emergency stops) remain essential.
- Legal/ethical dependency: Using human egocentric/exocentric views must respect privacy, consent, and regulatory requirements.
Glossary
- bimanual manipulation: Robot manipulation using two arms or effectors in coordination. "164 hours of bimanual manipulation"
- Collaborator (role): A human-robot interaction role where both agents jointly accomplish a shared task through close coordination. "Collaborator, where human and robot jointly accomplish a task"
- collision avoidance: The behavior of preventing contact with a human or human-held objects during shared work. "collision avoidance under the Coworker role"
- co-located: Situated in the same place as another cue or agent, aiding disambiguation. "a co-located pointing gesture"
- co-present: Human and robot are present together and share the same workspace during task execution. "a co-present human shares the workspace with the robot"
- Coworker (role): A role where human and robot pursue separate subtasks in the same space without direct contact, requiring safe coordination. "Coworker, where they pursue separate tasks in a shared space"
- cross-embodiment transfer: Transferring learned policies or skills across different robot bodies or platforms. "enable cross-embodiment transfer"
- directed graph: A graph with ordered edges used to encode subtask sequencing and dependencies. "a task workflow is a directed graph"
- egocentric view: A first-person camera perspective from the agent, capturing what the agent would see. "an egocentric view angled forward"
- embodiment: The specific physical form or hardware configuration of a robot. "multiple embodiments"
- exocentric view: A third-person camera perspective that captures the overall scene and agents’ relations. "the exocentric view, plausibly carry signals"
- gesture following: Interpreting and acting in response to human gestures as task-relevant cues. "gesture following"
- gesture grounding: Linking a human gesture to a specific referent in the visual scene to determine the intended target or action. "gesture grounding in Supervisor tasks"
- Human-Robot Interaction (HRI): The field studying how humans and robots collaborate, communicate, and share tasks. "Human-Robot Interaction (HRI) literature"
- human-aware behaviors: Robot behaviors that account for human presence, safety, intent, and coordination cues. "human-aware behaviors that robot-only data fails to produce"
- mid-training: An intermediate training stage on a prior dataset before fine-tuning on a target task to improve adaptation. "mid-training on HABIT enables sample-efficient adaptation"
- morphology: The structural configuration or body form of a robot used for control and learning. "our bimanual Franka morphology"
- out-of-distribution (OOD): Data or conditions that differ from those seen during training, used to test generalization. "out-of-distribution (OOD) evaluation"
- precondition violation: Executing an action before its required human or environmental precondition is satisfied. "Precondition violation (i.e., pre-executing the next subtask before the human has completed theirs)"
- reactive interaction: A data-collection principle where each agent acts only after observing the partner’s behavior, ensuring learnable cues. "we adopt reactive interaction as a core principle of data collection"
- role-specific failures: Failure modes tied to a particular interaction role (e.g., collisions in Coworker, gesture errors in Supervisor). "We refer to these three role-dependent failures collectively as role-specific failures"
- spatiotemporal synchronization: Coordinating in both space and time with a human partner during joint tasks. "spatiotemporal synchronization in Collaborator tasks"
- Supervisor (role): A role where the human directs the robot via explicit cues such as pointing or demonstrations. "Supervisor, where the human directs the robot"
- teleoperation: Controlling a robot remotely by a human operator, often to collect demonstrations. "teleoperation"
- Vision-Language-Action (VLA) models: Models that map visual and language inputs to action outputs for robotic control. "vision-language-action (VLA) models"
- workflow (task workflow): A structured specification of human and robot subtasks and their execution order. "task workflow"
- workflow compliance: Adhering to the workflow’s ordering and coordination constraints during execution. "Workflow compliance"
- World Action Models (WAMs): Video or world models used directly as policies to produce actions in robotic control. "world action models (WAMs)"
- yielding: Proactively deferring or retracting to avoid interfering with a human’s motion, prioritizing safety. "yielding under safety-first priority"
Collections
Sign up for free to add this paper to one or more collections.

