AIRoA MoMa Dataset: A Large-Scale Hierarchical Dataset for Mobile Manipulation
Abstract: As robots transition from controlled settings to unstructured human environments, building generalist agents that can reliably follow natural language instructions remains a central challenge. Progress in robust mobile manipulation requires large-scale multimodal datasets that capture contact-rich and long-horizon tasks, yet existing resources lack synchronized force-torque sensing, hierarchical annotations, and explicit failure cases. We address this gap with the AIRoA MoMa Dataset, a large-scale real-world multimodal dataset for mobile manipulation. It includes synchronized RGB images, joint states, six-axis wrist force-torque signals, and internal robot states, together with a novel two-layer annotation schema of sub-goals and primitive actions for hierarchical learning and error analysis. The initial dataset comprises 25,469 episodes (approx. 94 hours) collected with the Human Support Robot (HSR) and is fully standardized in the LeRobot v2.1 format. By uniquely integrating mobile manipulation, contact-rich interaction, and long-horizon structure, AIRoA MoMa provides a critical benchmark for advancing the next generation of Vision-Language-Action models. The first version of our dataset is now available at https://huggingface.co/datasets/airoa-org/airoa-moma .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces a big, carefully organized collection of robot data called the AIRoA MoMa Dataset. It’s designed to help robots learn how to do real household jobs that involve both moving around and using their arm and hand (like a person would). Think of tasks like turning on a lamp, hanging a towel, making coffee, or using a dishwasher. The dataset gives robots “experience” they can learn from, including what the robot saw, how it moved, and what it felt when touching things.
The main goals and questions
The researchers wanted to:
- Give robots the kind of data they really need to succeed in the real world, not just on a tabletop.
- Include tasks that have many steps and require actual physical contact (like pushing buttons or pulling a chain), not just picking and placing objects.
- Record a “sense of touch” (force and torque) along with camera images and robot movements, so robots can learn how things feel when they push, pull, or press.
- Organize each task into clear steps (like a recipe) so robots can learn both the big plan and the small actions.
- Include not only successes but also failures, so robots can learn how to avoid and recover from mistakes.
How they built the dataset (methods explained simply)
The robot and the setting
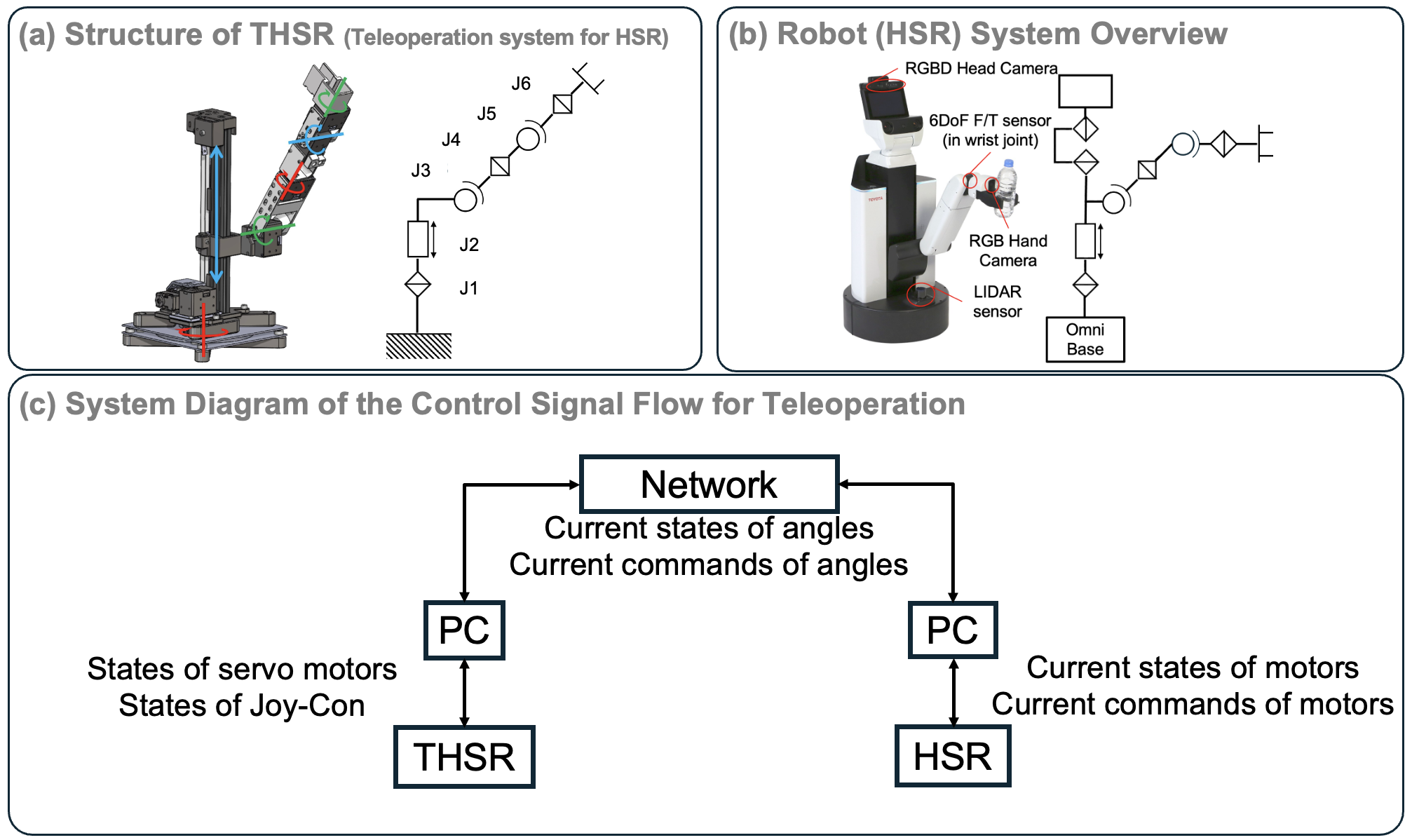
They used a helper robot called HSR (Human Support Robot). It can roll around, move its arm and head, and open and close a simple gripper (hand). The team set up rooms like a kitchen, living room, and bathroom to imitate a home.
What they recorded
At each moment in time, they saved synchronized data (all lined up in time so it matches perfectly):
- Two camera views: a “head” camera (wide view) and a “wrist” camera (close-up).
- Robot posture and movement: arm joints, head angles, gripper, and base movements.
- Force-torque signals: like the robot’s sense of touch and pressure at its wrist in 6 directions (pushing/pulling and twisting).
- The human operator’s control signals: what the person did to control the robot.
They resampled everything to the same speed (30 times per second), so all the streams line up.
How the data was collected (teleoperation)
Instead of writing a complicated program for every task, trained people controlled the robot by hand. Think of it like a “puppet” system:
- The human moved a “leader” arm device (like a physical joystick shaped like an arm).
- The robot (“follower”) copied those joint angles directly, so it moved in the same way.
- A game controller (like a Joy-Con) controlled the robot’s rolling base and some other parts. This avoids tricky math called “inverse kinematics” and makes control safer and more natural.
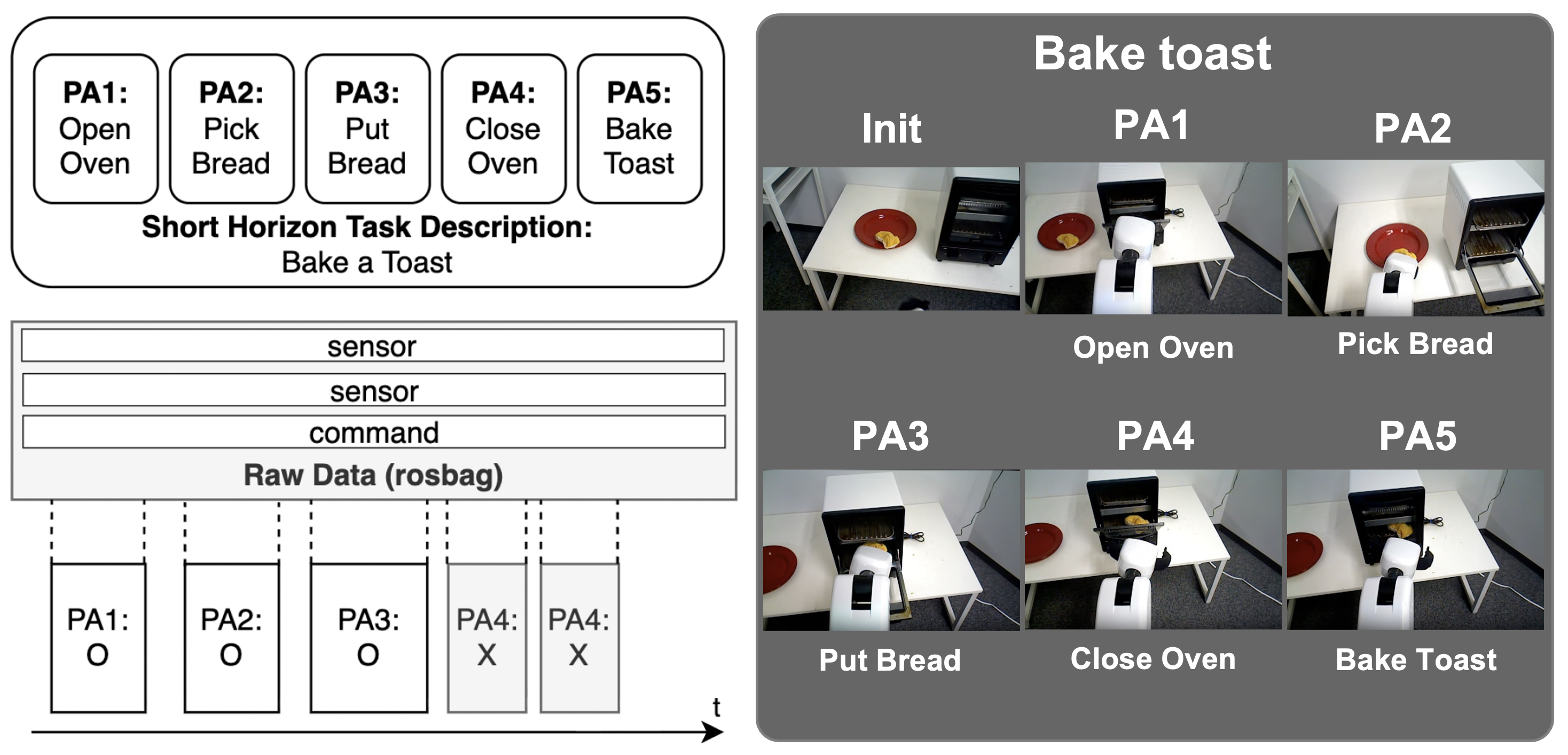
Breaking tasks into steps (hierarchical labels)
Each task is split into:
- Short Horizon Task (SHT): the overall job, like “Bake a toast.”
- Primitive Actions (PAs): the individual steps, like “Open oven,” “Pick bread,” “Put bread in,” “Close oven,” “Press bake.”
This is like a recipe: the SHT is the dish, and the PAs are the steps. They also mark each step as success or failure, which helps analyze where and why things go wrong.
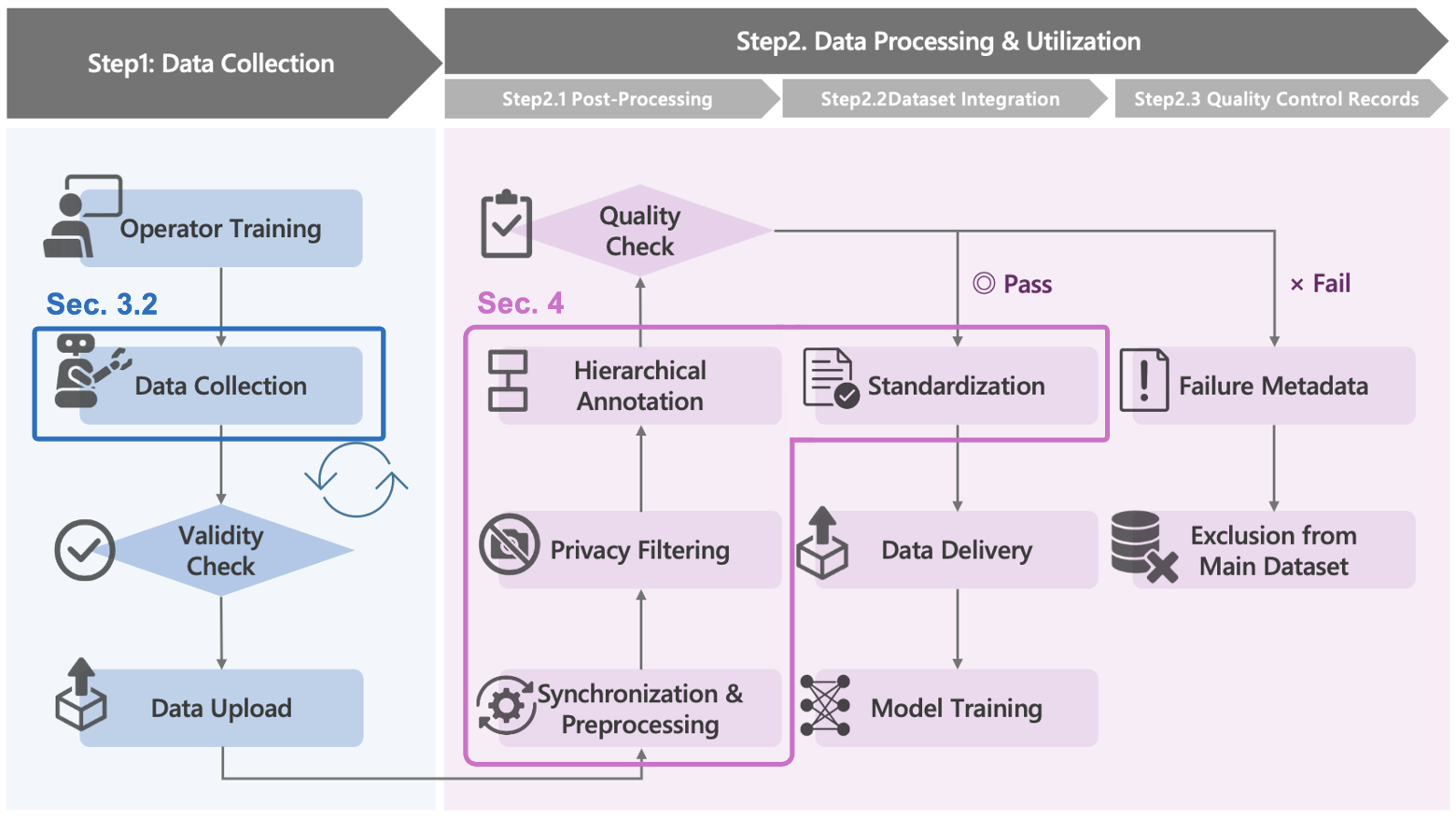
Quality checks and privacy
They filtered out bad or odd data (for example, episodes with no motion or out-of-range sensor values), synchronized all sensors, and standardized the format so others can use it easily. They also used automatic person detection to exclude videos showing people’s faces for privacy.
What’s in the dataset and why it matters
- Size: 25,469 episodes (about 94 hours of robot activity) across seven household tasks.
- Examples of tasks: hang a towel, turn a desk lamp on/off (button press or chain pull), bake toast, make coffee, stand slippers in a rack, load/unload a dishwasher.
- Sensors: dual RGB cameras, joint positions, robot base motion, and 6-axis force-torque at the wrist.
- Structure: every episode is split into clear steps (Primitive Actions), each with success/failure labels.
- Failures included: about 6.6% of episodes have mistakes like missed grasps or misalignment. This is important—robots learn a lot from what went wrong.
- Standard format: released in the LeRobot v2.1 format on Hugging Face, so researchers can plug it right into popular robot-learning methods.
Why this is important:
- Real-world tasks are “contact-rich” (pressing, pulling, turning), not just “see and pick.” This dataset includes the “feel” (force/torque) needed to learn those skills.
- Many real tasks are multi-step. The step-by-step labels help robots learn both planning (which step comes next) and control (how to do that step).
- Mobile manipulation (moving and manipulating) is harder and more realistic than staying at a fixed table. This dataset focuses on that.
The main takeaways
- The dataset is big, diverse, and carefully organized for multi-step, real household tasks.
- It includes a rare and valuable signal—force-torque—that helps robots learn safe, reliable contact behaviors.
- It’s annotated in a hierarchy (task → steps) and includes failures, making it ideal for training and testing smarter, more robust robot models.
- It’s easy to use and compare results thanks to a standard format and an open processing pipeline.
What this could lead to (impact)
With this dataset, researchers can train and evaluate next-generation robot models that follow language instructions and act in the real world, not just in simple lab setups. Over time, this could make assistive robots better at:
- Understanding step-by-step instructions (like a recipe),
- Handling delicate contact tasks safely (like pressing buttons or opening doors),
- Recovering from mistakes,
- Working in homes, hospitals, and other everyday environments.
In short, this dataset is a strong step toward helpful, general-purpose robots that can actually do useful things around people.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain unresolved by the paper and dataset release:
- Limited embodiment diversity: all data come from a single platform (Toyota HSR, 4-DOF arm, 1-DOF gripper), restricting cross-embodiment generalization and policy transfer; no data from bimanual, multi-finger, or different end-effectors.
- Environment scope: data were collected in a single lab mimicking household settings; no multi-site, real-home deployments, or cross-country variability to assess robustness under broader domain shifts.
- Task coverage: only seven Short Horizon Tasks (SHTs) are included; breadth across household tasks, tool use, deformables, and multi-object workflows remains limited despite >40 sub-tasks.
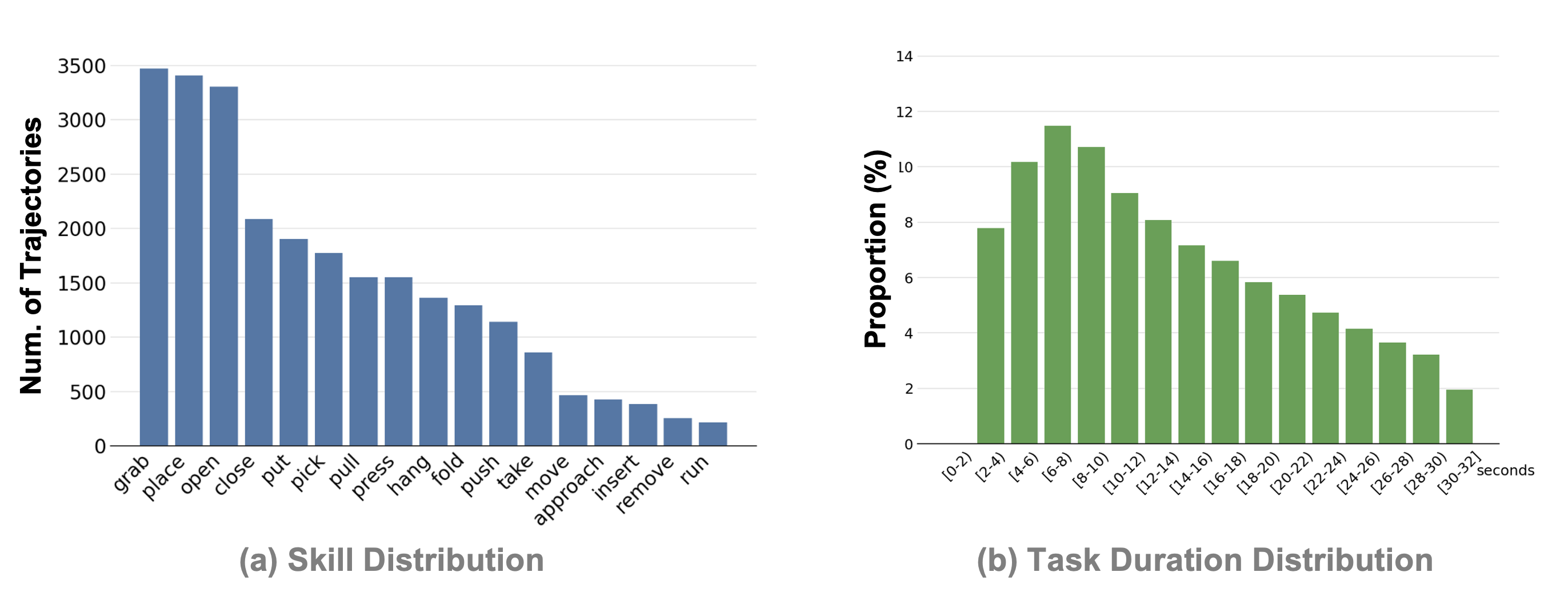
- Short-horizon bias: episodes average ~13s and the distribution is dominated by short, discrete primitives; the dataset currently underrepresents genuinely long-horizon, interleaved navigation–manipulation sequences.
- Navigation observability gap: absolute base pose, odometry, IMU, or map/SLAM information is not provided (only relative base increments). This limits learning and evaluation of integrated navigation–manipulation policies and reproducibility of base motion.
- Missing depth and 3D calibration: no depth streams or camera intrinsics/extrinsics are reported, limiting 3D perception, pose estimation, and geometry-aware policy learning.
- High-frequency dynamics loss: joint and force–torque measurements were downsampled to 30 Hz (from 100 Hz) with no access to raw high-frequency logs, potentially discarding critical contact dynamics for force-sensitive control.
- Force–torque calibration and drift: procedures for FT zeroing, drift compensation, and long-horizon stability are not described; users cannot assess measurement reliability or reproduce calibration.
- Limited haptics modalities: only wrist 6-axis FT is included; no tactile sensing at the gripper/fingers or whole-body contact sensing to capture fine contact events.
- Missing audio: contact-rich tasks often benefit from audio; unlike some prior datasets, no audio is included to complement FT and vision during contact events.
- Action representation constraints: actions are joint-space absolute commands (with relative option) tied to HSR’s kinematics; no torque-level commands or impedance parameters are available for learning force-compliant behaviors.
- Base control realism: base actions are interface-derived increments without absolute ground truth; no wheel odometry, velocity profiles, or motion-primitive annotations to enable accurate base motion replay or analysis.
- Annotation reliability: the process for creating and validating primitive-action boundaries and success/failure labels (e.g., guidelines, annotator training, inter-rater agreement) is not reported; label consistency is unknown.
- Failure taxonomy and granularity: while failures (~6.6%) are flagged and causes “documented,” a structured, standardized taxonomy and its availability/consistency in the release are unclear; no contact-event markers (touch onset/offset) are provided.
- Evaluation protocols: no standard train/val/test splits, scene- or operator-holdout splits, or leaderboards/metrics for hierarchical or recovery behaviors are defined, limiting comparability across methods.
- Hierarchical learning utility: the paper does not demonstrate baselines showing that the two-layer annotations (SHT/PA) improve planning/control, leaving open how best to exploit these labels architecturally and algorithmically.
- Operator-induced bias: 18 teleoperators with a specialized leader–follower interface may induce particular motion styles or biases; the impact of operator variability and interface design on learned policies is unquantified.
- Generalization across objects/appliances: the diversity of object instances (brands/models of coffee machines, ovens, lamps) is not quantified; it is unclear how well policies would transfer to unseen instances or mechanisms.
- Dataset imbalance: the long-tail skew toward common primitives (“grab,” “open,” “place”) is noted but not mitigated; no sampling strategies or reweighting protocols are provided for training on imbalanced skills.
- Multi-view limitations: only head and wrist RGB are included (no fixed external views); this constrains multi-view reconstruction, third-person supervision, and cross-view consistency checks.
- Temporal integrity and missingness: although stale frames are marked, the frequency and patterns of missing samples are not quantified; no per-episode diagnostics are provided to filter or weight episodes by data quality.
- Reproducibility of synchronization: original raw ROS bag streams are not stated as released; without raw data, users cannot apply alternative synchronization/resampling or recover higher-rate signals.
- Perception annotations: no object poses, detections, segmentations, or affordance labels are included, limiting supervised perception tasks and evaluation of perception–control pipelines.
- Safety and compliance metadata: no labels for risky contacts, near-collisions, or safety margin violations; no controller gains/compliance parameters to study safety-aware or compliant control learning.
- Language supervision scope: while SHTs are natural-language labeled, there are no spoken instructions, dialogues, or dense language narrations to support instruction following, grounding, or interactive correction.
- Domain randomization details: randomness in lighting, placements, and initial poses is stated but not quantified; lacks protocols to systematically vary and log environmental factors for controlled generalization studies.
- Image compression/quality: details of video encoding parameters (compression, bitrate) are not provided; potential effects on visual feature learning are unknown.
- Licensing/consent and privacy residuals: YOLO-based person filtering thresholds may still produce false negatives; residual privacy risk and audit outcomes are not reported, nor are per-frame person-detection labels released for downstream filtering.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released dataset, open-source pipeline, and standard tooling.
- Train and benchmark VLA policies for contact-rich mobile manipulation
- Sectors: robotics, software/AI; academia
- What: Fine-tune and evaluate RT-1, OpenVLA, π₀, and other imitation learning/VLA models on household, contact-rich tasks (e.g., “Make coffee,” “Turn on lamp,” “Hang towel”) using the LeRobot v2.1-standardized dataset.
- Tools/workflows: Hugging Face dataset (airoa-org/airoa-moma), LeRobot v2.1 loaders, ROSbag-derived episodes, GPU training pipelines, success/failure metrics.
- Assumptions/dependencies: Access to compute; a compatible robot (HSR or similar) for deployment; models that support multimodal inputs (RGB, proprioception, force–torque).
- Force–torque–aware manipulation controllers for switches, doors, and contact-rich interactions
- Sectors: robotics; software/AI
- What: Use synchronized 6-axis wrist force–torque data to design/refine contact controllers for pressing, pulling, inserting, and sliding actions.
- Tools/workflows: Policy learning with F/T features, impedance control parameter tuning, contact event detection, supervised/regression baselines.
- Assumptions/dependencies: Availability of a wrist F/T sensor (or equivalent tactile sensing) on target robot; accurate time synchronization.
- Hierarchical imitation learning and curriculum design from SHT–PA annotations
- Sectors: academia; robotics
- What: Train hierarchical policies where Short Horizon Tasks (SHTs) are decomposed into Primitive Actions (PAs), enabling modular skill learning and composition.
- Tools/workflows: Hierarchical IL/RL frameworks; per-PA segmentation; task graphs; curriculum schedules prioritizing frequent primitives (“grab,” “open,” “place”).
- Assumptions/dependencies: Reliable PA segmentation boundaries; dataset’s long-tail skill distribution; short-to-medium duration episodes.
- Failure prediction and error detection modules
- Sectors: robotics; software/AI; academia
- What: Build anomaly detectors and failure predictors using the 6.6% explicitly labeled failure cases and causes (e.g., misalignment, grasp errors).
- Tools/workflows: Per-PA risk models, temporal anomaly detection, sensor-fusion features (RGB + F/T + proprioception).
- Assumptions/dependencies: Balanced training strategies for imbalanced failure data; clear mapping from signals to failure modes.
- Reliability dashboards and evaluation suites for mobile manipulation
- Sectors: academia; policy/standards; robotics
- What: Create per-task and per-PA success/failure dashboards to compare models, track regressions, and quantify robustness on contact-rich tasks.
- Tools/workflows: Benchmark scripts; hierarchical metrics; reproducible LeRobot-format validation; episode-level and segment-level analytics.
- Assumptions/dependencies: Consistent annotation use; agreed-upon evaluation protocols.
- Immediate prototyping of service robots for simple household or facility tasks
- Sectors: facility management; hospitality; smart home
- What: Deploy learned policies for lamp control, towel hanging, and basic placement in labs, demo homes, or hotels.
- Tools/workflows: Fine-tuned policies on HSR or similar platforms; safety wrappers; constrained operational procedures.
- Assumptions/dependencies: Controlled environments similar to the dataset; human supervision; compliance with safety and liability requirements.
- Action representation studies (absolute vs. relative joint actions; base increments)
- Sectors: academia; robotics
- What: Compare control performance under different action spaces provided by the dataset (absolute joint commands, deltas, base motion increments).
- Tools/workflows: Ablation experiments; policy learning across action encodings; analysis of odometry limitations.
- Assumptions/dependencies: Awareness of dataset constraints (no absolute base odometry; base represented by relative increments).
- Adopt the open-source processing pipeline and LeRobot standardization
- Sectors: software/AI; academia; robotics labs
- What: Reuse synchronization, filtering, packaging, and LeRobot conversion for existing ROSbag collections to ensure reproducible datasets.
- Tools/workflows: AIRoA MoMa pipeline; LeRobot v2.1 conversion; automated resampling; stale-frame handling.
- Assumptions/dependencies: ROSbag availability; adherence to sensor naming/time conventions.
- Replicate the THSR leader–follower teleoperation system for safe data collection and operator training
- Sectors: robotics; education; manufacturing
- What: Build the 1:1 joint-mapped leader–follower device (Dynamixel-based, 3D-printed parts) to efficiently collect high-quality manipulation data and train operators.
- Tools/workflows: BOM (servos, constant force springs, belt drives), Joy-Con for base/head control, ROS integration, gravity compensation software.
- Assumptions/dependencies: Basic mechatronics capability; safety practices; calibration to target robot embodiment.
- Privacy filtering practices for robotics datasets
- Sectors: policy/compliance; software/AI; academia
- What: Apply YOLO-based person detectors with tunable thresholds to automatically exclude episodes with significant human appearance, aligning with privacy requirements.
- Tools/workflows: YOLO detectors; threshold tuning; alternative VLM-based curation; audit trails.
- Assumptions/dependencies: Detector performance; local privacy policy compliance; acceptance of detector metrics.
- Robotics education and coursework using a realistic household manipulation dataset
- Sectors: education; academia
- What: Design assignments on hierarchical learning, sensor fusion, and error analysis using public data and standard loaders.
- Tools/workflows: Hugging Face dataset, LeRobot APIs, Jupyter notebooks; project-based labs.
- Assumptions/dependencies: Compute access; institutional licensing; adherence to dataset terms.
Long-Term Applications
The following applications require further research, scaling, cross-embodiment generalization, or broader ecosystem development.
- General-purpose home assistant robots for long-horizon, contact-rich tasks (e.g., make coffee, wash dishes)
- Sectors: healthcare/elder care; home services; assistive robotics
- What: End-to-end autonomous agents that plan hierarchies, execute robust contact interactions, and recover from errors in diverse homes.
- Tools/workflows: Multimodal VLA models incorporating F/T, hierarchical planning, robust navigation and perception; safety monitors.
- Assumptions/dependencies: Larger, more diverse data across homes; improved base localization/odometry; comprehensive safety and HRI protocols.
- Cross-embodiment transfer learning to varied mobile manipulators
- Sectors: robotics; manufacturing
- What: Train foundation models that generalize AIRoA MoMa skills to different robot platforms beyond HSR.
- Tools/workflows: Domain adaptation; calibration-aware embeddings; cross-robot datasets (OXE-style); embodiment-conditioned policies.
- Assumptions/dependencies: Multi-robot datasets; standardized actuation/sensing interfaces; cross-institution coordination.
- Autonomous error recovery, retry strategies, and failure-aware planning
- Sectors: robotics; software/AI
- What: Learn recovery behaviors and conditional plans triggered by failure states detected at the PA level.
- Tools/workflows: Failure-conditioned policy learning; model predictive recovery; counterfactual planning; demonstration of recovery episodes.
- Assumptions/dependencies: Additional data focused on recovery behaviors; reliable failure classifiers; safe exploration.
- Regulatory benchmarks and certification frameworks using per-PA reliability metrics
- Sectors: policy/regulation; insurance; standards bodies
- What: Establish standardized metrics, test suites, and reporting protocols for contact-rich mobile manipulation reliability.
- Tools/workflows: Hierarchical success/failure metrics; third-party audits; reproducible datasets and test procedures.
- Assumptions/dependencies: Consensus among regulators and industry; broader, standardized datasets; liability and safety frameworks.
- Skill libraries and “task graph” marketplaces for smart homes and facilities
- Sectors: software/IoT; smart buildings; robotics
- What: Publish reusable PA modules and SHT compositions as interoperable skills that can be orchestrated by home/facility management systems.
- Tools/workflows: APIs for skill invocation; graph-based planners; device/robot interoperability layers; safety permissions.
- Assumptions/dependencies: Vendor-neutral standards; integration with smart devices; robust verification tools.
- Teleoperation-as-a-Service (TaaS) and data-engine platforms
- Sectors: robotics/cloud; operations
- What: Scale THSR-like systems for remote operation and continuous data collection to bootstrap and refresh robot skill datasets.
- Tools/workflows: Cloud teleoperation infrastructure; operator training pipelines; automated packaging and QA; privacy-aware curation.
- Assumptions/dependencies: Reliable low-latency connectivity; safety oversight; workforce scaling; compliance with local regulations.
- Next-generation multimodal VLA architectures that integrate force–torque, audio, and speech
- Sectors: academia; software/AI; robotics
- What: Models that fuse additional sensors (planned in future releases) to improve semantic understanding and physical grounding for household tasks.
- Tools/workflows: Unified multimodal encoders; self-supervised contact representations; language-conditioned manipulation.
- Assumptions/dependencies: Expanded dataset modalities (audio/speech); hardware upgrades; annotation protocols for HRI.
- High-fidelity sim-to-real pipelines for contact-rich manipulation
- Sectors: robotics; software/AI
- What: Use AIRoA MoMa to calibrate simulation contact models and domain randomization strategies that transfer reliably to real robots.
- Tools/workflows: Physics-based simulation with F/T modeling; dataset-driven sim parameter fitting; sim-to-real benchmarks.
- Assumptions/dependencies: Accurate contact simulation; paired sim–real datasets; tooling for F/T realism.
- Privacy and data governance standards for robotic datasets
- Sectors: policy/compliance; academia; industry consortia
- What: Formalize detector-based metrics, thresholds, and auditing practices to govern person-related content in robot perception data.
- Tools/workflows: Benchmark suites for person detection in robotics contexts; policy templates; compliance testing.
- Assumptions/dependencies: Community acceptance of metrics; alignment with regional laws; scalable tooling.
- Hospital logistics and patient assistance robots
- Sectors: healthcare; facility operations
- What: Extend contact-rich mobile manipulation to hospital settings (e.g., opening doors, handling containers, operating switches) with strict safety and hygiene constraints.
- Tools/workflows: VLA policies adapted to medical environments; sterile component design; HRI protocols.
- Assumptions/dependencies: Clinical trials; regulatory approval (e.g., IEC/ISO standards); extensive environment-specific datasets.
- Integrated home automation–robot orchestration
- Sectors: IoT; smart home; consumer robotics
- What: Combine robot skills with smart devices (lighting, appliances) for end-to-end task fulfillment beyond pure manipulation.
- Tools/workflows: Orchestration platforms; device APIs; context-aware planners; fail-safe handoffs.
- Assumptions/dependencies: Device ecosystem integration; reliability and security guarantees; user consent frameworks.
- Risk modeling for deployment economics and insurance underwriting
- Sectors: finance/insurance; corporate R&D
- What: Leverage hierarchical success/failure statistics to model operational risk, MTBF, and ROI for large-scale robot deployment.
- Tools/workflows: Reliability modeling; cost–benefit analysis; scenario simulations; actuarial integration.
- Assumptions/dependencies: Larger, multi-site datasets; standardized reporting; acceptance by insurers/regulators.
Glossary
- Bimanual manipulation: Coordinated use of two robotic arms to perform tasks. "Mobile ALOHA integrates mobility and bimanual manipulation capabilities to autonomously execute complex household tasks."
- Contact-rich interactions: Tasks requiring deliberate physical contact and force feedback beyond vision (e.g., pressing, pulling, opening). "they rarely capture contact-rich interactions (e.g., pressing switches, opening doors)"
- Cross-embodiment learning: Transfer of skills or models across different robot bodies or platforms. "showing positive transfer in cross-embodiment learning."
- Degrees of Freedom (DoF): The number of independent joint or motion axes a robot mechanism can control. "a 4-DOF manipulator on a lifting torso, 1-DoF hand, 2-DoF head, and 3-DoF omnidirectional mobile base"
- Distribution shifts: Changes between training and deployment data distributions that can degrade performance. "lack robustness to distribution shifts in real-world settings."
- End-effector: The robot arm’s tool/gripper that interacts with objects. "the 6-DOF position and orientation of the end-effector"
- Force-torque: Measurement of forces and torques (often six-axis) for contact feedback. "six-axis wrist force-torque signals"
- Hierarchical annotation: Multi-level labeling of data (e.g., tasks and sub-tasks) to support structured learning. "hierarchical annotations covering seven primary tasks and more than 40 sub-tasks."
- Imitation learning: Learning control policies from demonstrations rather than explicit programming. "existing imitation learning methods"
- Inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "enabling intuitive control without the need for inverse kinematics (IK) calculations."
- Leader-follower (teleoperation): A setup where a master device’s joint motions are mirrored by the robot. "The leader-follower teleoperation system used for data collection."
- LeRobot v2.1: A standardized dataset format for robotics used in the open-source community. "fully standardized in the LeRobot v2.1 format."
- Long-horizon tasks: Multi-step activities requiring extended sequences of actions and planning. "contact-rich and long-horizon tasks"
- Mobile manipulation: Integration of navigation and manipulation using a mobile base and arm(s). "It is designed for mobile manipulation in household settings"
- Odometry: Estimation of a robot’s motion (position and orientation change) from onboard sensors. "due to the limited accuracy of robot odometry."
- Omnidirectional (mobile base): A base capable of moving in any planar direction and rotating in place. "3-DoF omnidirectional mobile base"
- Open X-Embodiment (OXE): A large aggregated repository of robot datasets across institutions. "Open X-Embodiment~\cite{oxe2023}"
- Primitive Action (PA): An atomic, semantically coherent operation segment within a task. "Primitive Action (PA): A low-level command representing an atomic, semantically coherent segment."
- Proportional control: A control mode where command magnitude scales with the error or deviation. "a proportional control mode based on the angular deviation between the THSR and the HSR."
- Proprioception: Sensing of a robot’s internal states (e.g., joint angles, velocities). "dual-view RGB, proprioception, and synchronized wrist force-torque signals."
- ROSbag: A ROS file format for recording and replaying time-synchronized sensor and control data. "recorded in the ROSbag format (a standard data logging format in ROS)."
- Short Horizon Task (SHT): A high-level instruction describing an overall goal for a short, discrete activity. "Short Horizon Task (SHT): A high-level natural language instruction that defines the overall goal, e.g., ``Bake a toast.''"
- Teleoperation: Direct human control of a robot to execute tasks. "Human teleoperation is an effective approach for efficiently collecting such complex behavioral data"
- Vision-Language-Action (VLA) models: Models that map language and perception to robotic actions. "Vision-Language-Action (VLA) models have recently emerged as a promising paradigm toward this goal,"
- Vision-LLMs (VLMs): Models jointly trained on images and text for multimodal understanding. "incorporating web-scale pretraining through VLMs enhances generalization over semantic and visual concepts"
- YOLO-based detector: An object detector from the YOLO family used for automated frame filtering. "we adopted the YOLO-based detector"
- Zero-shot generalization: Performing novel tasks without task-specific training examples. "zero-shot generalization to novel tasks, environments, and objects."
Collections
Sign up for free to add this paper to one or more collections.

