MOPD: Multi-Teacher On-Policy Distillation for Capability Integration in LLM Post-Training
Abstract: Modern LLMs rely on reinforcement learning during post-training to push specific capabilities, yet integrating multiple capabilities into one model remains hard. Existing methods, such as Off-Policy Finetune and Mix-RL, are either inefficient or lose performance. In this work, we propose Multi-teacher On-Policy Distillation (MOPD), a post-training paradigm for combining the capabilities of multiple domain RL teachers: we first run per-domain specialised RL to obtain a set of domain teachers, then distill these teachers into the student on its own rollouts. This eliminates exposure bias and provides a dense optimization signal. On Qwen3-30B-A3B, MOPD outperforms Mix-RL, Cascade RL, Off-Policy Finetune, and Param-Merge baselines, inheriting nearly all of each teacher's capability. MOPD also enables parallel, independent development of domain teachers, removing the cross-domain coupling typical of multi-domain post-training. MOPD has been deployed in the post-training of MiMo-V2-Flash, an industrial-scale frontier model, demonstrating its practical value for capability integration in frontier-scale LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is about teaching one big AI model to be good at many different things at once—like math, writing, and coding—without forgetting or weakening any of those skills. The authors introduce a new training method called MOPD (Multi-Teacher On-Policy Distillation) that combines the strengths of several specialized “teacher” models into a single “student” model in a stable, efficient way.
What questions the paper tries to answer
The paper focuses on a simple question: How can we build one LLM that’s strong across many areas (math, instruction following, coding, tool use) without:
- mixing signals so the model improves in one area but gets worse in another,
- training on the wrong kind of examples and learning bad habits, or
- ending up with unstable models when we try to merge different skills together?
How the method works (explained simply)
Think of this like school:
- You have different teachers for different subjects—one for math, one for writing, one for coding. Each teacher trains a separate expert model in their own subject using reinforcement learning (RL), which is like practicing lots of tasks and getting rewards for good answers.
- You then have one student model that needs to learn all subjects well.
MOPD teaches the student in three stages:
- Stage 1: General practice (SFT). The student gets a broad, basic training across subjects—like completing a good foundation year.
- Stage 2: Specialist teachers (RL). Each subject teacher trains their own expert model from that same foundation, becoming great at just that subject (a math expert, a coding expert, etc.).
- Stage 3: Multi-teacher distillation (MOPD). The student practices by answering its own questions (not copying from a dataset). For each question, the matching subject teacher looks at the student’s answer and gives detailed, token-by-token hints—like a coach giving feedback on every word. The student adjusts to match the teacher’s guidance where it matters for that subject.
Why this is smart:
- “Practice like you play.” Because the student trains on its own answers, it avoids “exposure bias”—a problem where a model only learns from perfect examples and then gets lost when it makes mistakes at test time.
- Feedback at every step. Teachers give a probability for each next word, so the student gets dense, detailed guidance—not just a thumbs-up or thumbs-down at the end.
- Stable skill mixing. Instead of smashing teacher models together (which can be unstable), MOPD routes each prompt to the right teacher and learns in the “policy space” (how the model behaves), which is much steadier.
- Parallel progress. Each subject teacher can be developed independently by different teams at the same time, then merged later without redoing everything.
A helpful analogy: The student writes an essay (or solves a problem) in its own words. Then the correct teacher (math, writing, or coding) reads it and says, “Here’s how likely I think each next word should be,” effectively guiding the student step by step.
What they found and why it matters
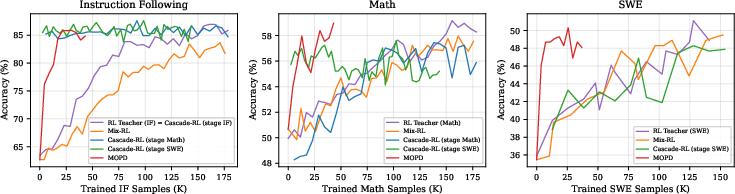
On a 30B-parameter model (Qwen3-30B-A3B), MOPD beat several popular ways of combining skills:
- Mix-RL (training everything together),
- Cascade RL (training skills one after another),
- Off-Policy Finetune (learning from teacher-generated answers),
- Parameter merging (averaging or combining model weights).
Key takeaways:
- MOPD kept more of each subject teacher’s strength than the other methods and was about 5.5 points better on a “normalized score” that fairly compares across tasks. In plain terms: it learned all subjects more evenly and strongly.
- It was more sample-efficient—meaning it learned faster—because it got rich, per-word feedback instead of sparse final rewards.
- It scales to giant models. They used MOPD on an industrial-scale model (MiMo-V2-Flash) and matched or beat the teachers on most tests—showing this is practical in real, large systems.
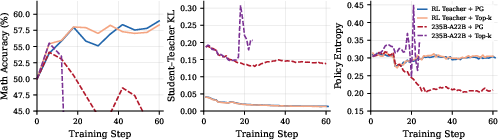
- Two technical notes that matter for stability and reliability:
- Both ways of giving feedback (policy-gradient and “top‑k” token feedback) worked similarly when the teacher and student came from the same base model.
- Using a much bigger but different teacher (one that doesn’t “speak” like the student) actually hurt training. The best results came when teachers and student started from the same foundation—so they already “think” in similar ways.
- You can repeat the process in rounds: after one MOPD pass, use the improved student to train better teachers, then distill again. This boosted performance further.
Why this is useful (impact and implications)
- For developers: Teams can build math, coding, writing, and tool-use skills separately, then plug them together later with MOPD—saving time and reducing risk.
- For reliability: Because MOPD teaches the student on its own behavior with detailed, per-word guidance, the resulting model is more stable and consistent across tasks.
- For future models: This gives a practical path to build generalist AI systems that combine many advanced abilities without the usual trade-offs.
In short, MOPD is like having top teachers coach a single student in their own subjects while the student practices in realistic conditions—leading to a well-rounded, dependable model that performs strongly across many skills.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Routing assumptions and multi-skill prompts
- The method assumes a correct domain label per prompt and routes to a single teacher; there is no learned router, robustness to misrouting, or handling of prompts requiring multiple capabilities simultaneously (e.g., math-in-code, tool-use within IF). How to design and evaluate automatic routing (prompt-level or token-level) and mixture-of-teachers gating remains open.
- Combining multiple teachers within a single trajectory
- MOPD dispatches each rollout to one domain teacher; it does not explore per-token/per-span teacher blending, arbitration when teachers disagree, or hierarchical/mixture-of-experts distillation that dynamically fuses teacher signals within a single completion.
- Stability with external or heterogeneous teachers
- The paper shows that stronger but distributionally different external teachers can destabilize training; there is no mitigation strategy. Open questions include how to safely leverage external/heterogeneous teachers (different sizes, architectures, tokenizers) via techniques like:
- teacher-side temperature smoothing or calibration,
- intermediate “bridging” SFT/alignments,
- trust-region constraints to a reference policy,
- staged KL annealing, partial off-policy warmup, or multi-critic shaping.
- Sensitivity to k and bias correction in top‑k distillation
- The proposed top‑k objective adds an extra correction term but lacks a formal proof or ablation on its necessity and sensitivity. Effects of k, temperature, truncation thresholds, and teacher logit calibration (and their interactions with stability and quality) are not studied.
- Hyperparameter robustness and optimization choices
- Two-sided advantage clipping is used without ablation; there’s no study of stability vs. A_max, entropy regularization, learning rates, or batch sizes. Guidance on hyperparameter ranges for different domains and scales is missing.
- Scaling to many domains and long sequences
- Experiments integrate 3 domains at 30B and 5 domains at frontier scale; scalability to larger sets (e.g., 10–20+ domains), to longer-context settings, and to high-latency teachers is untested. How teacher prefill latency and bandwidth scale with domain count, sequence length, and top‑k payload is not quantified.
- System performance and cost characterization
- Claims that teacher prefill adds “nearly no measurable overhead” are not backed by quantitative measurements. There is no report of wall-clock time, GPU hours, throughput, or energy use vs. baselines (Mix‑RL, Cascade RL), nor breakdown of sampling vs. teacher service time across sequence lengths.
- Robustness to weak or noisy teachers
- MOPD assumes strong, reliable domain teachers; the impact of low-quality, biased, or noisy teachers on the student is unexamined. Methods for down-weighting, filtering, or adaptively trusting teachers (e.g., confidence-weighted distillation) are left open.
- Curriculum, data mixing, and domain weighting
- The multi-domain sampling/mixing schedule, domain weights, and curricula are unspecified and unanalyzed. How sampling strategies influence convergence, fairness across domains, and edge-case performance (rare domains) remains an open design space.
- Continual and incremental integration
- Beyond a single follow-up round, the long-term dynamics of repeated teacher–student co-evolution (convergence, oscillation, catastrophic forgetting, or compute blow-up) are not characterized. Criteria for when to retrain teachers, stop distillation, or rebalance domains are absent.
- Ceiling relative to teachers and surpassing them
- MOPD typically approaches but does not consistently exceed each teacher; mechanisms to surpass individual teachers by exploiting cross-domain complementarities (e.g., joint consistency training, cross-teacher contrastive signals) are unexplored.
- Generalization and out-of-domain effects
- The effect of MOPD on capabilities not covered by teachers (or on broader general-purpose tasks) is not evaluated. Potential regressions in unseen domains or open-world generalization are unassessed.
- Safety, alignment, and bias
- No measurements of safety, toxicity, factuality, or bias transfer from teachers. Whether on-policy distillation amplifies teacher biases or degrades safety guardrails is unknown.
- Interactive/agentic settings and tool use
- While teachers may be trained in agent sandboxes, Stage‑3 distillation is only demonstrated on static text rollouts. How to conduct on-policy distillation in interactive environments (with tools, web browsing, or multi-step plans) and how to route/score intermediate tool calls are unaddressed.
- Tokenization and architecture compatibility
- The approach presumes same-origin teachers (shared initialization and tokenizer). Integration across different tokenizers or architectures is fragile and not studied; methods for vocabulary alignment or representation bridging remain to be developed.
- Theoretical analysis and guarantees
- There is no formal analysis of stability conditions for on-policy reverse‑KL distillation (e.g., bounds in terms of initial teacher–student KL, entropy, or curvature), nor guarantees on convergence or sample complexity relative to RL baselines.
- Evaluation breadth and methodology
- Benchmarks are limited (e.g., AIME25/26, IFBench/IFEval, SWE‑bench Verified; a few more on MiMo). There is no human evaluation, long-form quality assessment, or broader task coverage (multilingual, multimodal, retrieval-augmented tasks). Sensitivity to decoding strategy during training vs. inference is not reported.
- Fault tolerance and distributed reliability
- The paper assumes teacher services are reliable; failure modes (stragglers, timeouts, stale responses) and their impact on optimization bias and throughput are not considered. Strategies for caching, batching, or fallback behaviors are unexamined.
- Data and compute transparency
- Details on Stage‑3 dataset composition, domain balance, sequence lengths, and exact compute budgets are not provided in the main text; reproducibility and cost–quality trade-offs remain unclear.
Practical Applications
Immediate Applications
The following applications can be deployed with current methods and infrastructure described in the paper (policy-gradient or top-k MOPD, teacher-as-service prefill, parallel teacher training), assuming access to per-domain RL pipelines and an SFT base model.
- Unified, multi-capability LLM releases without see-saw regressions
- Sectors: software/AI, consumer assistants, enterprise SaaS
- What: Fuse domain specialists (math, code, instruction following, tool use) into a single general model with minimal capability loss versus teachers, avoiding cross-domain interference common in Mix-RL or Cascade RL.
- Tools/workflows: “Capability Hub” (versioned registry of domain teachers), “Integration Engine” (MOPD trainer plugin in PPO/GRPO stacks), nightly CI that runs MOPD and domain regressions, model cards tracking per-domain normalized scores.
- Assumptions/dependencies: Teachers must be trained from the same SFT checkpoint (same-origin) for stability; labeled domain routing for training batches; compute for parallel teacher RL and student distillation.
- Parallel domain team post-training to accelerate time-to-capability
- Sectors: software/AI R&D, model labs
- What: Independent teams iterate on domain-specific RL pipelines (rewards, sandboxes) concurrently; MOPD decouples integration into a fast, stable pass.
- Tools/workflows: Isolated RL pipelines per domain (e.g., verifiable-answer RL for math, executable-sandbox RL for SWE), shared SFT baseline, per-domain monitoring dashboards, asynchronous teacher prefill services.
- Assumptions/dependencies: Organizational coordination around a shared SFT baseline; robust RL infra per domain; versioning of teachers to resolve conflicts.
- Cost and sample-efficiency improvements in RL post-training
- Sectors: AI infrastructure, cloud/compute management
- What: Replace late-stage mixed-domain RL with dense, per-token distillation on the student’s own rollouts; overlapping teacher prefill with sampling hides wall-clock overhead.
- Tools/workflows: Teacher-as-a-Service (prefill microservices returning per-token log-probs or top-k logits), GRPO/PPO trainers with MOPD advantage function, sampling-first schedulers.
- Assumptions/dependencies: Reliable, low-latency RPC between sampler and teacher services; token log-prob caching; observability for KL/entropy to detect drift.
- Safer model integration via dedicated safety/alignment teachers
- Sectors: policy/safety, trust & safety teams, regulated industries
- What: Train specialized safety teachers (refusal behaviors, jailbreak resistance, PHI handling) and integrate them without degrading other capabilities.
- Tools/workflows: Safety RLVR pipelines (rubrics, red-team datasets), per-domain safety evals integrated in CI, safety teacher prefill service gated by safety-domain routing.
- Assumptions/dependencies: High-quality, coverage-rich safety rewards/datasets; domain tags for safety prompts; same-origin safety teachers.
- Enterprise vertical integration (single internal model with multiple domain experts)
- Sectors: finance (analysis + report drafting), telecom (tool orchestration), e-commerce (catalog QA + content generation)
- What: Combine in-house RL teachers (e.g., SQL/code agents, compliance writing, pricing math) into a single model for internal workflows.
- Tools/workflows: Internal teacher registry keyed by business domain, MOPD integration pipeline, per-vertical regression suites, access controls for sensitive data.
- Assumptions/dependencies: Domain data governance; internal sandbox/reward environments; same-origin teachers initialized from the enterprise SFT checkpoint.
- Reliable agent stacks that blend search, code execution, and reasoning
- Sectors: software agents, RAG/search, developer tools
- What: Integrate web-search RL teachers, coding RL teachers, and math RL teachers into a robust general agent backbone for research, coding, and troubleshooting agents.
- Tools/workflows: Domain routers for agent prompts during training, web/sandbox evaluators, capability-weighted sampling schedules, on-policy distillation monitoring.
- Assumptions/dependencies: Stable web/env simulators; compatible tool APIs across teacher training and student deployment; same-origin teachers.
- Iterative capability releases via multi-round student–teacher evolution
- Sectors: software/AI productization
- What: After a first MOPD, retrain domain teachers from the improved student and run a second MOPD to push headroom further; ship measured capability increments with low regression risk.
- Tools/workflows: “Co-evolution Scheduler” (automates next-round teacher training and integration), per-domain headroom tracking (normalized scores), gated rollout.
- Assumptions/dependencies: Additional compute budgets; domain evals sensitive enough to detect incremental gains; careful KL/entropy guardrails.
- Academic consolidation of specialized open models
- Sectors: academia, open-source
- What: Labs produce per-domain RL teachers (from the same open SFT) and integrate them into one research model for broad benchmarks (math, SWE-bench, IFBench).
- Tools/workflows: Open RLVR recipes per domain, reproducible MOPD scripts, release of teacher checkpoints and integration logs, unit tests on per-domain normalized scores.
- Assumptions/dependencies: Licensing compatibility; alignment on a shared SFT base; compute access for parallel teacher training.
- Better end-user assistants that balance math, coding, and writing
- Sectors: daily life, education, productivity apps
- What: Assistants that solve math problems, generate code snippets, and follow complex instructions without degrading one skill when improving another.
- Tools/workflows: App vendors integrate MOPD-trained backends; telemetry to segment domain usage and route training data; periodic MOPD updates to keep balance.
- Assumptions/dependencies: Access to domain-labeled interactions for continued training; privacy-preserving telemetry; compatibility between app UX and model updates.
Long-Term Applications
These require further research, scaling, or ecosystem development beyond the current paper’s validated settings.
- Cross-architecture and small-model integration (edge and on-device)
- Sectors: mobile/embedded AI, consumer electronics
- What: Distill capabilities from multiple large teachers into smaller students for edge deployment while preserving stability and breadth.
- Potential tools/products: “Edge-MOPD” with curriculum temperature schedules and KL guards; progressive-width/quantization-aware MOPD.
- Assumptions/dependencies: Methods to mitigate teacher–student distribution gaps (since same-origin constraint is harder across sizes/architectures); efficient on-device sampling and prefill emulation.
- Federated or third-party capability marketplaces
- Sectors: platform ecosystems, AI marketplaces
- What: External vendors supply domain teachers (e.g., legal reasoning, biomedical QA) that can be integrated via MOPD into a platform’s base model.
- Potential tools/products: Standardized Teacher API (top-k logits schema, metadata on domain/entropy/KL), reputation/eval leaderboards, cryptographic audit trails for teacher provenance.
- Assumptions/dependencies: Robust solutions to distribution shift (external teachers will often be off-origin); governance, licensing, and privacy controls; interoperability standards.
- Continual/streaming MOPD for always-on capability refresh
- Sectors: AI operations, data-centric AI
- What: Run MOPD as a continuous background process that integrates refreshed domain teachers on a rolling basis, maintaining capability under domain drift.
- Potential tools/products: Streaming sampler with drift detection, online KL/entropy safety bounds, rollback mechanisms, dynamic sampling curricula per domain.
- Assumptions/dependencies: Strong eval suites for early drift detection; scalable prefill services; catastrophic forgetting mitigations.
- Multimodal capability integration
- Sectors: vision-language, speech, robotics
- What: Train per-modality/per-domain teachers (e.g., VQA, chart reasoning, audio transcription) and integrate them into a single multimodal model using MOPD-style on-policy distillation.
- Potential tools/products: Multimodal teacher-prefill services returning per-token/logit distributions across modalities; cross-modal routing and batching.
- Assumptions/dependencies: Efficient prefill for multimodal teachers; synchronized tokenization/time-alignment; modality-aware KL objectives.
- Robotics and embodied agents
- Sectors: robotics, autonomous systems
- What: Integrate teachers for task planning, tool control, code synthesis for controllers, and safety constraints into a single policy backbone for instruction-following robots.
- Potential tools/products: Simulator-integrated RL pipelines per skill, safety constraint teachers, MOPD over trajectories combining language plans and action tokens.
- Assumptions/dependencies: High-fidelity simulators and verifiable rewards; safe sim-to-real transfer; low-latency inference for control loops.
- Regulated domains (healthcare, legal, public sector)
- Sectors: healthcare, law, government services
- What: Combine specialized teachers for clinical reasoning, guideline adherence, de-identification, and documentation into one compliant model.
- Potential tools/products: Governance dashboards tracing per-domain teacher versions, audit logs of MOPD integrations, domain-specific safety gates.
- Assumptions/dependencies: Rigorous validation (prospective trials, bias/safety audits), privacy-preserving RL data; regulatory approvals; strong guarantees against capability regressions.
- Privacy-preserving or secure MOPD
- Sectors: privacy/security, cross-org collaboration
- What: Enable teacher prefill across organizations without revealing full model distributions or data (e.g., secure enclaves, MPC, or differential privacy on logits).
- Potential tools/products: Secure Teacher-as-a-Service with encrypted top-k logits, DP-aware distillation objectives, compliance toolkits.
- Assumptions/dependencies: Practical secure computation at token-level throughput; calibrated privacy–utility trade-offs; legal frameworks for cross-boundary compute.
- Automated domain routing and capability diagnostics
- Sectors: AI tooling, evaluation
- What: Learn or infer domain routing during training and create automated diagnostics to surface underperforming domains before user-facing regressions.
- Potential tools/products: Router classifiers trained on latent features, per-domain KL/entropy monitors, active data collection loops targeting weak domains.
- Assumptions/dependencies: Reliable signal for domain inference; robust per-domain metrics; guardrails against router-induced biases.
- Standard-setting and procurement guidance for public bodies
- Sectors: policy, public procurement
- What: Encourage on-policy integration methods (like MOPD) in RFPs to reduce exposure bias and capability regressions in procured models; require per-domain normalized reporting.
- Potential tools/products: Compliance checklists, audit templates, capability-balance scorecards.
- Assumptions/dependencies: Consensus on evaluation standards; transparency from vendors on training setups; third-party auditing capacity.
Cross-cutting assumptions and dependencies to watch
- Same-origin requirement: For stability, teachers should be fine-tuned via RL from the same SFT checkpoint as the student; large distribution gaps can destabilize training.
- Domain routing: Training data must be reliably tagged by domain for correct teacher dispatch; automated routers need careful validation.
- Compute and infra: Parallel RL per domain plus student sampling require significant compute; low-latency teacher prefill services are critical for throughput.
- Reward availability: Each domain needs an effective RL recipe (verifiable rewards, sandboxed execution, or rubrics); domains lacking robust rewards may lag.
- Monitoring and safety: Track reverse-KL, entropy, and per-domain accuracy to preempt collapse; integrate safety evals alongside capability evals.
- Licensing and data governance: Ensure SFT and teacher checkpoints are license-compatible; protect sensitive domain data in RL pipelines.
Glossary
- Advantage (RL): A baseline-corrected signal that weights policy-gradient updates, indicating how much better a chosen token/action is than expected. "with the teacher–student log-difference acting as a per-token advantage:"
- Agent-style RL: Reinforcement learning where the model acts as an agent interacting with tools/environments (e.g., code execution), often in sandboxes. "software engineering with agent-style RL in executable sandboxes"
- Capability integration: The process of combining multiple specialized abilities (from different domains/teachers) into a single model. "capability integration is realised in policy space"
- Cascade RL: A sequential multi-domain RL strategy where domains are trained one after another, risking interference and forgetting. "Cascade RL trains domains sequentially, so earlier-stage capabilities may decay as later stages progress"
- Dense optimization: Training driven by frequent, fine-grained signals (e.g., per-token distributions) rather than sparse trajectory rewards. "provides a dense optimization signal."
- Exposure bias: The training–inference mismatch that occurs when a model is trained on fixed data/teacher outputs but must generate its own during inference. "this off-policy supervision induces the canonical exposure bias"
- Forward KL: The Kullback–Leibler divergence D_KL(teacher || student), often used in off-policy distillation on fixed teacher outputs. "Classical distillation minimises a forward KL on a fixed corpus of teacher completions and is thus off-policy,"
- GRPO: A PPO-style reinforcement learning variant used in verifiable-reward pipelines for reasoning tasks. "GRPO-style outcome-reward optimization has become standard practice."
- Mix-RL: Joint RL that mixes prompts from different domains into one training set, which can cause cross-domain interference. "Mix-RL pools prompts from every domain into one dataset and runs joint RL, but cross-domain training signals interfere, producing the see-saw effect"
- Model merging: Combining checkpoints directly in parameter space to produce a fused model without further training. "Model merging fuses multiple model checkpoints in weight space to obtain a combined model without additional training."
- Model Soups: A merging method that averages weights of independently fine-tuned models sharing the same initialization. "Model Soups averages the weights of independently fine-tuned models from the same initialisation."
- MOPD: Multi-teacher On-Policy Distillation; the paper’s proposed method that distills multiple domain teachers into a single student on its own rollouts. "we propose Multi-teacher On-Policy Distillation (MOPD), a post-training paradigm that performs multi-teacher capability integration directly in policy space,"
- Normalised score: An evaluation metric that rescales each domain by the student–teacher headroom to enable fair cross-domain aggregation. "MOPD leads the strongest baseline by $5.5$ points on the normalised score"
- Off-Policy Finetune: Post-training that imitates teacher rollouts via supervised fine-tuning, using data not sampled from the current student policy. "Off-Policy Finetune trains per-domain RL teachers and then fine-tunes the student on their rollouts via SFT"
- On-policy distillation: Distillation where supervision comes from teachers evaluated on the student’s own generated trajectories. "Then the capabilities of these teachers are distilled into a single student model via on-policy distillation"
- Param-Merge: A weight-space fusion approach that averages teacher parameters or composes task vectors to combine capabilities. "Param-Merge averages teacher weights or composes task vectors in weight space"
- Policy entropy: The entropy of the model’s action/token distribution, indicating uncertainty or diversity of the policy. "policy entropy remains stable around $0.30$ throughout."
- Policy gradient: An RL optimization method that updates parameters via gradients of log-probabilities weighted by an advantage signal. "which is exactly the policy-gradient form,"
- Policy space: The space of action/token distributions defined by a model, as opposed to parameter space; integration is done by aligning behaviors. "perform multi-teacher capability integration directly in policy space,"
- Prefill: Running a model forward over a given trajectory to compute per-token probabilities/logits without generating new tokens. "the teacher prefills on the trajectory to obtain its per-token probability distribution"
- PPO: Proximal Policy Optimization, a popular on-policy RL algorithm for stabilizing policy updates. "PPO-style and GRPO-style outcome-reward optimization has become standard practice."
- Reverse KL: The Kullback–Leibler divergence D_KL(student || teacher), promoting alignment on the student’s visited states and often used for on-policy distillation. "per-token reverse KL between the student and the domain teacher"
- Rollout distribution: The distribution over states/trajectories induced by the student’s own sampling process during training/inference. "the student's own rollout distribution"
- Routing (per-prompt): Sending each prompt to the appropriate domain teacher for supervision based on its task domain. "per-prompt routing"
- RLVR: Reinforcement Learning with Verifiable Rewards, where rewards can be automatically checked (e.g., math answer correctness). "reinforcement learning with verifiable rewards (RLVR),"
- Same-origin teachers: Teachers initialized from the same SFT checkpoint as the student, ensuring close distributional alignment and stable optimization. "same-origin teachers are critical for stable optimization,"
- See-saw effect: A phenomenon where improving one task degrades another due to interference in joint training. "producing the see-saw effect"
- Task arithmetic: Weight-space composition of capabilities by adding/subtracting task vectors derived from fine-tuning. "Task arithmetic composes capabilities by adding and subtracting task vectors in weight space,"
- Task vectors: Parameter differences representing task-specific adaptations that can be added or subtracted to compose capabilities. "task vectors in weight space"
- Teacher-as-reward: Using a teacher model’s scores or preferences as a reward signal within an RL framework. "teacher-as-reward variants"
- Top-k distillation: Distillation that matches the teacher on only its top-k tokens per position to reduce variance and bandwidth. "Top- distillation is comparable on Math and slightly worse on IF and SWE;"
- Trajectory-level reward: A scalar reward assigned to an entire generated sequence, as in standard RL, contrasted with dense per-token signals. "This is far denser than the trajectory-level reward used in standard RL,"
- Verifiable-answer RL: RL recipes where task outputs (e.g., math answers) can be automatically verified to give accurate rewards. "verifiable-answer RL for math"
- Web-environment RL: Training agents that interact with web browsers/search engines as part of the environment. "web-environment RL"
- Weight-space fusion: Combining models by operating directly on parameters (e.g., averaging or task arithmetic), as opposed to policy-space integration. "weight-space fusion,"
Collections
Sign up for free to add this paper to one or more collections.